一文读懂机器阅读理解
机器阅读理解(Machine Reading Comprehension,MRC)是一种利用算法使计算机理解文章语义并回答相关问题的技术。由于文章和问题均采用人类语言的形式,因此机器阅读理解属于自然语言处理(NLP)的范畴,也是其中最新最热门的课题之一。近些年来,随着机器学习,特别是深度学习的发展,机器阅读理解研究有了长足的进步,并在实际应用中崭露头角。
任务介绍
学者C. Snow在2002年的一篇论文中定义阅读理解是“通过交互从书面文字中提取与构造文章语义的过程”。而机器阅读理解的目标是利用人工智能技术,使计算机具有和人类一样理解文章的能力。图1给出了一个机器阅读理解的样例。其中,模型需要用文章中的一段原文回答问题。

图1 机器阅读理解任务样例
大部分机器阅读理解任务采用问答式测评:设计与文章内容相关的自然语言式问题,让模型理解问题并根据文章作答。为了评判答案的正确性,一般有如下几种形式的参考答案:
多项选择式,即模型需要从给定的若干选项中选出正确答案;
区间答案式,即答案限定是文章的一个子句,需要模型在文章中标明正确的答案起始位置和终止位置;
自由回答式,即不限定模型生成答案的形式,允许模型自由生成语句;
完形填空式,即在原文中除去若干关键词,需要模型填入正确单词或短语。
此外,一些数据集设计了“无答案”问题,即一个问题可能在文章中没有合适答案,需要模型输出“无法回答”(unanswerable)。
在以上的答案形式中,多项选择和完形填空属于客观类答案,测评时可以将模型答案直接与正确答案比较,并以准确率作为评测标准,易于计算。
基本框架
早期的阅读理解模型大多基于检索技术,即根据问题在文章中进行搜索,找到相关的语句作为答案。但是,信息检索主要依赖关键词匹配,而在很多情况下,单纯依靠问题和文章片段的文字匹配找到的答案与问题并不相关。随着深度学习的发展,机器阅读理解进入了神经网络时代。相关技术的进步给模型的效率和质量都带来了很大的提升。机器阅读理解模型的准确率不断提高,在一些数据集上已经达到或超过了人类的平均水平。
基于深度学习的机器阅读理解模型虽然构造各异,但是经过多年的实践和探索,逐渐形成了稳定的框架结构。机器阅读理解模型的输入为文章和问题。因此,首先要对这两部分进行数字化编码,变成可以被计算机处理的信息单元。在编码的过程中,模型需要保留原有语句在文章中的语义。因此,每个单词、短语和句子的编码必须建立在理解上下文的基础上。我们把模型中进行编码的模块称为编码层。
接下来,由于文章和问题之间存在相关性,模型需要建立文章和问题之间的联系。例如,如果问题中出现关键词“河流”,而文章中出现关键词“长江”,虽然两个词不完全一样,但是其语义编码接近。因此,文章中“长江”一词以及邻近的语句将成为模型回答问题时的重点关注对象。这可以通过自然语言处理中的注意力机制加以解决。在这个过程中,阅读理解模型将文章和问题的语义结合在一起进行考量,进一步加深模型对于两者各自的理解。我们将这个模块称为交互层。
经过交互层,模型建立起文章和问题之间的语义联系,就可以预测问题的答案。完成预测功能的模块称为输出层。由于机器阅读理解任务的答案有多种类型,因此输出层的具体形式需要和任务的答案类型相关联。此外,输出层需要确定模型优化时的评估函数和损失函数。
图2是机器阅读理解模型的一般架构。可以看出,编码层用于对文章和问题分别进行底层处理,将文本转化成为数字编码。交互层可以让模型聚焦文章和问题的语义联系,借助于文章的语义分析加深对问题的理解,同时也借助于问题的语义分析加深对文章的理解。输出层根据语义分析结果和答案的类型生成模型的答案输出。
