1.1.创建DataFrame
df=pd.DataFrame(list(range(10,50,10)),columns=['num'],index=['a','b','c','d']) df
Out[6]:
num
a 10
b 20
c 30
d 40
1.2 标签和索引
1.2.1行和列的标签
df.index #行标签 Out[8]: Index(['a', 'b', 'c', 'd'], dtype='object') df.columns #列标签 Out[9]: Index(['num'], dtype='object')
1.2..2 索引
ix可以索引某特定的行,也可以以列表的形式去索引
df.ix['c'] Out[10]: num 30 Name: c, dtype: int64 df.ix[['a','b']] Out[11]: num a 10 b 20
1.2.3 切片
df.ix[df.index[1:3]] Out[12]: num b 20 c 30
1.2.4 apply函数
df.apply(lambda x:x**2) Out[13]: num a 100 b 400 c 900 d 1600
将lambda函数应用到每一个数值
1.3 维度的扩充
1.3.1 列的扩充
df['fla']=[x for x in np.linspace(1.5,4.5,4)]
df
Out[15]:
num fla
a 10 1.5
b 20 2.5
c 30 3.5
d 40 4.5
1.3.2 行的扩充
1.3.2.1. 可以取整个DataFrame 对象来定义一个新列。在这种情况下,索引向动分配:
df['names'] = pd.DataFrame(['Yves' , 'Guido' , 'Felix' , 'Francesc' ], index=['d' , 'a' , 'b' , 'c']) df Out[17]: num fla names a 10 1.5 Guido b 20 2.5 Felix c 30 3.5 Francesc d 40 4.5 Yves
1.3.2.2 append函数的追加一行
df.append( {'num':80, 'fla':0.5, 'names':'Tom'},ignore_index=True)
Out[28]:
num fla names
0 10 1.5 Guido
1 20 2.5 Felix
2 30 3.5 Francesc
3 40 4.5 Yves
4 80 0.5 Tom
1.3.2.4 join方法
df.join(pd.DataFrame([ 4, 9, 16, 25] ,index=['a' , 'b' , 'c' , 'd'] ,columns=['sq' ,])) Out[34]: num fla names sq a 10 1.5 Guido 4 b 20 2.5 Felix 9 c 30 3.5 Francesc 16 d 40 4.5 Yves 25
也可以用(how='outer')取并集
1.4 均值和标准差
df[['num','fla']].mean() Out[51]: num 25.0 fla 3.0 dtype: float64 df[['num','fla']].std() Out[52]: num 12.909944 fla 1.290994 dtype: float64
1.5 日期的添加
生成一组数据,并且转化为DataFrame
a = np.random.standard_normal((9, 4)) a.round(6) df=pd.DataFrame(a) df Out[79]: 0 1 2 3 0 0.718177 -0.933298 1.283205 -0.276078 1 0.385584 -0.467157 1.393199 -0.976146 2 -0.199838 0.440602 -0.350353 1.164440 3 1.077226 -0.327228 1.054912 0.142114 4 0.551220 0.782386 -1.383381 -0.116057 5 -0.842587 -0.361619 -0.071588 -0.238011 6 -0.853783 0.038920 0.746881 1.383499 7 -0.031835 1.323102 0.675193 -0.287660 8 -0.515417 -0.184136 -0.897797 1.059599
添加列名:
df.columns = ['No1' , 'No2' , 'No3' , 'No4'] df Out[80]: No1 No2 No3 No4 0 0.718177 -0.933298 1.283205 -0.276078 1 0.385584 -0.467157 1.393199 -0.976146 2 -0.199838 0.440602 -0.350353 1.164440 3 1.077226 -0.327228 1.054912 0.142114 4 0.551220 0.782386 -1.383381 -0.116057 5 -0.842587 -0.361619 -0.071588 -0.238011 6 -0.853783 0.038920 0.746881 1.383499 7 -0.031835 1.323102 0.675193 -0.287660 8 -0.515417 -0.184136 -0.897797 1.059599
提取某一元素
df['No2'][3] Out[81]: -0.3272278378978686
添加日期的date_range函数
首先生成一列日期,并把它作为index添加
dates=pd.date_range('2018-01-01',periods=9,freq="M") df.index=dates df
