1.HashMap工作原理
2.HashMap容量为2次幂的原因
我们先来说一下hash算法,我们可以看到在hashmap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过hashmap的数据结构是数组和链表的结合,所以我们当然希望这个hashmap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
所以我们首先想到的就是把hashcode对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,能不能找一种更快速,消耗更小的方式那?java中时这样做的:
1 static int indexFor(int h, int length) { 2 return h & (length-1); 3 }
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!

所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面annegu的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。
zjp: HashMap中是如何得到元素在数组中的位置的呢?在hashmap源码中,首先通过key.hashcode()得到hash值,然后与(数组的长度-1)作与运算。只有当数组的长度为2的n次幂时,数组的长度-1然后进行与运算才能得到每一位都是1的值,保证数组的每一位都可以利用到,如果得到的值在某一位为0,这样可能导致不能完全的对数组使用,造成数据分配不均的问题。
3.HashMap的resize
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1024 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
zjp: 当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置.
4.HashMap并发状态下扩容出现的死循环问题(java1.7)
hashmap用数组+链表。数组是固定长度,链表太长就需要扩充数组长度进行rehash减少链表长度。如果两个线程同时触发扩容,在移动节点时会导致一个链表中的2个节点相互引用,从而生成循环链表。
HashMap的方法不是线程安全的。HashMap在并发执行put操作时发生扩容,可能会导致节点丢失,产生环形链表等情况。 节点丢失,会导致数据不准 生成环形链表,会导致get()方法死循环。
知识拓展
在jdk1.7中,由于扩容时使用头插法,在并发时可能会形成环状链表,导致死循环,在jdk1.8中改为尾插法,可以避免这种问题,但是依然避免不了节点丢失的问题。
5.HashMap和ConcurrentHashMap的区别
1.在jdk1.7版本中,ConcurrentHashmap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用Lock锁进行保护,相对于Hashtable的全局Synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。( 到了 JDK1.8 的时候ConcurrentHashmap摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。)
2.HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
6.Hashtable和ConcurrentHashMap的区别
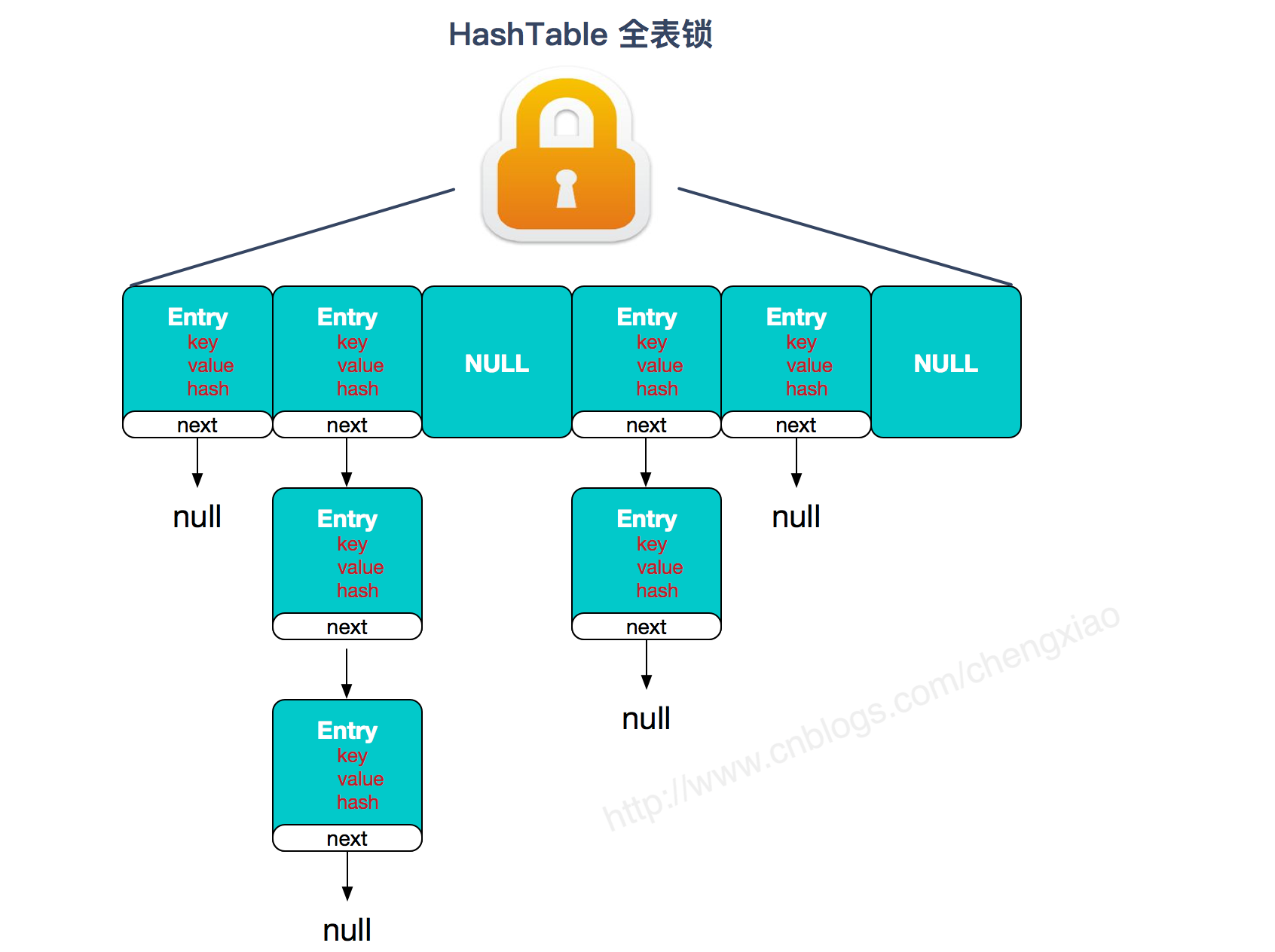
主要区别是实现线程安全的方式: ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :整个表结构共用一把锁,使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
7.HashMap和Hashtable和ConcurrentHashMap的区别
ConcurrentHashMap 结合了 HashMap 和 HashTable 二者的优势。HashMap 没有考虑同步,HashTable 考虑了同步的问题。但是 HashTable 在每次同步执行时都要锁住整个结构。 ConcurrentHashMap 锁的方式是稍微细粒度的。
8.对比图
HashTable:
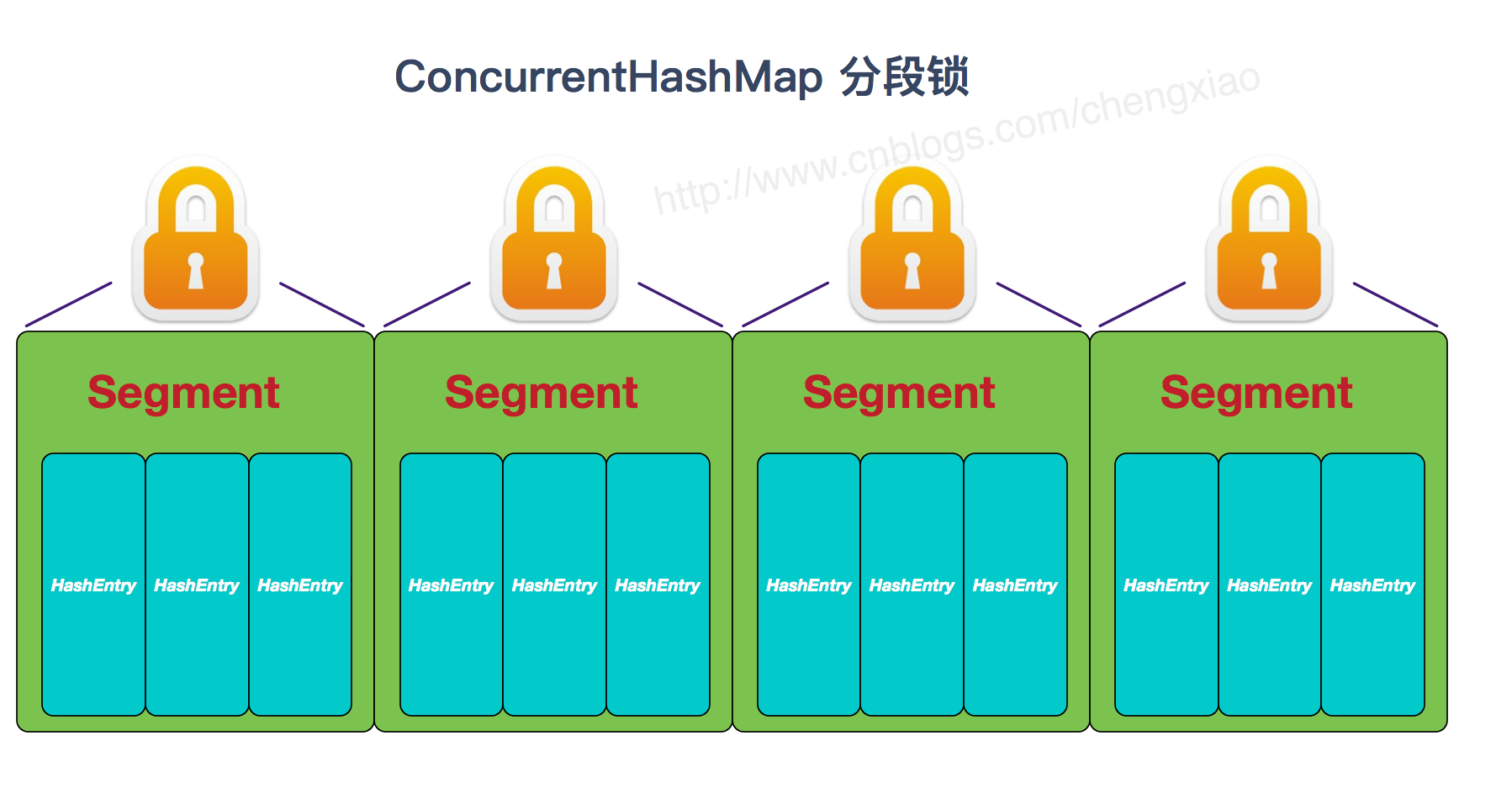
JDK1.7的ConcurrentHashMap:
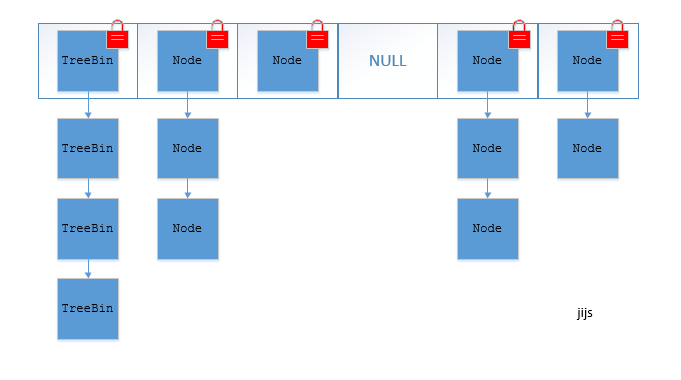
JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):
答:ConcurrentHashMap 结合了 HashMap 和 HashTable 二者的优势。HashMap 没有考虑同步,HashTable 考虑了同步的问题。但是 HashTable 在每次同步执行时都要锁住整个结构。 ConcurrentHashMap 锁的方式是稍微细粒度的。
9 ConcurrentHashMap 底层具体实现知道吗?实现原理是什么?
JDK1.7
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
在JDK1.7中,ConcurrentHashMap采用Segment + HashEntry的方式进行实现,结构如下:
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
- 该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色;
- Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
JDK1.8
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
结构如下:
10.为什么重写了equals,一定要重写hashcode()?
通俗的讲,就是equals()和hashcode()方法要保持相当程度的一致性,equals()方法相等,hashcode()必须相等;反之,equals方法不相等,hashcode可以相等,可以不相等。但是两者的一致有利于提高哈希表的性能。所以,源码注释来看,两方法的同时重写是很必要的。
就举最简单的例子,假定HashMap中以String为key,即HashMap<String,Object>,如果String只重写了equals方法,没有重写hashCode方法,同时put两个键完全相同的键值对,类似<"aaa", Object1>、<"aaa", Object2>, 则不会进行覆盖操作,即object2替换object1,而是会进行两次添加操作。因为HashMap,hash值的计算完全依赖于key的hashCode值,如果没有重写hashCode方法,就会调用object的hashcode()方法,这个方法是根据对象的地址生成的hash值。会导致两个字符串对象映射到hash表中的不同位置。