一、Redis介绍
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。可以满足很多应用场景。还提供了键过期,发布订阅,事务,流水线等附加功能。
Github源码:https://github.com/antirez/redis
Redis官网:https://redis.io/
二、Redis使用场景
存储缓存、投票、会话session、排行榜、计数器、发布订阅、消息队列等,其中最主要的使用场景就是存储缓存和会话Session。
当用作存储缓存的时候,如下图所示:

第一次访问的时候Redis数据库没有数据,因此先从MySQL中查询,然后再存到Redis内存数据库;第二次访问的时候直接就可以从Redis数据库中得到数据。
当Redis用作缓存会话Session时。如下图所示:
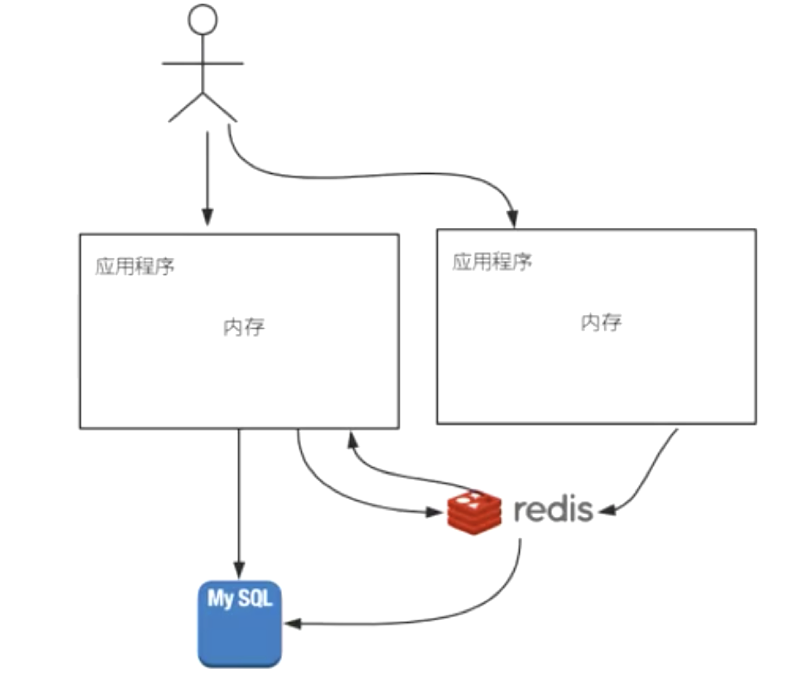
所有应用都是对Redis进行访问,这样分布式的应用程序共享一份会话Session。
三、快速安装
Redis3.0以前》不支持集群》基于客户端实现
Redis3.0以后》集群(Redis Cluster)》基于服务端实现
Redis的安装很简单,如下所示:
$ wget http://download.redis.io/releases/redis-5.0.5.tar.gz $ tar xzf redis-5.0.5.tar.gz $ cd redis-5.0.5 $ make
关于安装的详细步骤可以参考(Mac版本,Linux上的安装步骤一致):Mac下安装Redis及Redis Desktop Manager
其余多种模式的部署请参考:Redis学习之4种模式实践及机制解析(单机、主从、哨兵、集群)
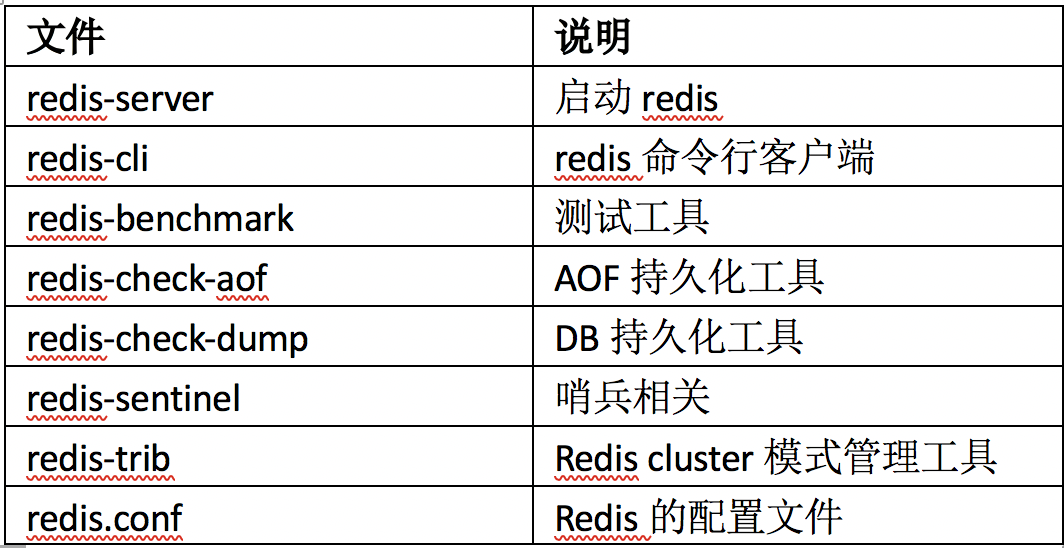
Redis安装目录下常见文件如下:
四、通讯原理概述
Redis的速度是很快的,基于以下原因:
- Redis是单进程单线程运行,因此不存在线程切换造成的资源浪费(但是也是缺点,如果命令执行缓慢就会造成阻塞);
- Redis数据是是安装在硬盘上,但是运行数据是在内存中,访问速度远大于硬盘,避免大量IO。
- Redis 服务器是基于高效的IO多路复用,效率高。
Redis 服务器是一个事件驱动程序, 服务器处理的事件分为时间事件和文件事件两类。
- 文件事件:Redis主进程中,主要处理客户端的连接请求与相应。
- 时间事件:fork出的子进程中,处理如AOF持久化任务等。
