今天给同事 一个k8s 集群 出现not ready了 花了 40min 才搞定
这里记录一下 避免下载 再遇到了 不清楚.
错误现象:
untime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
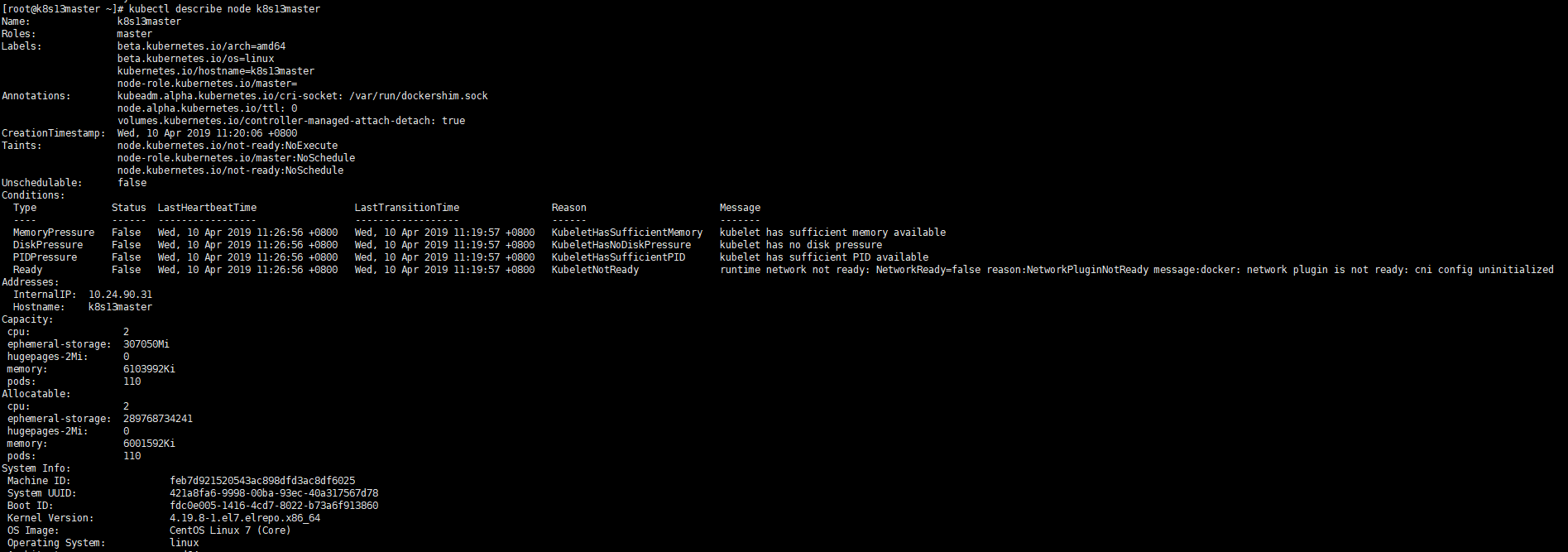
解决办法:
docker pull quay.io/coreos/flannel:v0.9.1-amd64
mkdir -p /etc/cni/net.d/
cat <<EOF> /etc/cni/net.d/10-flannel.conf {"name":"cbr0","type":"flannel","delegate": {"isDefaultGateway": true}} EOF mkdir /usr/share/oci-umount/oci-umount.d -p mkdir /run/flannel/ cat <<EOF> /run/flannel/subnet.env FLANNEL_NETWORK=172.100.0.0/16 FLANNEL_SUBNET=172.100.1.0/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true EOF
然后执行命令:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml
Study From
https://blog.csdn.net/qq_34857250/article/details/82562514
原始帖子为:
k8s 集群部署问题整理
对kubernetes感兴趣的可以加群885763297,一起玩转kubernetes
1、hostname “master” could not be reached
在host中没有加解析
2、curl -sSL http://localhost:10248/healthz
curl: (7) Failed connect to localhost:10248; 拒绝连接 在host中没有localhost的解析
3、Error starting daemon: SELinux is not supported with the overlay2 graph driver on this kernel. Either boot into a newer kernel or…abled=false)
vim /etc/ssconfig/docker --selinux-enabled=False
4、bridge-nf-call-iptables 固化的问题:
#下面的是关于bridge的配置: net.bridge.bridge-nf-call-ip6tables = 0 net.bridge.bridge-nf-call-iptables = 1 #意味着二层的网络在转发包的时候会被iptables的forward规则过滤 net.bridge.bridge-nf-call-arptables = 0
5、The connection to the server localhost:8080 was refused - did you specify the right host or port?
