1、通过name属性定位 find_element_by_name
百度首页举例子
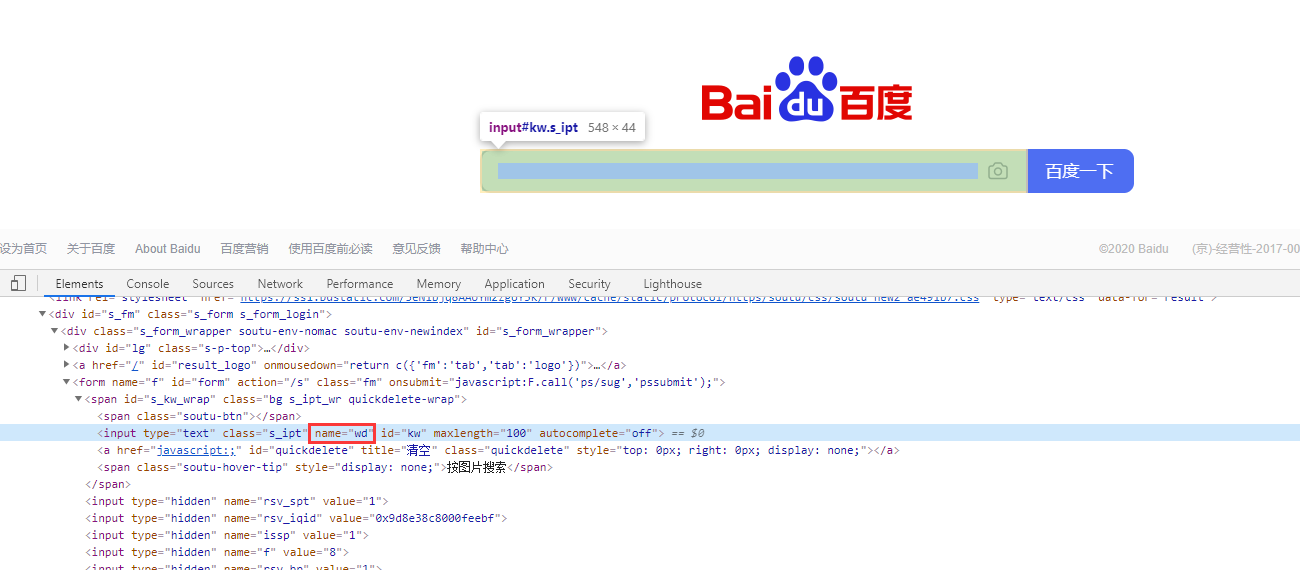
from selenium import webdriver import time driver = webdriver.Chrome() driver.get(url="http://www.baidu.com") driver.maximize_window() driver.find_element_by_name("wd").send_keys("hello world") time.sleep(3) driver.quit()
2、通过class属性定位 find_element_by_class_name
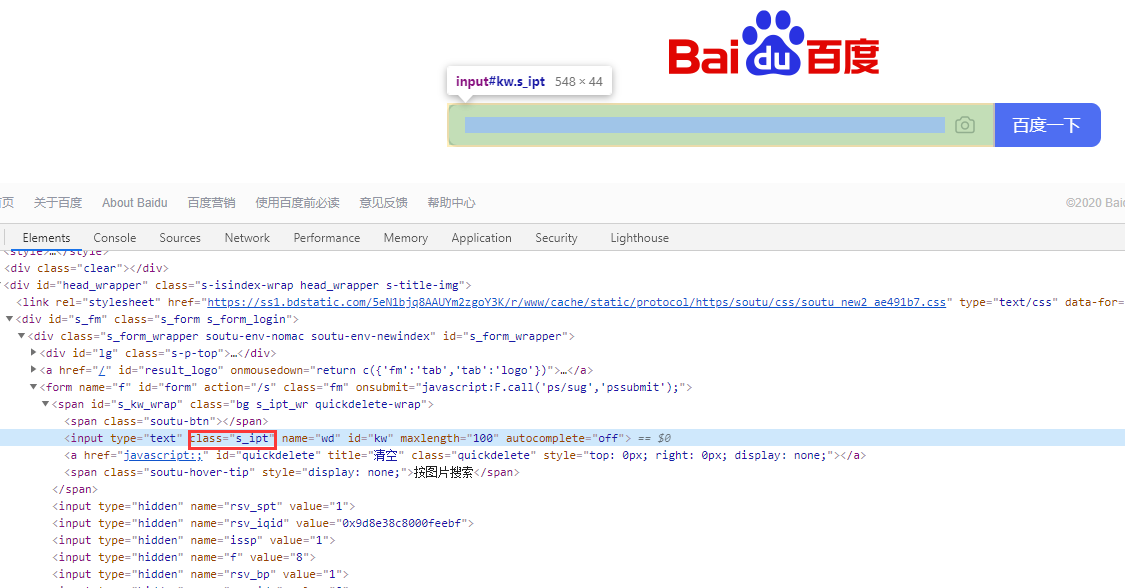
from selenium import webdriver import time driver = webdriver.Chrome() driver.get(url="http://www.baidu.com") driver.maximize_window() # driver.find_element_by_name("wd").send_keys("hello world") driver.find_element_by_class_name("s_ipt").send_keys("hello world") time.sleep(3) driver.quit()
3、通过标签tag_name属性定位 find_element_by_tag_name (不建议用,因为页面标签很多)
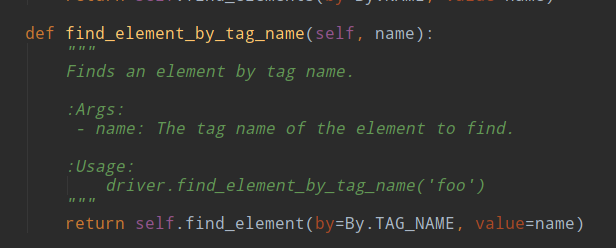
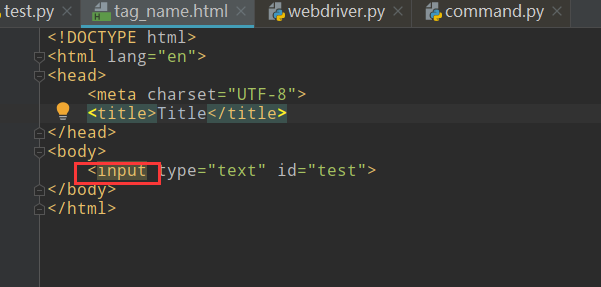
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <input type="text" id="test"> </body> </html>
from selenium import webdriver import time driver = webdriver.Chrome() # driver.get(url="http://www.baidu.com") driver.get("file://D:/python+selenium/test/tag_name.html") # html文件的绝对路径 driver.maximize_window() driver.find_element_by_tag_name("input").send_keys("hello world") time.sleep(3) driver.quit()
4、通过超链接文本定位 find_element_by_link_text
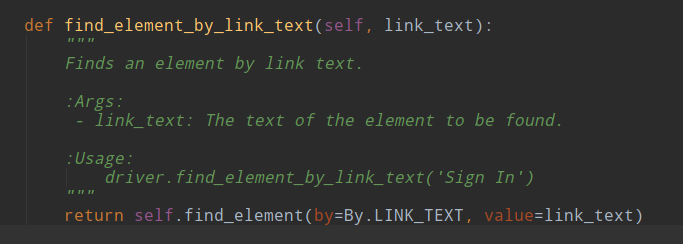
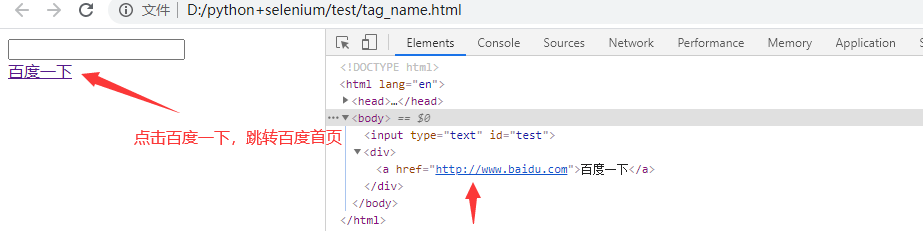