由于Redis的文件事件是单进程,单线程模型,但是确保持着优秀的吞吐量,IO多路复用起到了主要作用。简单解释多路复用就是一个线程监听多个套接字,谁先有读写事件就处理谁,减少线程切换开销和IO阻塞,以提高CPU利用率。
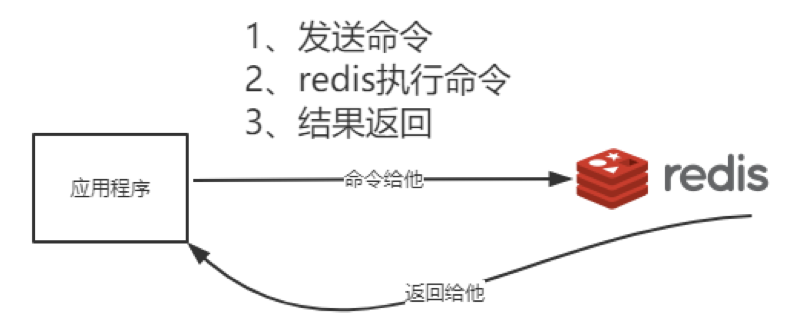
Redis访问过程如下:
I/O多路复用展示:

上面提过,Redis是基于I/O多路复用,然后用C实现的。当接收到请求后,也说过Redis服务器是个事件驱动程序,然后Redis的文件事件分派器就会一直轮询,C源码就是方法aeMain()方法内部一直轮询,然后调用aeProcessEvents(),这个方法就是去调用事件处理器,适配具体的handler(连接应答处理器、命令请求处理器),在适配handler过程中会调用acApiPoll()方法进行系统的适配(Windows、Linux等),然后Linux中调用的是ae_epoll.c文件,也就是这样的过程基于事件实现IO多路复用,效率是很高的。
五、Redis日常操作
Redis有五种数据类型,为:字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)。关于五种数据类型以及作用请参考:Redis学习之5种数据类型操作、实现原理及应用场景
五种数据常见操作如下:
1、字符串
字符串类型:实际上可以是字符串(包括XML JSON),还有数字(整形 浮点数),二进制(图片 音频 视频),最大不能超过512MB。
设值命令: set key value set name monkey ex 20 //20秒后过期 px 20000 毫秒过期 setnx name monkey //不存在键name时,返回1设置成功;存在的话失败0 set age 18 xx //存在键age时,返回1成功 批量设值:mset name monkey sex boy 批量获取:mget name sex ( ) append追加指令: set name hello; append name world //追加后成helloworld 字符串长度: set monkey '真帅' strlen monkey//结果6,每个中文占3个字节(utf-8) 截取字符串: set name monkey; getrange name 2 4//返回“nke” 计数器: CAS(Atomic原子操作) incr age //必须为整数自加1,非整数返回错误,无age键从0自增返回1 decr age //整数age减1 incrby age 1 //整数age+1 decrby age 1//整数age -1 incrbyfloat score 3.3 //浮点型score+3.3