unable to recognize "kube-flannel.yml": Get http://localhost:8080/api?timeout=32s: dial tcp [::1]:8080: connect: connection refused 下面如果在root用户下执行的,就不会报错 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
###6、error: unable to recognize “mycronjob.yml”: no matches for kind “CronJob” in version “batch/v2alpha1”去kube-apiserver.yaml文件中添加: - --runtime-config=batch/v2alpha1=true,然后重启kubelet服务,就可以了
7、Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized Unable to update cni config: No networks found in /etc/cni/net.d Failed to get system container stats for “/system.slice/kubelet.service”: failed to get cgroup stats for “/system.slice/kubelet.service”: failed to get container info for “/system.slice/kubelet.service”: unknown container “/system.slice/kubelet.service”
docker pull quay.io/coreos/flannel:v0.10.0-amd64
mkdir -p /etc/cni/net.d/
cat <<EOF> /etc/cni/net.d/10-flannel.conf
{"name":"cbr0","type":"flannel","delegate": {"isDefaultGateway": true}}
EOF
mkdir /usr/share/oci-umount/oci-umount.d -p
mkdir /run/flannel/
cat <<EOF> /run/flannel/subnet.env
FLANNEL_NETWORK=172.100.0.0/16
FLANNEL_SUBNET=172.100.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml8、Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of “crypto/rsa: verification error” while trying to verify candidate authority certificate “kubernetes”)
export KUBECONFIG=/etc/kubernetes/kubelet.conf
9、Failed to get system container stats for “/system.slice/docker.service”: failed to get cgroup stats for “/system.slice/docker.service”: failed to get container info for “/system.slice/docker.service”: unknown container “/system.slice/docker.service”
vim /etc/sysconfig/kubelet --runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice systemctl restart kubelet
大概意思是Flag --cgroup-driver --kubelet-cgroups 驱动已经被禁用,这个参数应该通过kubelet 的配置指定配置文件来配置
10、The HTTP call equal to ‘curl -sSL http://localhost:10255/healthz’ failed with error: Get http://localhost:10255/healthz: dial tcp 127.0.0.1:10255: getsockopt: connection refused.
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false"
###11、failed to run Kubelet: failed to create kubelet: miscon figuration: kubelet cgroup driver: “systemd” is different from docker cgroup driver: “cgroupfs”kubelet: Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd" docker: vi /lib/systemd/system/docker.service -exec-opt native.cgroupdriver=systemd
12、[ERROR CRI]: unable to check if the container runtime at “/var/run/dockershim.sock” is running: exit status 1
rm -f /usr/bin/crictl
13、 Warning FailedScheduling 2s (x7 over 33s) default-scheduler 0/4 nodes are available: 4 node(s) didn’t match node selector.
