准备
- 需要准备多台主机(已经安装并且配置好hadoop和jdk)
- 需要配置ssh免密服务
下面我们开始进行配置,拿到已经准备好的主机,主机名分别为:
- centos101
- centos102
- centos103
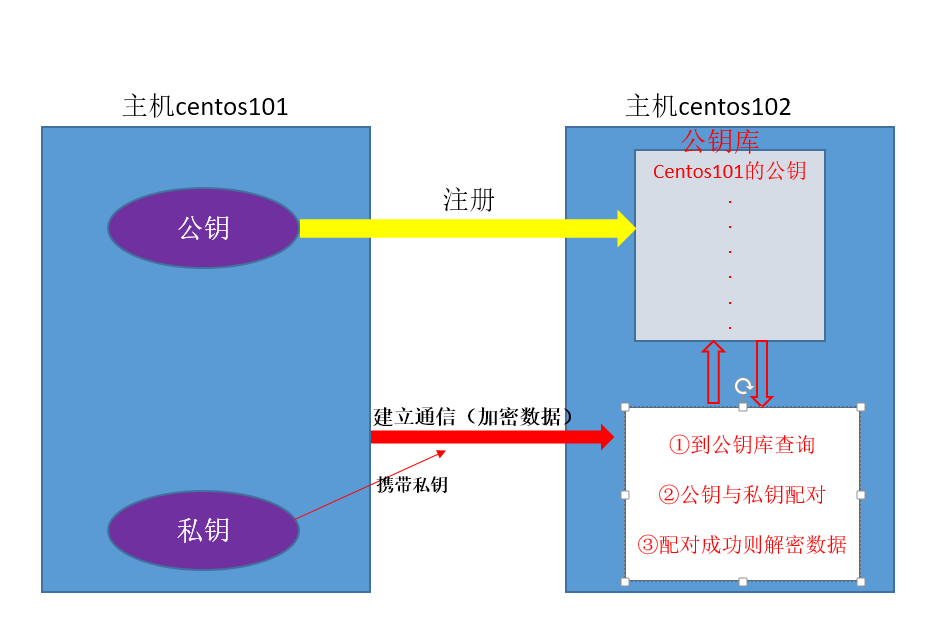
先说下为什么需要进行ssh免密码配置:
我们在操作集群时,经常需要在各台主机上进行数据传输、主机切换等工作,如果直接进行切换等操作需要每次输入密码,当操作频繁
时,就显得很复杂,所以需要配置ssh免密码,让主机间自动检验账号密码。
主机间进行ssh通信的原理图
配置ssh免密
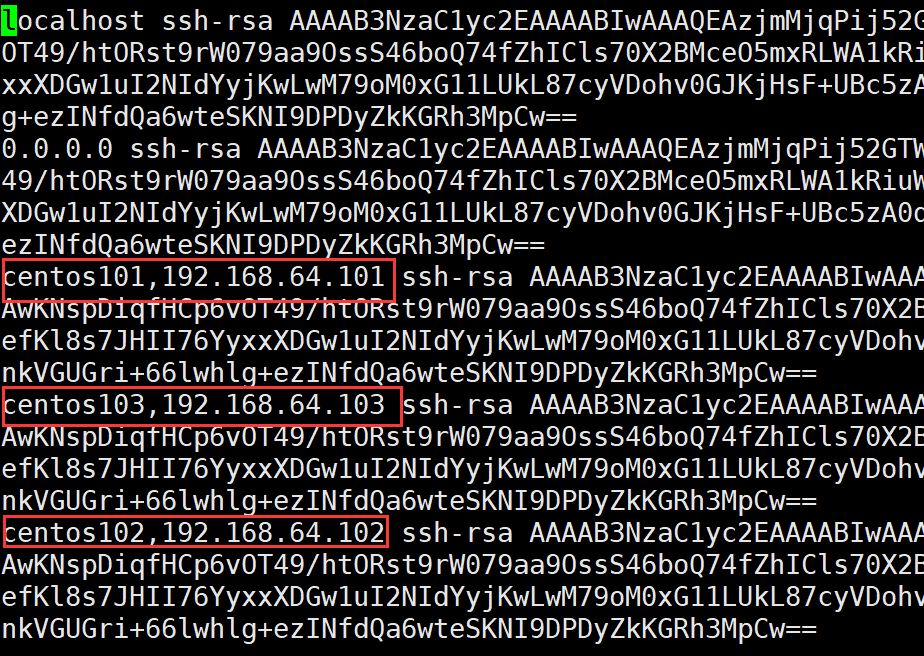
①在主机centos101上访问其它主机,保证有访问记录,访问记录存在 /home/ljm/.ssh下的known_hosts文件中
用命令:ssh 主机 访问过的记录都在该文件中
②生成密钥,产生本台主机的公钥和私钥
命令:ssh-keygen -t rsa , 一直回车 生成了三个新文件
- authorized_keys:保存已经注册过的主机(即把公钥备份到本机的其它主机)
- id_rsa :私钥
- id_rsa.pub : 公钥

③将公钥复制到其它主机,复制时按照known_hosts中访问记录进行自动复制,复制后保存在其他主机的authorized_keys文件中
命令: ssh-copy-id 主机
以下是centos103主机的authorized_keys文件,可以看出centos101和centos102对它注册过
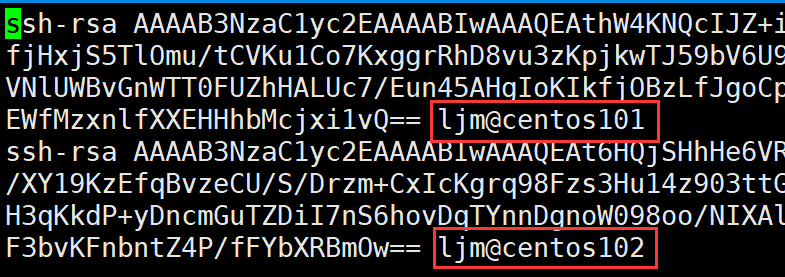
到这里已经完成了centos101对centos102和cenot103的免密配置了
注意:
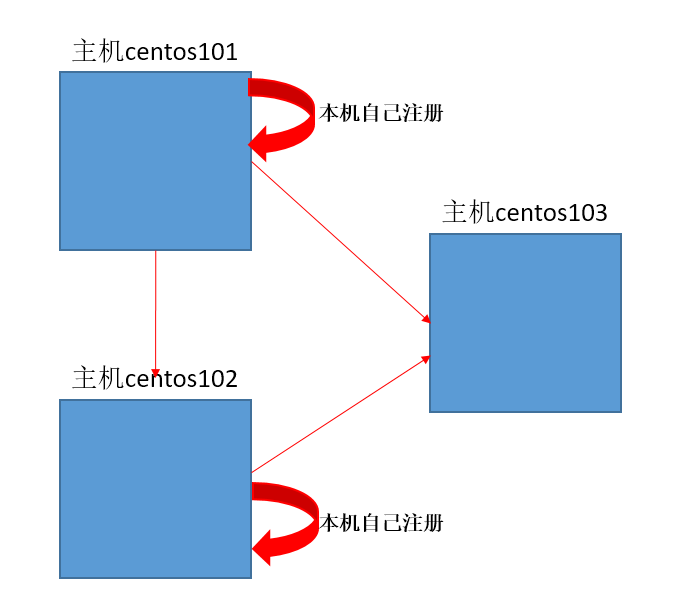
①本主机也要对本主机注册,简单说,就是哪里需要免密就配置到哪里
②同一台主机上的不同用户配置不同(如user用户配置了ssh免密,root用户并没有权利使用它的配置)
③两台主机间只要一方往另一方配置了,双方便可以相互免密访问
我三台主机的ssh配置结构如下:
配置hadoop集群
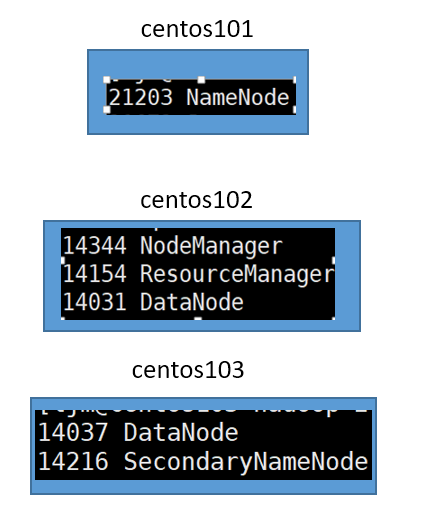
我的集群结构图:
基本配置文件(这些配置在hadoop根目录/etc/hadoop下):
- core-site.xml配置
- HDFS配置(hadoop-env.sh hdfs-site.xml slaves)
- YARN配置 (yarn-env.sh yarn-site.xml)
- MapReduce配置(mapred-env.sh mapred-site.xml)
①配置core-site.xml
每台主机都需要配置该文件,内容如下:
1 <configuration> 2 <!-- 指定HDFS中NameNode的地址 --> 3 <property> 4 <name>fs.defaultFS</name> 5 <value>hdfs://centos101:8020</value> 6 </property> 7 8 <!-- 指定hadoop运行时产生文件的存储目录 --> 9 <property> 10 <name>hadoop.tmp.dir</name> 11 <value>/opt/module/hadoop-2.7.2/data/tmp</value> //缓存目录 12 </property> 13 </configuration>
