简介
在所有机器学习算法中,k近邻(K-Nearest Neighbors,KNN)相对是比较简单的。 尽管它很简单,但事实证明它在某些任务中非常有效,甚至更好。它可以用于分类和回归问题! 然而,它更常用于分类问题。 在本文中,我们将首先了解KNN算法背后的原理,研究计算点之间距离的不同方法,然后最终用Python实现该算法。
目录
- 一个简单的例子来理解KNN背后的原理
- KNN算法如何工作
- 计算点之间距离的方法
- 如何选择k因子
- KNN聚类实例(python)
1.一个简单的例子来理解KNN背后的原理
让我们从一个简单的例子开始。请考虑下图,,我们有两类数据,分别是蓝色方块和红色三角形,他们分布在一个上图的二维中间中。那么假如我们有一个绿色圆圈这个数据,需要判断这个数据是属于蓝色方块这一类,还是与红色三角形同类呢?
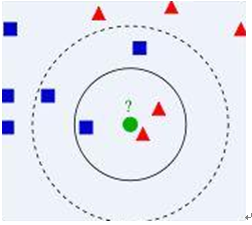
我们先把离这个绿色圆圈最近的几个点找到,根据相似性,离绿色圆圈最近的才对它的类别有判断的帮助。那到底要用多少个来判断呢?这个个数就是k了。
- 如果k=3,就表示我们选择离绿色圆圈最近的3个点来判断,由于红色三角形所占比例为2/3,所以我们认为绿色圆是和红色三角形同类。
- 如果k=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
它的思想很简单:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
2.KNN算法如何工作
算法流程:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类
3.计算点之间距离的方法
第一步是计算新点和每个训练点之间的距离。 有多种计算这种距离的方法,其中最常见的方法是 - 欧几里德,曼哈顿(对连续变量)和汉明距离(对分类变量)。
- 欧几里德距离:欧几里德距离计算为新点(x)和现有点(y)之间的平方差之和的平方根。
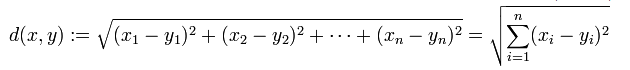
- 曼哈顿距离:这是实际向量之间的距离,使用它们的绝对差值之和。
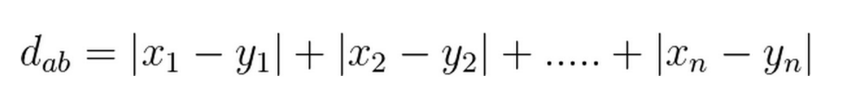
- 汉明距离:用于分类变量。 如果值(x)和值(y)相同,则距离D将等于0。 否则D = 1。
一旦测量了新观测距离训练集中各点的距离,下一步就是选择最近的点。 要考虑的点数由k的值定义。
4.如何选择k因子
首先让我们试着了解K在算法中的确切影响。 如果我们看到最后一个例子,假设所有训练观察值保持不变,给定K值我们可以为每个类创建边界。 这些边界将两个别别分开。 让我们试着看看“K”值对类边界的影响。 以下是用不同的K值分隔两个类的不同边界:

仔细观察,可以发现:随着K值的增加,边界变得更加平滑。随着K增加到无穷大,它最终变成全蓝色或全红色。我们可以根据我们的训练和验证集的误差计算来决定它(毕竟,我们的最终目标是最小化误差)。
以下是具有不同k值的训练误差和验证误差:
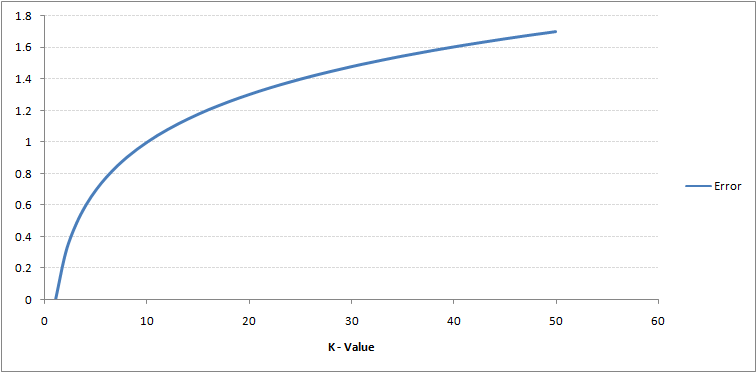
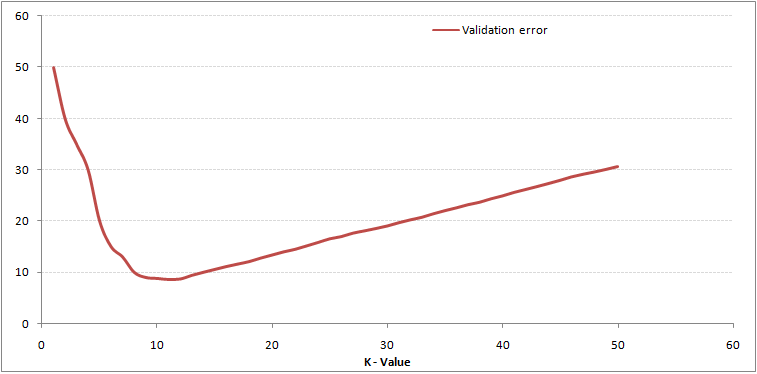
对于非常低的k值(假设k = 1),模型过度拟合训练数据,这导致验证集上的高错误率。 另一方面,对于较大的k值,该模型在训练和验证集上都表现不佳。 如果仔细观察,会发现验证误差曲线在k = 9的值处达到最小值。该k值是模型的最佳值(对于不同的数据集,它将有所不同)。 该曲线称为“肘形曲线”,通常用于确定k值。
我们还可以使用网格搜索技术来查找最佳k值。 我们将在下一节中实现这一点。
5.KNN聚类实例
可以在这里下载数据集。
1.导入数据:
import numpy as np import pandas as pd import matplotlib.pyplot as plt
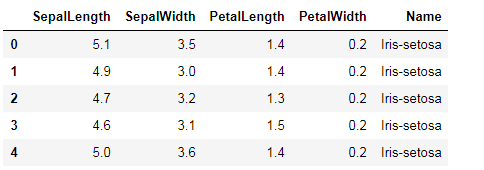
#查看数据 data.head()
2.变量的处理
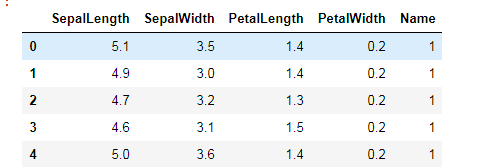
由于类别变量为非数值型,我们需要进行处理。
name_list=data['Name'].unique() for i in name_list: data.loc[data['Name']==i,'Name']=list(name_list).index(i)+1 data.head()
3.分割训练集和测试集
我们可以把数据70%用于训练,30%用于测试。