如果指定的label在所有node上都无法匹配,则创建Pod失败,会提示无法调度:
14、kubeadm 生成的token过期后,集群增加节点
kubeadm token create
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null |
openssl dgst -sha256 -hex | sed 's/^.* //'
kubeadm join --token aa78f6.8b4cafc8ed26c34f --discovery-token-ca-cert-hash sha256:0fd95a9bc67a7bf0ef42da968a0d55d92e52898ec37c971bd77ee501d845b538 172.16.6.79:6443 --skip-preflight-checks15、### systemctl status kubelet告警
cni.go:171] Unable to update cni config: No networks found in /etc/cni/net.d
May 29 06:30:28 fnode kubelet[4136]: E0529 06:30:28.935309 4136 kubelet.go:2130] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized删除 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf 的 KUBELET_NETWORK_ARGS,然后重启kubelet服务 临时解决。没啥用根本原因是缺少: k8s.gcr.io/pause-amd64:3.1
16 删除flannel网络:
ifconfig cni0 down
ifconfig flannel.1 down
ifconfig del flannel.1
ifconfig del cni0
ip link del flannel.1
ip link del cni0
yum install bridge-utils
brctl delbr flannel.1
brctl delbr cni0
rm -rf /var/lib/cni/flannel/* && rm -rf /var/lib/cni/networks/cbr0/* && ip link delete cni0 && rm -rf /var/lib/cni/network/cni0/*
17、E0906 15:10:55.415662 1 leaderelection.go:234] error retrieving resource lock default/ceph.com-rbd: endpoints “ceph.com-rbd” is forbidden: User “system:serviceaccount:default:rbd-provisioner” cannot get endpoints in the namespace “default”
`在 添加下面的这一段 (会重新申请资源) kubectl apply -f ceph/rbd/deploy/rbac/clusterrole.yaml
- apiGroups: [""]
resources: [“endpoints”]
verbs: [“get”, “list”, “watch”, “create”, “update”, “patch”]`
18、flannel指定网卡设备:
- --iface=eth0
21、 Failed create pod sandbox: rpc error: code = Unknown desc = [failed to set up sandbox container “957541888b8a0e5b9ad65da932f688eb02cc182808e10d1a89a6e8db2132c253” network for pod “coredns-7655b945bc-6hgj9”: NetworkPlugin cni failed to set up pod “coredns-7655b945bc-6hgj9_kube-system” network: failed to find plugin “loopback” in path [/opt/cni/bin], failed to clean up sandbox container “957541888b8a0e5b9ad65da932f688eb02cc182808e10d1a89a6e8db2132c253” network for pod “coredns-7655b945bc-6hgj9”: NetworkPlugin cni failed to teardown pod “coredns-7655b945bc-6hgj9_kube-system” network: failed to find plugin “portmap” in path [/opt/cni/bin]]
https://kubernetes.io/docs/setup/independent/troubleshooting-kubeadm/#coredns-pods-have-crashloopbackoff-or-error-state
如果您的网络提供商不支持portmap CNI插件,您可能需要使用服务的NodePort功能或使用HostNetwork=true。
22、问题:kubelet设置了system-reserved(800m)、kube-reserved(500m)、eviction-hard(800),其实集群实际可用的内存是总内存-800m-800m-500m ,但是发现还 是会触发系统级别kill进程,
排查:使用top查看前几名的内存使用情况,发现etcd服务使用了内存达到500M以上,kubelet使用内存200m,ceph使用内存总和是200多m,加起来就已经900m了,这些都是k8s之外的系统开销,已经完全超出了系统预留内存,因此可能会触发系统级别的kill,
23、如何访问api-server?
使用kubectl proxy功能
24、使用svc的endpoint代理集群外部服务,经常出现endpoint丢失的问题
解决:去掉service.spec.selecter 标签就好了。
25、集群雪崩的一次问题处理,node节点偶尔出现noreading状态,
排查:此node节点上cpu使用率过高。
1、没有触发node节点上的cpuPressure的状态,判断出来不是k8s所管理的cpu占用过高的问题,应该是system、kube组件预留的cpu高导致的。
2、查看cpu和mem的cgroup分组,发现kubelet,都在system.sliec下面,因此判断kube预留资源没有生效导致的。
3、
--enforce-node-allocatable=pods,kube-reserved,system-reserved #采用硬限制,超出限制就oom
--system-reserved-cgroup=/system.slice #指定系统reserved-cgroup对那些cgroup限制。
--kube-reserved-cgroup=/system.slice/kubelet.service #指定kube-reserved-cgroup对那些服务的cgroup进行限制
--system-reserved=memory=1Gi,cpu=500m
--kube-reserved=memory=500Mi,cpu=500m,ephemeral-storage=10Gi 26、[etcd] Checking Etcd cluster health
etcd cluster is not healthy: context deadline exceeded