压缩列表
redis为了节约内存空间使用,zset和hash容器对象在元素个数较少的时候,采用压缩列表(zipList)进行存储,压缩列表是一块连续的内存空间,元素之间挨着存储,没有任何冗余空隙。
127.0.0.1:6379> zadd programmings 1.0 go 2.0 java 3.0 python
(integer) 3
127.0.0.1:6379> debug object programmings
Value at:0x7fb20fa071e0 refcount:1 encoding:ziplist serializedlength:36 lru:12015574 lru_seconds_idle:15
127.0.0.1:6379> hmset books go a python b java c
OK
127.0.0.1:6379> debug object books
Value at:0x7fb20fa06770 refcount:1 encoding:ziplist serializedlength:39 lru:12015628 lru_seconds_idle:18
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,恒为0xFF
}
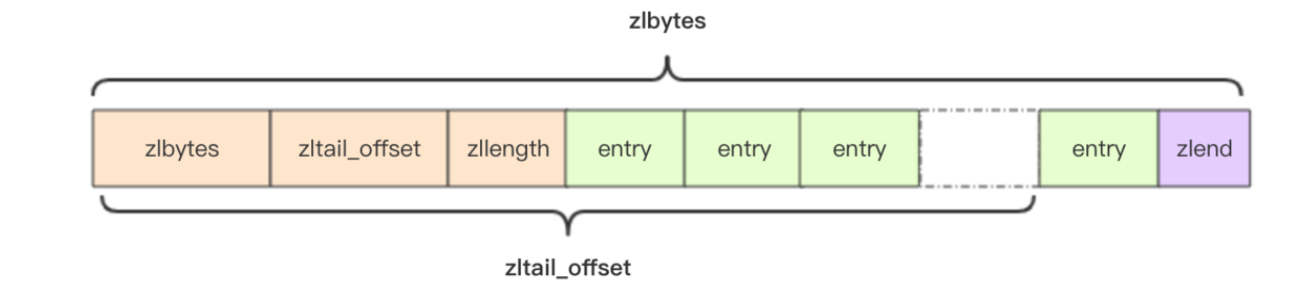
压缩列表为了支持双向遍历,所以用ztail_offset字段,快速定位到最后一个,然后倒着遍历。
entry块随着容纳的元素类型不同,也会有不一样的结构。
struct entry{
int<var> prevlen; // 前一个entry的字节长度
int<var> encoding; // 元素类型编码
optional byte[] content; // 元素内容
}
它的 prevlen 字段表示前一个 entry 的字节长度,当压缩列表倒着遍历时,需要通过这 个字段来快速定位到下一个元素的位置。它是一个变长的整数,当字符串长度小于 254(0xFE) 时,使用一个字节表示;如果达到或超出 254(0xFE) 那就使用 5 个字节来表 示。第一个字节是 0xFE(254),剩余四个字节表示字符串长度。你可能会觉得用 5 个字节来 表示字符串长度,是不是太浪费了。我们可以算一下,当字符串长度比较长的时候,其实 5 个字节也只占用了不到(5/(254+5))<2%的空间。
encoding 字段存储了元素内容的编码类型信息,ziplist 通过这个字段来决定后面的 content 内容的形式。
1、00xxxxxx 最大长度位 63 的短字符串,后面的 6 个位存储字符串的位数,剩余的字 节就是字符串的内容。
2、01xxxxxx xxxxxxxx 中等长度的字符串,后面 14 个位来表示字符串的长度,剩余的 字节就是字符串的内容。
3、10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd 特大字符串,需要使用额外 4 个字节 来表示长度。第一个字节前缀是 10,剩余 6 位没有使用,统一置为零。后面跟着字符串内 容。不过这样的大字符串是没有机会使用的,压缩列表通常只是用来存储小数据的。
4、11000000 表示 int16,后跟两个字节表示整数。
5、11010000 表示 int32,后跟四个字节表示整数。
6、11100000 表示 int64,后跟八个字节表示整数。
7、11110000 表示 int24,后跟三个字节表示整数。
8、11111110 表示 int8,后跟一个字节表示整数。
9、11111111 表示 ziplist 的结束,也就是 zlend 的值 0xFF。
10、1111xxxx 表示极小整数,xxxx 的范围只能是 (0001~1101), 也就是 1~13,因为