// 分布式高并发中,可以解决线程安全问题,例如生成唯一号码(订单号)
2、Hash类型
哈希hash是一个string类型的field和value的映射表,hash特适合用于存储对象,如:

命令 hset key field value 设值:hset user:1 name monkey //成功返回1,失败返回0 取值:hget user:1 name //返回monkey 删值:hdel user:1 age //返回删除的个数 计算个数:hset user:1 name monkey; hset user:1 age 18; hlen user:1 //返回2,user:1有两个属性值 批量设值:hmset user:2 name monkey age 18sex boy //返回OK 批量取值:hmget user:2 name age sex //返回三行:monkey 18 boy 判断field是否存在:hexists user:2 name //若存在返回1,不存在返回0 获取所有field: hkeys user:2 // 返回name age sex三个field 获取user:2所有value:hvals user:2 // 返回monkey18 boy 获取user:2所有field与value:hgetall user:2 //name age sex monkey18 18 boy值 增加1:hincrby user:2 age 1 //age+1 浮点增加:hincrbyfloat user:2 age 2 //浮点型加2
3、List集合
用来存储多个有序的字符串,一个列表最多可存2的32次方减1个元素。
添加命令: rpush monkey c b a //从右向左插入cba, 返回值3 lrange monkey 0 -1 //从左到右获取列表所有元素 返回 c b a lpush key c b a //从左向右插入cba linsert monkey before b z //在b之前插入z, after为之后,使 用lrange monkey 0 -1 查看:c z b a
查找命令: lrange key start end //索引下标特点:从左到右为0到N-1 lindex monkey -1 //返回最右末尾a,-2返回b llen monkey //返回当前列表长度 lpop monkey //把最左边的第一个元素c删除 rpop monkey //把最右边的元素a删除
4、Set集合