#create trainset and testset from sklearn.model_selection import train_test_split train , test = train_test_split(data, test_size = 0.3) x_train = train.drop('Name', axis=1) y_train = train['Name'] x_test = test.drop('Name', axis = 1) y_test = test['Name']
4.预处理 - 缩放功能
我们需要对数据进行归一化处理,即均值为0,方差为1。
好处:消除特征之间量级不同导致的影响。
#Preprocessing – Scaling the features from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler(feature_range=(0, 1)) x_train_scaled = scaler.fit_transform(x_train) x_train = pd.DataFrame(x_train_scaled) x_test_scaled = scaler.fit_transform(x_test) x_test = pd.DataFrame(x_test_scaled)
5.查看不同k值下的分类错误率
我们用均方误差的平方根来衡量。
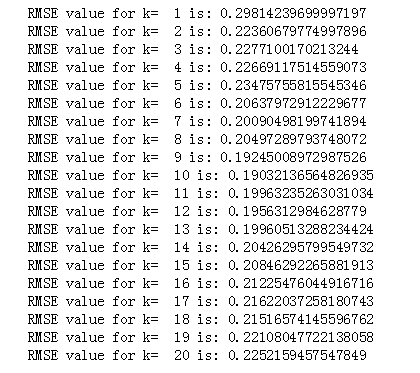
#import required packages from sklearn import neighbors from sklearn.metrics import mean_squared_error from math import sqrt rmse_val = [] #to store rmse values for different k for K in range(20): K = K+1 model = neighbors.KNeighborsRegressor(n_neighbors = K) model.fit(x_train, y_train) #fit the model pred=model.predict(x_test) #make prediction on test set error = sqrt(mean_squared_error(y_test,pred)) #calculate rmse rmse_val.append(error) #store rmse values print('RMSE value for k= ' , K , 'is:', error)
画出分类错误曲线:
#plotting the rmse values against k values curve = pd.DataFrame(rmse_val) #elbow curve curve.plot()
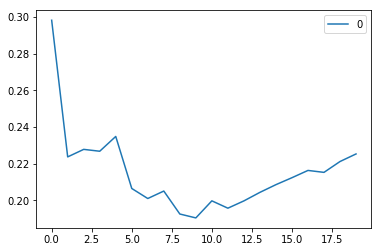
正如我们所讨论的,当我们取k = 1时,我们得到一个非常高的RMSE值。 随着我们增加k值,RMSE值减小。 在k = 7时,RMSE约为0.2266,并且在进一步增加k值时上升。 在这种情况下,我们可以判断,k = 7会给我们带来最好的结果。
这些是使用我们的训练数据集的预测。 现在让我们预测测试数据集的值。
6.应用Gridsearch
为了确定k的值,每次绘制‘”肘曲线”是一个麻烦且繁琐的过程。 您只需使用gridsearch即可找到最佳值。
from sklearn.model_selection import GridSearchCV params = {'n_neighbors':[2,3,4,5,6,7,8,9]} knn = neighbors.KNeighborsRegressor() model = GridSearchCV(knn, params, cv=5) model.fit(x_train,y_train) model.best_params_
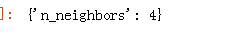
可以看出,k=4确实是最佳选择。
小结
KNN算法是最简单的分类算法之一。 即使如此简单,它也可以提供极具竞争力的结果。 KNN算法也可用于回归问题。 与讨论的方法的唯一区别将是使用最近邻居的平均值而不是从最近邻居投票。
优点
- 简单好用,容易理解,既可以用来做分类也可以用来做回归;
- 可用于数值型数据和离散型数据;
- 训练时间复杂度为O(n);无数据输入假定;
- 对异常值不敏感。
缺点:
- 计算复杂性高;空间复杂性高;
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
- 一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分。
- 最大的缺点是无法给出数据的内在含义。
以上对KNN的简单总结与应用,希望对您有所帮助!