0000、1110、1111 都被占用了。读取到的 value 需要将 xxxx 减 1,也就是整数 0~12 就是 最终的 value。
注意到 content 字段在结构体中定义为 optional 类型,表示这个字段是可选的,对于很 小的整数而言,它的内容已经内联到 encoding 字段的尾部了。
增加元素
因为 ziplist 都是紧凑存储,没有冗余空间 (对比一下 Redis 的字符串结构)。意味着插 入一个新的元素就需要调用 realloc 扩展内存。取决于内存分配器算法和当前的 ziplist 内存 大小,realloc 可能会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址,也可 能在原有的地址上进行扩展,这时就不需要进行旧内容的内存拷贝。
如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
级联更新
前面提到每个 entry 都会有一个 prevlen 字段存储前一个 entry 的长度。如果内容小于 254 字节,prevlen 用 1 字节存储,否则就是 5 字节。这意味着如果某个 entry 经过了修改 操作从 253 字节变成了 254 字节,那么它的下一个 entry 的 prevlen 字段就要更新,从 1 个字节扩展到 5 个字节;如果这个 entry 的长度本来也是 253 字节,那么后面 entry 的 prevlen 字段还得继续更新。
如果 ziplist 里面每个 entry 恰好都存储了 253 字节的内容,那么第一个 entry 内容的 修改就会导致后续所有 entry 的级联更新,这就是一个比较耗费计算资源的操作。
快速列表
redis早期版本存储list列表数据结构使用的是压缩列表ziplist和普通的双向链表linkedList,也就是元素少的时候用ziplist,多的时候用linkedList。
// 链表的节点
struct listNode<T> {
listNode* prev;
listNode* next;
T value
}
// 链表
struct list {
listNode *head;
listNode *tail;
long length;
}
链表的prev和next指针就要占去16个字节,另外每个节点的内存都是单独分配,加剧内存的碎片化,影响内存管理效率。后来使用quickList代替ziplist和linkedList
127.0.0.1:6379> rpush li_test go java python
(integer) 3
127.0.0.1:6379> debug object li_test
Value at:0x7fc328405bf0 refcount:1 encoding:quicklist serializedlength:31 lru:12103071
lru_seconds_idle:8 ql_nodes:1 ql_avg_node:3.00 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:29
quickList是zipList和linkedList混合体,他将linkedList按段切分,每一段使用ziplist让存储紧凑,多个zipList之间使用双向指针串接起来。
struct ziplist{...}
struct ziplist_compressed{
int32 size;
byte[] compresses_data;
}
struct quicklistNode {
quicklistNode* prev;
quicklistNode* next;
ziplist* zl; // 指向压缩列表
int32 size; // ziplist的字节总数
int16 count; // ziplist的元素数量
int2 encoding // 存储形式2bit
...