常用于用户标签,社交,查询有共同兴趣爱好的人,智能推荐。保存多元素,与列表不一样的是不允许有重复元素,且集合是无序,一个集合最多可存2的32次方减1个元素,除了支持增删改查,还支持集合交集、并集、差集;
exists user //检查user键值是否存在 sadd user a b c //向user插入3个元素,返回3 sadd user a b //若再加入相同的元素,则重复无效,返回0 smembers user //获取user的所有元素,返回结果无序 srem user a //返回1,删除a元素 scard user //返回2,计算元素个数
5、有序集合ZSET
常用于排行榜,如视频网站需要对用户上传视频做排行榜,或点赞数与集合有联系,不能有重复的成员
指令: zadd key score member [score member......] 例子: zadd user:zan 200 monkey //monkey的点赞数1, 返回操作成功的条数1 zadd user:zan 200 monkey 120 fox 100 lion // 返回3 zadd user:zan nx 100 monkey //键test:1必须不存在,主用于添加 zadd user:zan xx incr 200 monkey //键test:1必须存在,主用于修改,此时为300 zadd user:zan xx ch incr -299 monkey //返回操作结果1,300-299=1 zrange user:zan 0 -1 withscores //查看点赞(分数)与成员名 zcard user:zan //计算成员个数, 返回1 排名场景: zadd user:3 200 monkey120 fox 100 lee //先插入数据 zrange user:3 0 -1 withscores //查看分数与成员 zrank user:3 monkey //返回名次:第3名返回2,从0开始到2,共3名 zrevrank user:3 monkey //返回0, 反排序,点赞数越高,排名越前
6、Redis全局命令
查看所有键: keys * 键总数 : dbsize //2个键,如果存在大量键,线上禁止使用此指令 检查键是否存在: exists key //存在返回1,不存在返回0 删除键: del key //del key, 返回删除键个数,删除不存在键返回0 键过期: expire key seconds //set name test expire name 10,表示10秒过期 ttl key // 查看剩余的过期时间 键的数据结构类型: type key //type hello //返回string,键不存在返回none
