1.为什么要有GC
没有GC的世界,我们需要手动进行内存管理,但是内存管理是纯技术活,又容易出错。但是我们写码的目的是为了解决业务问题,所以可以把这种纯技术活自动化,当然自动化也是有代价的。
2.垃圾定义
把分配到堆中那些不能通过程序引用的对象称为非活动对象,也就是死掉的对象,称为垃圾
3.GC定义
我们想让内存管理变得自动化,就必须实现两件事(1)找到内存里的垃圾 (2)回收垃圾,让这块空间可以重新使用
4.常说的分代垃圾回收
经验:大部分的对象在生成之后马上就变成了垃圾,很有有对象能活的很久,分代垃圾回收利用该经验,引入了年龄的概念,经历过一次GC之后活下来的对象年龄为1岁。
分代:分代垃圾回收把对象分类成几代,针对不同的代使用不同的GCC算法,我们把刚生成的对象成为新生带对象,到达一定年龄的对象称为老年代对象。
为什么分代:将对象根据存活概率进行分类,对存活时间长的对象,可以减少扫描垃圾的时间,以及GC的频率和时长,本质:对对象进行分类,针对各个分类进行不同的垃圾回收算法,以对各算法扬长避短。
5.分代垃圾的堆结构
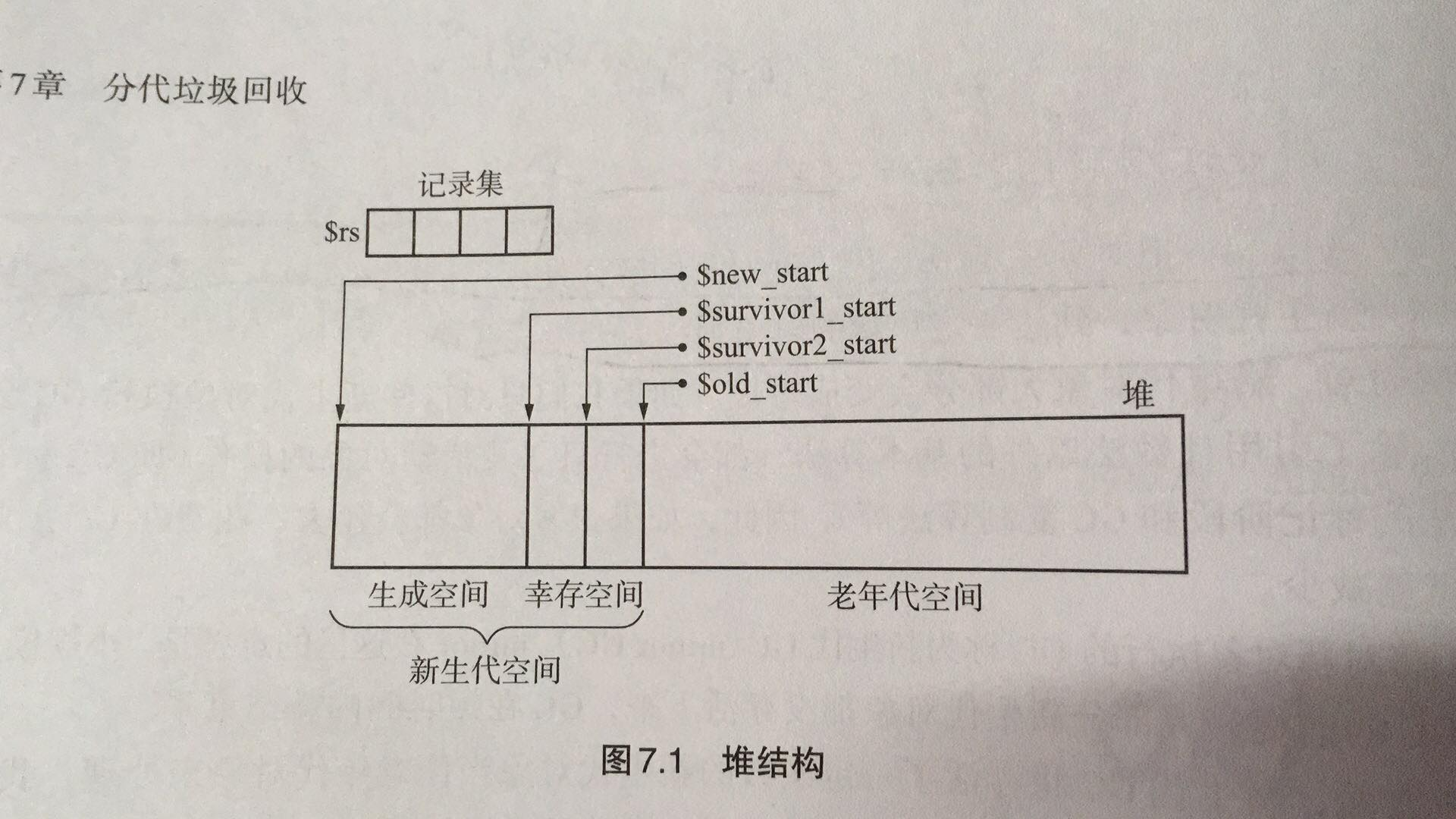
问题1:为什么新生代分成生成空间和幸存空间?