No1 No2 No3 No4
2018-01-31 0.718177 -0.933298 1.283205 -0.276078
2018-02-28 0.385584 -0.467157 1.393199 -0.976146
2018-03-31 -0.199838 0.440602 -0.350353 1.164440
2018-04-30 1.077226 -0.327228 1.054912 0.142114
2018-05-31 0.551220 0.782386 -1.383381 -0.116057
2018-06-30 -0.842587 -0.361619 -0.071588 -0.238011
2018-07-31 -0.853783 0.038920 0.746881 1.383499
2018-08-31 -0.031835 1.323102 0.675193 -0.287660
2018-09-30 -0.515417 -0.184136 -0.897797 1.059599
date range 函数频率参数值
B: 交易口
C: 自定义交易日(武验性)
D: 日历日
w :每周
M :每月底
BM: 每月最后一个交易日
MS :月初
BMS :每月第一个交易日
Q :季度末
BQ :每季度最后一个交易日
QS :季度初
BQS: 每季度第一个交易日
A :每年底
BA :每年最后一个交易日
AS :每年初
BAS: 每年第一个交易日
H :每小时
T: 每分钟
S :每秒
1.6 基本分析
按列总和、平均值、累计总和、统计描述:
df.sum() Out[87]: No1 0.288746 No2 0.311574 No3 2.450272 No4 1.855700 dtype: float64 df.mean() Out[88]: No1 0.032083 No2 0.034619 No3 0.272252 No4 0.206189 dtype: float64 df.cumsum() Out[89]: No1 No2 No3 No4 2018-01-31 0.718177 -0.933298 1.283205 -0.276078 2018-02-28 1.103760 -1.400455 2.676405 -1.252224 2018-03-31 0.903922 -0.959853 2.326051 -0.087784 2018-04-30 1.981148 -1.287081 3.380963 0.054330 2018-05-31 2.532368 -0.504694 1.997583 -0.061727 2018-06-30 1.689780 -0.866313 1.925995 -0.299737 2018-07-31 0.835997 -0.827393 2.672876 1.083761 2018-08-31 0.804162 0.495710 3.348069 0.796101 2018-09-30 0.288746 0.311574 2.450272 1.855700 df.describe() Out[90]: No1 No2 No3 No4 count 9.000000 9.000000 9.000000 9.000000 mean 0.032083 0.034619 0.272252 0.206189 std 0.695067 0.698983 0.993399 0.807175 min -0.853783 -0.933298 -1.383381 -0.976146 25% -0.515417 -0.361619 -0.350353 -0.276078 50% -0.031835 -0.184136 0.675193 -0.116057 75% 0.551220 0.440602 1.054912 1.059599 max 1.077226 1.323102 1.393199 1.383499 np.sqrt(df) __main__:1: RuntimeWarning: invalid value encountered in sqrt Out[91]: No1 No2 No3 No4 2018-01-31 0.847453 NaN 1.132787 NaN 2018-02-28 0.620954 NaN 1.180339 NaN 2018-03-31 NaN 0.663779 NaN 1.079092 2018-04-30 1.037895 NaN 1.027089 0.376980 2018-05-31 0.742442 0.884526 NaN NaN 2018-06-30 NaN NaN NaN NaN 2018-07-31 NaN 0.197281 0.864223 1.176222 2018-08-31 NaN 1.150262 0.821701 NaN 2018-09-30 NaN NaN NaN 1.029368
np.sqrt(df).sum()
__main__:1: RuntimeWarning: invalid value encountered in sqrt
Out[92]:
No1 3.248743
No2 2.895848
No3 5.026138
No4 3.661662
dtype: float64
1.7 绘图
import matplotlib.pyplot as plt df.cumsum().plot(lw=2.0)
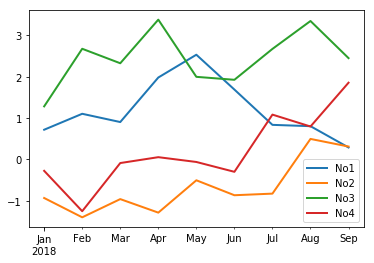
plot函数具体描述

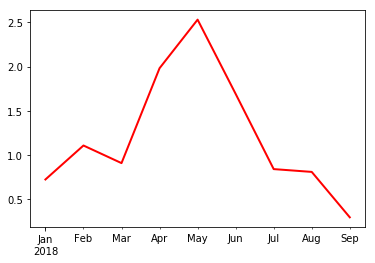
1.8 serises 类
type(df['No1']) Out[96]: pandas.core.series.Series
series绘图
df['No1'].cumsum().plot(style='r',lw=2.)