}
struct quickList {
quicklistNode* head;
quicklistNode* tail;
long count; // 元素总数
int nodes; // ziplist节点的个数
int compressDepth // L2F算法深度
}
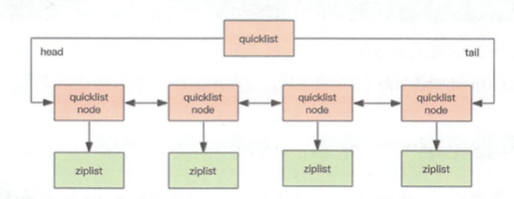
上述就是quick的大致结构,为了进一步节约空间,redis还会对ziplist进行压缩存储,使用LZF算法压缩,可以选择压缩深度。
每个ziplist存多少元素
quickList内部默认单个ziplist长度为8kb,超出了这个字节数,就会另起一个ziplist,ziplist长度由配置参数list-max-ziplist-size决定。
压缩深度
quicklist默认的压缩深度为0,就是不压缩,为了支持快速的push/pop操作,quicklist的首尾两个ziplist不压缩,因此压缩深度1。如果首尾前两个都不压缩,那么压缩深度就是2。
跳跃列表
基本结构
redis的跳跃列表共有64层,每一个kv块对应的结构如下面的代码中zslnode结构,kv header也是这个结构,只不过value字段是NULL值无效的,score是Double.MIN_VALUE,用来垫底的。kv之间使用指针串起来形成了双向链表结构,他们是有序排列的,从小到大,不同的kv层高可能不一样,层数越高的kv越少,同一层的kv会使用指针串起来。每一层元素的遍历都是从kv header出发。
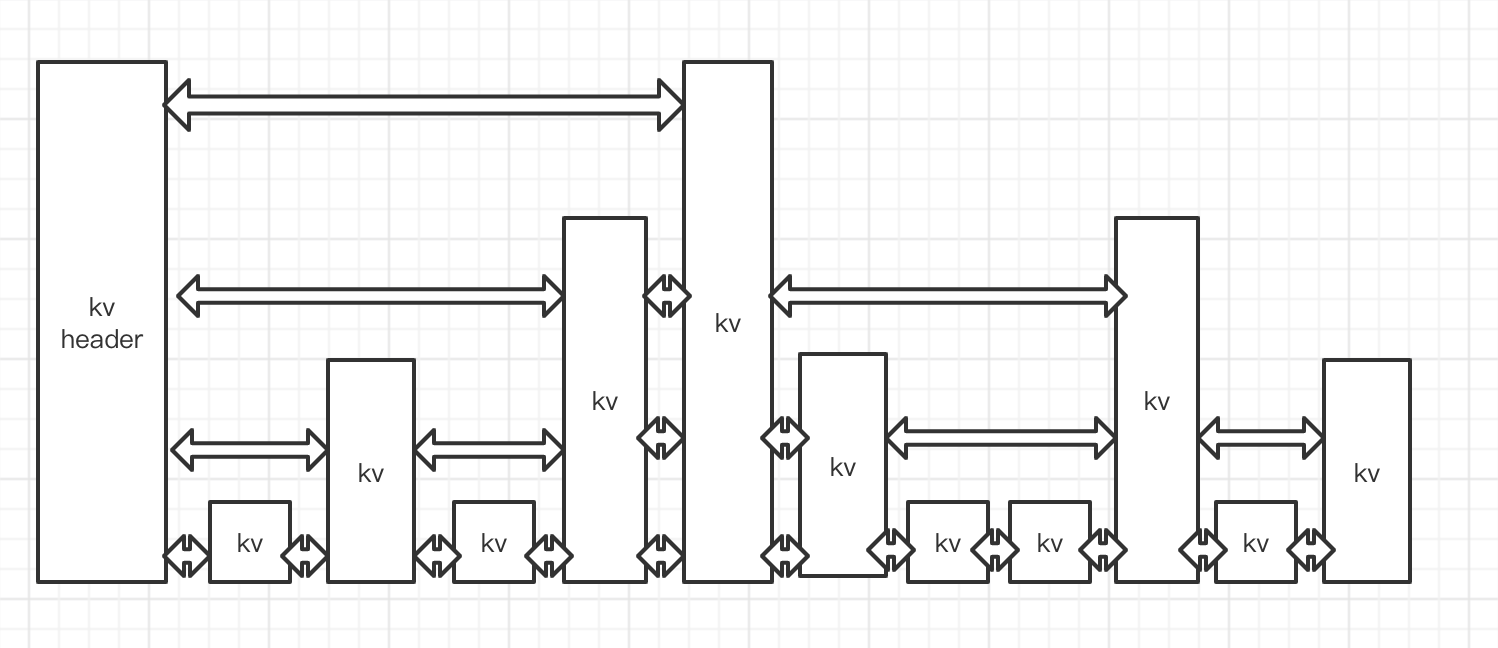
struct zslnode {
string value;
double score;
zslnode*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
struct zsl {
zslnode* header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map<String,zslnode*> // hash结构的所有键值对
}
查找过程