想要回答上面的问题,就要知道JVM分代垃圾回收常用的GC算法复制算法。
1.将内存分均分成A、B两块内存
2.新生对象分配到A块中未使用的内存当中,当A块的内存使用完了,把A块的存活对象复制到B块
3.清理A块的所有对象
4.当B中的内存也用完了,就把存活对象全都复制到A块中
5.清理B块所有对象
6.不断循环
这个算法优点:简单高效,缺点:内存代价高,有效内存为占用内存的一半,所以我们进行优化。
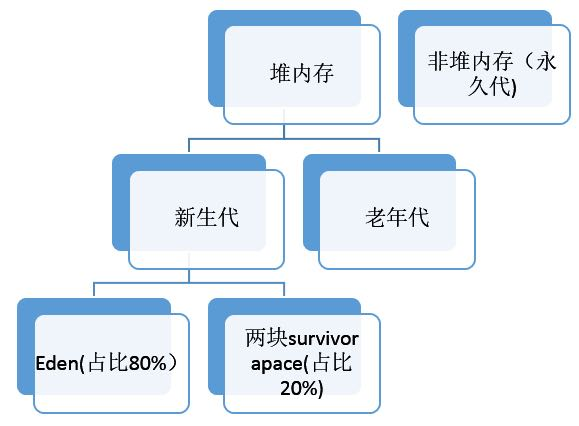
优化后的GC算法:使用Eden和S0,S1三个分区,均分A/B块太浪费内存,空间比例在8:1:1,有效内存(可分配新生对象的内存)在总内存的9/10。
1.Eden+S0可以分配新生对象
2.对Eden+S0进行垃圾收集,把存活对象复制到S1,清理Eden+S0,一次新生代GC结束
3.Eden+S1可以分配新生对象
4.对Eden+S1进行垃圾收集,存活对象复制到S0,清理Eden+S1,二次新生代GC结束
5.不断循环
问题2:为什么要有survivor区?
如果没有suivivor区,Eden区没进行一次Minor C,存活对象就被送到老年代,老年代很快被填满,出发Major GC(一般Major GC会伴随着Minor GC,相当于出发了Full GC),老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC要长得多,这就消耗很多资源。
获取你可以想出一些办法来解决没有survivor区?
| 方案 | 优点 | 缺点 |
| 增加老年代空间 | 更多存活对象才能填满老年代。降低Full GC频率 | 随着老年代空间加大,一旦发生Full GC,执行所需要的时间更长 |
| 减少老年代空间 | Full GC所需时间减少 | 老年代很快被存活对象填满,Full GC频率增加 |
问题3:为什么幸存空间分成两块大小相等的幸存空间1,2?也就是为什么suivivor区要分成两个?
原因是为了解决碎片化。分析如下:
假设:我们现在只有一个survivor区,模拟GC过程,下面的图更加形象化内存碎片的产生。
1.新建对象放在Eden中
2.Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区
3.新建对象放在Eden中
4.Eden满了,此时Eden和Survivor区各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象占用的内存是不连续的,这就导致了内存碎片化。
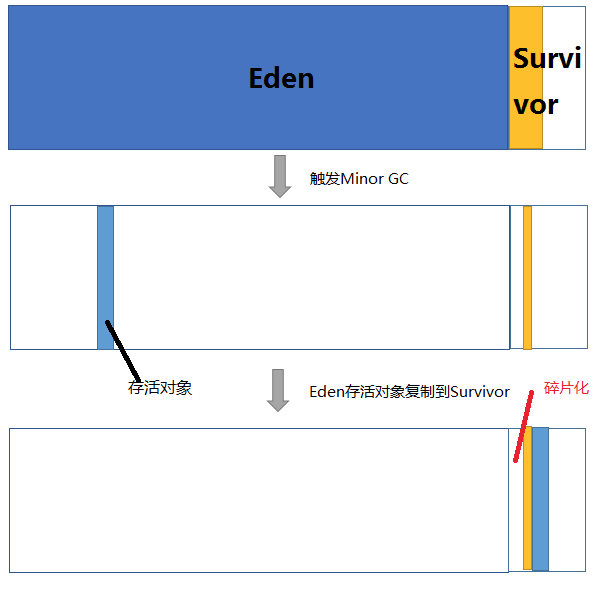
可能你还想说,碎片化就碎片化呗,能有多大影响?
内存碎片化风险很大,严重影响java程序的性能,堆空间被散布的对象占据不连续的内存,最直接的结果就是堆中没有足够大的连续内存空间,接下去如果程序需要为一个内存很大的对象分配空间,那就尴尬了。就像背包里所有东西都紧挨着放,这样就可能腾出一片空间放水杯,如果隔一点缝隙放一个,那么估计你的水杯就要拎着了。
所以顺理成章,应该建立两块Suivivor区,而且在执行上述GC复制算法的时候,Eden和S0活动对象复制到S1,清理S0和EDEN,之后在Eden和S1上分配对象,从而避免了内存碎片化。
6.GC算法共同解决的问题和衡量标准?想看专业深入的GC算法详解请看下次分解
问题:
如何分别出垃圾?
如何,何时搜索垃圾?
如何何时清理垃圾
标准:
吞吐量:单位时间内处理能力
最大暂停时间:GC执行过程中,应用暂停的时长
堆的使用率:堆空间的利用率,可用的堆越大,GC越快
访问的局部性:把具有引用关系的对象安排在堆中较近的位置,就能提高在缓存中读取到想利用的数据的概率。