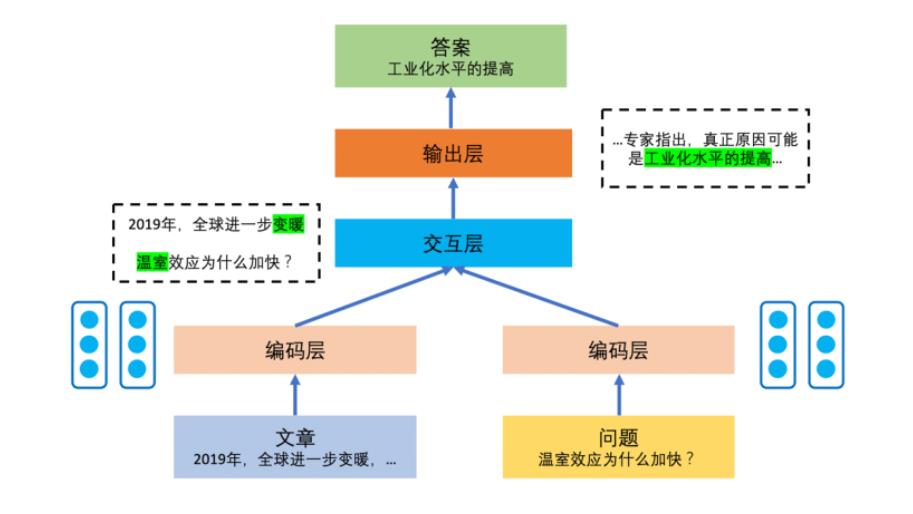
图2 机器阅读理解模型的总体架构,输出层以区间式答案为例
相关模型
在基本框架的指引下,众多优秀的机器阅读理解模型脱颖而出。这些模型在网络架构、模块设计、训练方法等方面实现了各种创新,大大提高了算法理解文本和问题的能力和预测答案的准确性,在诸多机器阅读理解数据集和竞赛中取得了非常优秀的成绩。其中具有代表性的模型有:双向注意力流(BiDAF),使用门机制的R-net、融合网络(FusionNet)等。
而近期非常流行的预训练模型给机器阅读理解领域带来了革命性的改变。预训练方法源于机器学习中迁移学习的概念:为了完成一个学习任务,首先在其他相关任务上预训练模型,然后将模型在目标任务上进一步优化,实现模型所学知识的迁移。预训练模型最大的好处是,可以克服目标任务(如机器阅读理解)数据不足的问题,利用大量其他任务的数据,建立有效的模型再迁移到目标任务,大大提高了模型的准确度。这其中最具有代表性的便是Google 于2018年提出的双向编码器模型BERT。BERT采用无监督学习在大规模语料上进行预训练,并创新性地利用掩码设计与判断下一段文本两个子任务增强了模型的语言能力。在论文作者开源了代码和预训练模型后,BERT立即被研究者运用在各种NLP任务中,并频繁大幅刷新之前的最好结果。例如,在SQuAD 2.0竞赛中,排名前20名的模型全部基于BERT;CoQA竞赛中,前10名模型全部基于BERT。并且这两个竞赛中模型的最好表现已经超越人类水平。
工业界应用
机器阅读理解利用人工智能技术为计算机赋予了阅读、分析和归纳文本的能力。随着信息时代的到来,文本的规模呈爆炸式发展。因此,机器阅读理解带来的自动化和智能化恰逢其时,在众多工业界领域和人们生活中的方方面面都有着广阔的应用空间。
客服机器人是一种基于自然语言处理的拟人式服务,通过文字或语音与用户进行多轮交流,获取相关信息并提供解答。机器阅读理解可以帮助客服系统根据用户提供的信息在产品文档中快速找到解决方案,如图3所示。

图3 客服机器人与用户与产品文档的关系
智能法律用于自动处理和应用各种错综复杂的法律法规实现对案例的自动审判,这正可以利用机器阅读理解在处理和分析大规模文档方面的速度优势。
智能教育利用计算机辅助人类的学习过程。机器阅读理解在这个领域的典型应用是作文自动批阅。自动作文批阅模型可以作为学生写作时的助手,理解作文语义,自动修改语法错误,个性化总结易错知识点。这些技术与当前流行的在线教育结合,很有可能在不久的将来对教育行业产生颠覆性的影响。
展望未来,机器阅读理解研究仍面临如知识与推理能力、可解释性、缺乏训练数据等挑战,但也有很大的应用空间。基于机器阅读理解高速处理大量文本的特点,这项技术最容易在劳动密集型文本处理行业落地。而在其产业化的进程中,可以有部分替代人类和完全替代人类两种模式。部分替代人类模式是指模型的质量没有完全达到可接受的水平,但是可以很好地处理简单高频的场景,然后由人类接力处理。而在作文自动批阅等需要模型独立完成任务的场景中,可以使用强化学习等手段根据用户的反馈不断改进模型的架构和参数,得到更好的表现。
在今后的发展中,一方面,机器阅读理解可以在自然语言理解已获得成功的深耕领域进一步细分与提升质量,如搜索引擎、广告、推荐等;另一方面,我们相信,随着机器阅读理解技术的不断进步,机器与人类的差距会不断缩小,我们必将迎来技术的奇点,使得这项技术对更多的行业产生革命性的影响。