7、redis数据库管理
select 0 //数据库 16个数据库(0-15) 默认都是0库 flushdb //清除当前数据库 flushall //清楚所有数据库记录 dbsize //命令用于返回当前数据库的 key 的数量
六、Redis持久化
持久化作用:redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化,持久化可以避免因进程退出而造成数据丢失。Redis持久化有两种方式:RDB快照和AOF方式。
1、RDB
RDB持久化把当前进程数据生成快照(.rdb)文件保存到硬盘的过程,有手动触发和自动触发手动触发有save和bgsave两命令:
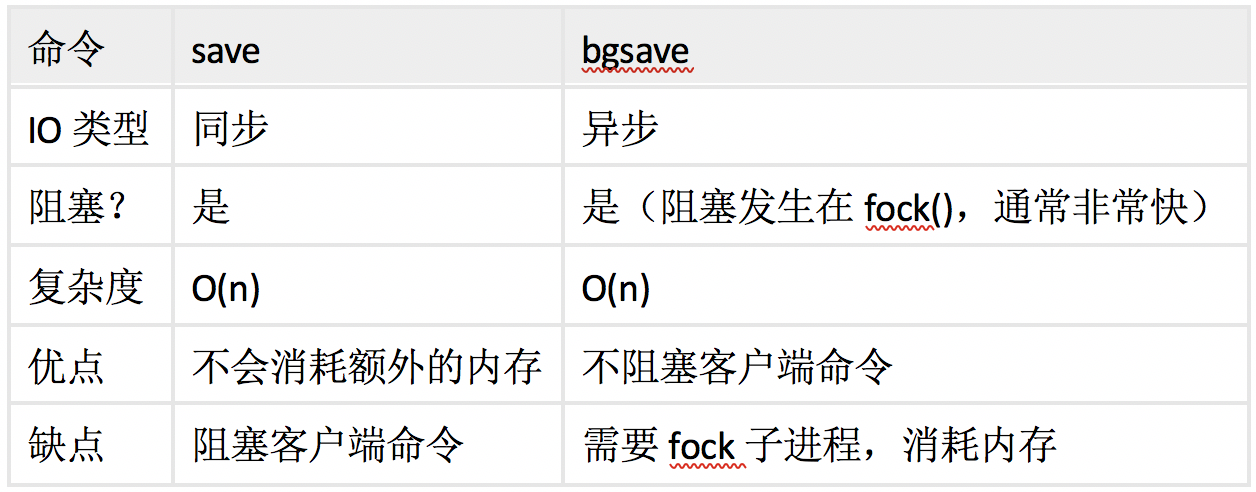
- save命令:阻塞当前Redis,直到RDB持久化过程完成为止,若内存实例比较大会造成长时间阻塞,线上环境不建议用它
- bgsave命令:redis进程执行fork操作创建子线程,由子线程完成持久化,阻塞时间很短(微秒级),是save的优化,在执行redis-cli shutdown关闭redis服务时,如果没有开启AOF持久化,自动执行bgsave;
1.1、Save命令
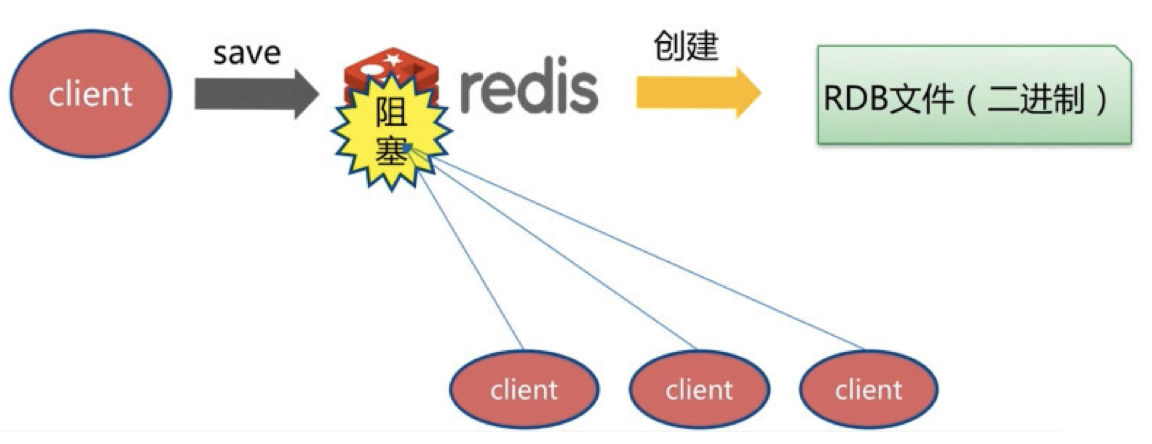
由于 save 命令是同步命令,会占用Redis的主进程。若Redis数据非常多时,save命令执行速度会非常慢,阻塞所有客户端的请求。
因此很少在生产环境直接使用SAVE 命令,可以使用BGSAVE 命令代替。如果在BGSAVE命令的保存数据的子进程发生错误的时,用 SAVE命令保存最新的数据是最后的手段。如图所示:
1.2、Bgsave命令
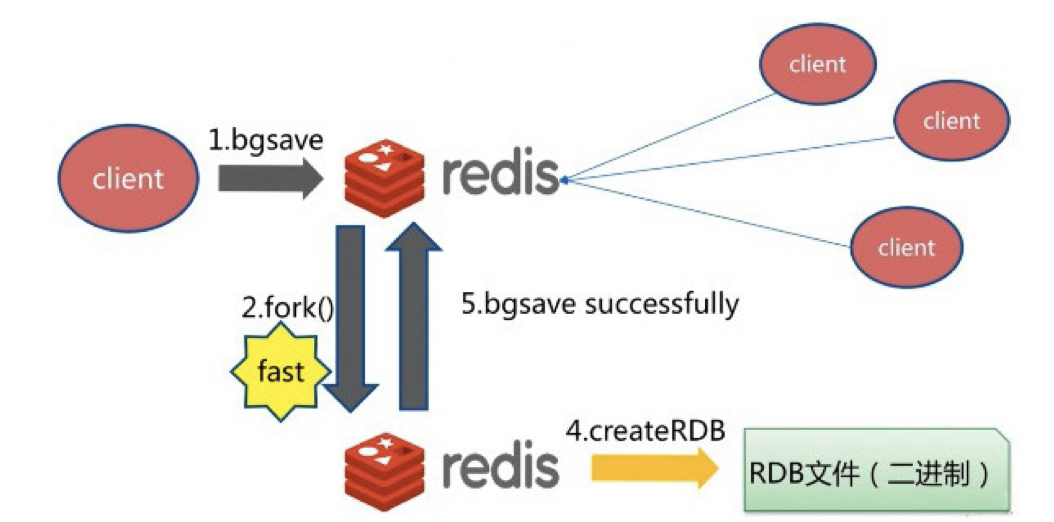
bgsave 命令执行一个异步操作,以RDB文件的方式保存所有数据的快照。如:
127.0.0.1:6379> bgsave Background saving started
如图所示:
1.3、save 与 bgsave 对比
操作:
命令:config set dir /usr/local //设置rdb文件保存路径 备份:bgsave //将dump.rdb保存到usr/local下 恢复:将dump.rdb放到redis安装目录与redis.conf同级目录,重启redis即可
1.4、RDB优缺点
RDB优点:
- 压缩后的二进制文,适用于备份、全量复制,用于灾难恢复加载RDB恢复数据远快于AOF方式