from selenium import webdriver import time driver = webdriver.Chrome() # driver.get(url="http://www.baidu.com") driver.get("file://D:/python+selenium/test/tag_name.html") # html文件的绝对路径 driver.maximize_window() driver.find_element_by_link_text("百度一下").click() time.sleep(3) driver.quit()
<a href="http://www.baidu.com">百度一下</a> 可以看到这个元素a,超链接href="http://www.baidu.com",点击百度一下这个文本,会自动跳转到百度首页,这个方法针对有超链接跳转的文本
5、通过超链接,文本模糊匹配定位 find_element_by_partial_link_text
这个方法是,超链接的文本过长,通过部分文本模糊匹配
from selenium import webdriver import time driver = webdriver.Chrome() # driver.get(url="http://www.baidu.com") driver.get("file://D:/python+selenium/test/tag_name.html") # html文件的绝对路径 driver.maximize_window() # driver.find_element_by_link_text("百度一下").click() driver.find_element_by_partial_link_text("百度").click() time.sleep(3) driver.quit()
6、通过css定位 find_element_by_css_selector
from selenium import webdriver import time driver = webdriver.Chrome() driver.get(url="http://www.baidu.com") driver.maximize_window() driver.find_element_by_css_selector("[id = 'kw']").send_keys("hello world") time.sleep(3) driver.quit()
当然,通过css定位肯定不止这一种,还有很多其他的方式,可以参考博客: https://www.cnblogs.com/zuodaozhudemeng/p/7487798.html
7、通过xpath定位 find_element_by_xpath

from selenium import webdriver import time driver = webdriver.Chrome() driver.get(url="http://www.baidu.com") driver.maximize_window() driver.find_element_by_xpath("//input[@id = 'kw']").send_keys("hello world") time.sleep(3) driver.quit()
通过 xpath 的多种定位方法,会写一篇详细的博客来解释,个人而言,用的比较多的还是xpath方法来定位 。
以上就是元素定位的常用方法,根据实际情况去具体应用。