②HDFS配置
每台主机都配置 hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置hdfs-site.xml,其它主机清空<configuration></configuration>中内容
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>centos103:50090</value> </property> </configuration>
只有主机centos101配置slaves,该文件默认localhost,centos101中slaves指定生成子节点datanode的主机
注意:格式要求严格,有空格都会导致出错
centos102
centos103
③YARN配置
每台主机都配置 yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置yarn-site.xml,其它主机清空<configuration></configuration>中内容
注意:yarn.resourcemanager.hostname指的是生成resourcemanager的节点主机,启动resourcemanager时必须在指定的主机启动
例如下面的配置,只能在主机centos102上启动resourcemanager
<configuration> <!-- Site specific YARN configuration properties --> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>centos102</value> </property> </configuration>
④MapReduce的配置
每台主机都配置 mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置mapred-site.xml,其它主机清空<configuration></configuration>中内容
注意:mapred-site.xml并没有,需要将mapred-site-template.xml改为mapred-site.xml再进行配置
<!--指定mr运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
到这里,一个简单的集群已经配置好了,下面去启动集群吧!
启动集群
①将每台主机上的缓存文件夹和logs文件删除,我的配置中为 : /opt/module/hadoop-2.7.2/data/tmp
②初始化主节点centos101,命令:bin/hdfs namenode -format
③主节点上开启HDFS 命令:sbin/start-dfs.sh
④在指定生成resourcemanager的节点主机上,开启YARN 命令: sbin/start-yarn.sh
⑤用jps到每台主机上查看是否启动成功