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些。
- 使用bgsave保存,交由子进程进行快照保存,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能。
RDB缺点:
- 无法做到实时持久化,每次都要创建子进程,频繁操作成本过高
- 保存后的二进制文件,存在老版本不兼容新版本rdb文件的问题
2、AOF
快照功能(RDB)并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。 从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
打开AOF后, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
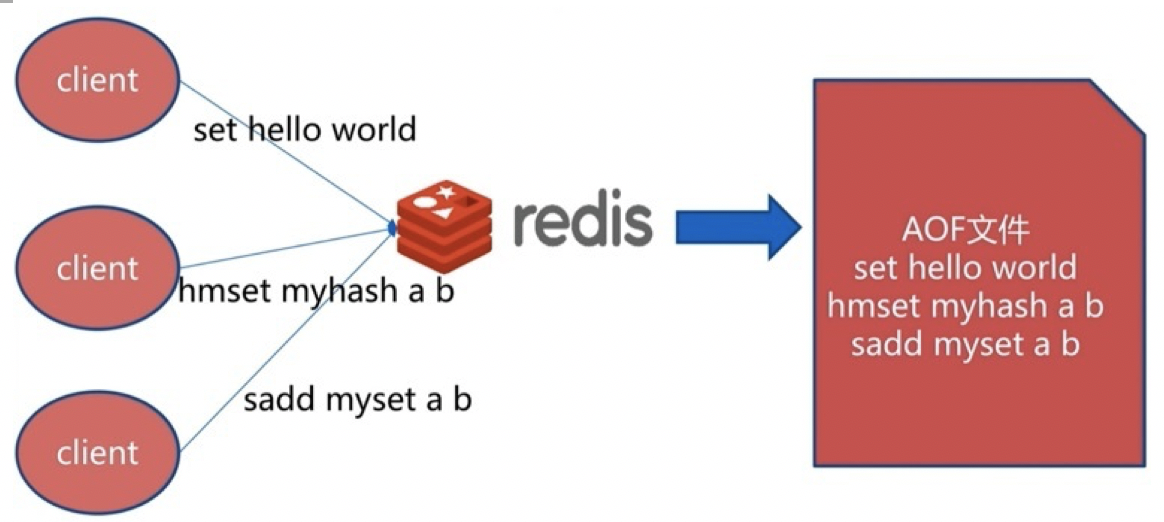
操作: 开启:redis.conf设置:appendonly yes (默认不开启,为no) 默认文件名:appendfilename "appendonly.aof"
三种策略always、everysec、no对比
- always: 不丢失数据 IO开销大,一般SATA磁盘只有几百TPS 每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全。
- everysec 每秒进行与fsync:最多丢失1秒数据 可能丢失1秒数据 每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
- no 不用管 不可控 从不 fsync :将数据交给操作系统来处理,由操作系统来决定什么时候同步数据。更快,也更不安全的选择。

AOF的优点:
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync。使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据。
- AOF文件是一个只进行追加的日志文件,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题。
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF的缺点:
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)
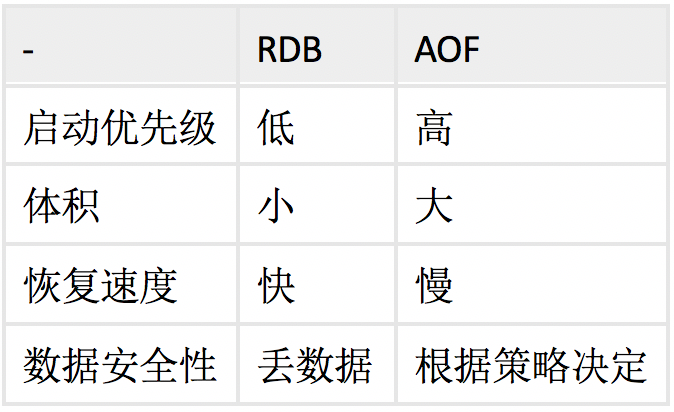
3、RDB 和 AOF 对比