设想如果跳跃列表只有一层,插入,删除需要定位到相应的位置节点。需要逐个遍历。时间复杂度On。
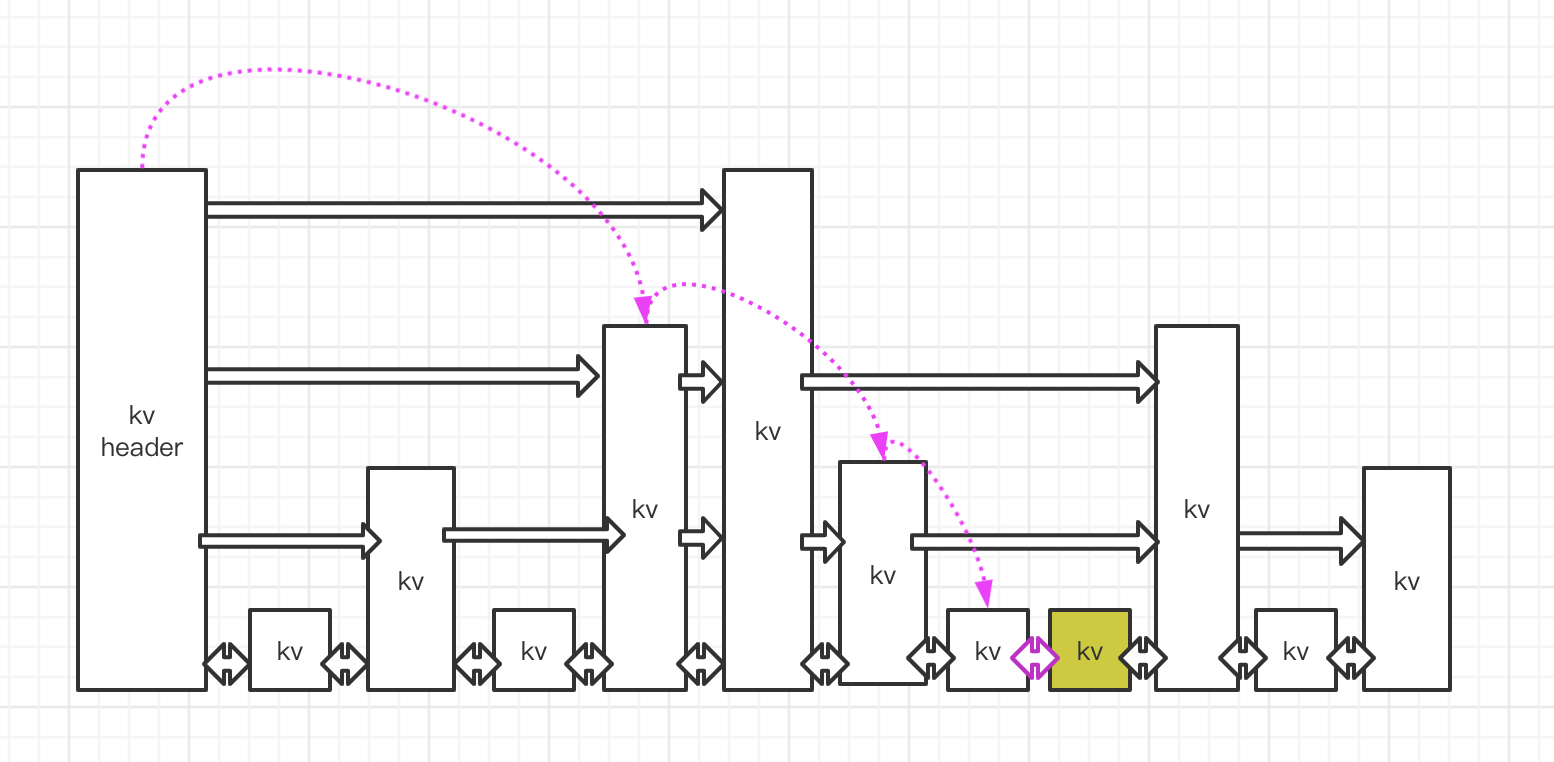
我们要定位到那个紫色的 kv,需要从 header 的最高层开始遍历 找到第一个节点(最后一个比“我”小的元素),然后从这个节点开始降一层再遍 历找到第二个节点(最后一个比“我”小的元素),然后一直降到最底层进行遍历 就找到了期望的节点(最底层的最后一个比我“小”的元素)。
我们将中间经过的一系列节点称之为“搜索路径”,它是从最高层一直到最底 层的每一层最后一个比“我”小的元素节点列表。 有了这个搜索路径,我们就可以插入这个新节点了。不过这个插λ过程也不是 特别简单。因为新插人的节点到底有多少层,得有个算法来分配一下,跳跃列表使 用的是随机算法。
随机层数
对于每一个新插入的节点,都需要调用一个随机算法给它分配一个合理的层数,直观上期望的目标是 50% 的概率被分配到 Levell, 25% 的概率被分配到 Level2, 12.5% 的概率被分配到 Level3,以此类推, 2*10^-63 的概率被分配到最顶层,因为这里每 一层的晋升率是 50%。
redis标准代码中晋升率为25%,意味着更加扁平化,层高相对较低,遍历的时候从顶层开始往下遍历会非常浪费,跳跃列表会记录当前最高层数maxLevel,遍历时从这个maxlevel开始遍历,性能会提高很多。
元素排名
redis在skiplist的forward指针上进行了优化,给每一个forward指针都增加了span属性,表示从前一个节点沿着当前层的forward指针跳到当前这个节点,中间会跳过多少个节点,redis在插入,删除时都会更新span大小
struct zslnode {
string value;
double score;
zslforward*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
struct zslforward {
zslnode* item;
long span;
}
这样当我们计算一个元素排名时,只需要将搜索路径经过的所有节点跨度span叠加,就可以获取最终的rank值。
插入过程
