前言:最近准备换工作,想全面复习一下学过的知识点。看到这篇文章感觉还不错。
一、逻辑架构图
MySQL逻辑架构整体分为四层:

第一层:是链接线程处理,这一层并非MySQL独有,在这一层中,主要功能有链接处理,授权验证,安全等操作。
第二层:是MySQL主要层,所有的语句解析、分析、优化和缓存都在这一层进行,同时内建函数,如日期、时间等函数也在这一层进行。
第三层:中所有的跨存储引擎的功能都在该层完成,例如视图、存储过程等。
第四层:为存储引擎,负责数据的获取和存储。在该层提供了许多API供上层服务层调用,完成数据操作。
工作过程:
每一个客户端发起一个新的请求都会由服务器端的连接线程处理层接收客户端的请求并开辟一个新的内存空间,在该空间内生成一个新的线程,当,当每一个用户连接到服务器端的时候就会在进程地址空间内生成一个新的线程用于响应客户端请求,用户发起的查询请求都在线程空间内运行,结果也在这里面缓存并返回给服务器端。最后线程的销毁和重用都是由连接线程处理管理器完成的。
二、MySQL查询过程
如下图所示:
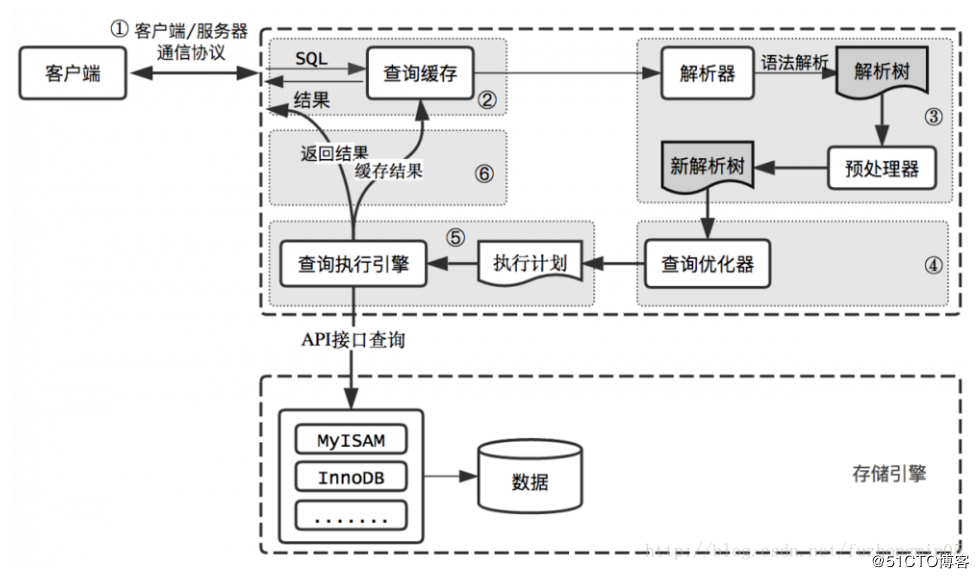
1、客户端/服务器通信协议
该部分为半双工状态,要么是客户端向服务器发送数据,要么是服务器向半双工发送数据,二者不能同时进行。
当客户端向服务器发送数据时以单独一个数据包的形式发送,若查询太大,服务器会拒绝接收更多的数据,并抛出异常;
当服务器端向客户端发送数据包时,一般包括多个数据包。客户端必须完整的接收所有的数据,不能拒绝接收部分数据只获取前几条。在开发过程中应该尽量保持简单和必要的查询,这也是减少select *和加上limit限制的原因。
2、查询缓存
在解析查询语句之前,如果开启了查询缓存,MySQL会检查当前查询是否命中缓存中的数据,如果命中会直接将缓存中的数据响应给客户端,否则会执行后面的解析等操作。
MySQL的缓存存放在一个引用表中,以一个哈希值作为索引。该索引包含了一系列与查询有关的信息,例如查询本身、要查询的表等。如果两个查询在任何一个字符上有所不同就不会命中缓存。当然,不是所有的查询都会存在缓存中,当查询语句中包含函数、用户变量、临时表时就不会存入缓存。例如,一个查询语句中包含NOW()函数,不同的时间查询会有不同的查询结果,存入缓存毫无意义,所以该查询就不会被存入缓存。
MySQL的缓存也存在失效的状态,所有会影响查询结果的信息都会糅合进一个哈希值作为索引,所以当某一个表的数据或者结构发生变化时,该表所涉及到的所有缓存都会失效。即对某表执行写操作时,该表所涉及到的缓存就会被设置为失效。当查询缓存非常大时,这个操作会造成较大的系统消耗。在读操作时,每一个查询语句执行前都会检查是否命中缓存,执行后都会存入缓存。是否打开缓存应慎之又慎。
3、语法解析及预处理
语法解析会将查询语句进行解析生成一颗解析树,这个过程主要是通过语法进行检查。预处理会将解析树再次进行解析,会检查查询所包含的表、列等是否存在。
4、查询优化
一条语句有多中实现方式,优化器的作用就是评估某种执行成本并且选择成本最小的那一个。当然,我们所预想的执行方式,不一定就是MySQL真正的执行方式。优化器会对执行顺序进行重新排序并执行,选出MySQL认为的最优解。
MySQL的查询优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划: 1. 重新定义表的关联顺序(多张表关联查询时,并不一定按照SQL中指定的顺序进行,但有一些技巧可以指定关联顺序)
2. 优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值,具体原理见下文)
3. 提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
4. 优化排序(在老版本MySQL会使用两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行,而新版本采用的是单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型应用,效率会高很多)
5、查询执行引擎
查询执行引擎会根据优化阶段生成的执行计划,依次执行并给出结果。这些主要实现方式是通过调用存储引擎的API实现,这些API提供了强大的功能,通过叠加等操作实现查询。
6、响应给客户端
无论是否有查询结果,都会返回给客户端,包括影响到行数、执行时长等等。
此时若查询缓存打开,会将查询结果存入缓存。
当有查询结果时,返回的结果集是一个增量过程。mysql可能在生成的第一条结果时就会将结果返回给客户端,客户端不断接收直至完毕。服务端无需存储结果集占用内存客户端也可以第一时间接收到结果。