1.9 groupby操作
pandas 抖备强大而灵活的分组功能, 工作方式类似于SQL 种的分组和I Microsoft Excel中的透视表。为了进行分组,我们添加一列,表示对应索引数据所属的季度:
df['Quarter']=['Q1','Q1','Q1','Q2','Q2','Q2','Q3','Q3','Q3'] df Out[97]: No1 No2 No3 No4 Quarter 2018-01-31 0.718177 -0.933298 1.283205 -0.276078 Q1 2018-02-28 0.385584 -0.467157 1.393199 -0.976146 Q1 2018-03-31 -0.199838 0.440602 -0.350353 1.164440 Q1 2018-04-30 1.077226 -0.327228 1.054912 0.142114 Q2 2018-05-31 0.551220 0.782386 -1.383381 -0.116057 Q2 2018-06-30 -0.842587 -0.361619 -0.071588 -0.238011 Q2 2018-07-31 -0.853783 0.038920 0.746881 1.383499 Q3 2018-08-31 -0.031835 1.323102 0.675193 -0.287660 Q3 2018-09-30 -0.515417 -0.184136 -0.897797 1.059599 Q3
按季度进行分组:
groups=df.groupby('Quarter')
获取每个组的平均值( mean )、最大值( max ) 和组的大小( size )
groups.mean() Out[100]: No1 No2 No3 No4 Quarter Q1 0.301307 -0.319951 0.775350 -0.029261 Q2 0.261953 0.031180 -0.133352 -0.070651 Q3 -0.467012 0.392629 0.174759 0.718479 groups.max() Out[101]: No1 No2 No3 No4 Quarter Q1 0.718177 0.440602 1.393199 1.164440 Q2 1.077226 0.782386 1.054912 0.142114 Q3 -0.031835 1.323102 0.746881 1.383499 groups.min() Out[102]: No1 No2 No3 No4 Quarter Q1 -0.199838 -0.933298 -0.350353 -0.976146 Q2 -0.842587 -0.361619 -1.383381 -0.238011 Q3 -0.853783 -0.184136 -0.897797 -0.287660 groups.size() Out[103]: Quarter Q1 3 Q2 3 Q3 3 dtype: int64
还可以同时根据两列分组:
df['Odd_Even']=['Odd','Even','Odd','Even','Odd','Even','Odd','Even','Odd'] #添加一组 groups=df.groupby(['Quarter','Odd_Even'])
groups.mean() Out[106]: No1 No2 No3 No4 Quarter Odd_Even Q1 Even 0.385584 -0.467157 1.393199 -0.976146 Odd 0.259169 -0.246348 0.466426 0.444181 Q2 Even 0.117319 -0.344423 0.491662 -0.047948 Odd 0.551220 0.782386 -1.383381 -0.116057 Q3 Even -0.031835 1.323102 0.675193 -0.287660 Odd -0.684600 -0.072608 -0.075458 1.221549 groups.max() Out[107]: No1 No2 No3 No4 Quarter Odd_Even Q1 Even 0.385584 -0.467157 1.393199 -0.976146 Odd 0.718177 0.440602 1.283205 1.164440 Q2 Even 1.077226 -0.327228 1.054912 0.142114 Odd 0.551220 0.782386 -1.383381 -0.116057 Q3 Even -0.031835 1.323102 0.675193 -0.287660 Odd -0.515417 0.038920 0.746881 1.383499 groups.size() Out[108]: Quarter Odd_Even Q1 Even 1 Odd 2 Q2 Even 2 Odd 1 Q3 Even 1 Odd 2 dtype: int64