首先我们在搜索合适插入点的过程中将“搜索路径”找出来,然后就可以开始 创建新节点。创建的时候需要给这个节点随机分配一个层数,再将搜索路径上的节 点和这个新节点通过前向后向指针串起来。如果分配的新节点的高度高于当前跳跃 列表的最大高度,就需要更新一下跳跃列表的最大高度。
删除过程
删除过程和插入过程类似,都需先把这个“搜索路径”找出来,然后对于每个层的相关节点重排一下前向后向指针,同时还要注意更新一下最高层数 maxLevel。
更新过程
当我们调用 zadd 方法时,如果对应的 value 不存在,那就是插入过程。如果这个 value 已经存在了,只是调整一下 score 的值, 那就需要走一个更新流程。假设这个新 的 score 值不会带来排序上的改变,那么就不需要调整位置 , 直接修改元素的 score 值 就可以了。但是如果排序位置改变了,那就要调整位置。那么该如何调整位置呢?
一个简单的策略就是先删除这个元素,再插入这个元素,需要经过两次路径搜 索。 Redis就是这么干的。不过 Redis遇到 score值改变了的情况就直接删除后再插入, 不会去判断位置是否需要调整。
如果score值都相同,还需要比较value值
紧凑列表
是对ziplist结构的改进,在存储空间上会更加节省,结构也比ziplist精简。
struct listpack<T> {
int32 total_bytes; // 占用的总字节数
int16 size; // 元素个数
T[] entries; // 紧凑排列的元素列表
int8 end; // 恒为0xFF
}

struct lpentry {
int<var> encoding;
optional byte[] content;
int<var> length
}
在entry结构中,长度字段存储的不是上一个元素的长度,是当前元素的长度,所以可以通过total_bytes字段和最后一个元素的长度字段计算出来。
级联更新
listpack 的设计彻底消灭了 ziplist 存在的级联更新行为,元素与元素之间完全独立,不 会因为一个元素的长度变长就导致后续的元素内容会受到影响。
- ziplist中,前一个entry长度可能会影响后一个prevlen长度,导致关联项更新。