一.注解配置
1.Column的属性
@Target({METHOD, FIELD}) @Retention(RUNTIME) public @interface Column { /** * (Optional) The name of the column. Defaults to * the property or field name. */ String name() default ""; /** * (Optional) Whether the column is a unique key. This is a * shortcut for the <code>UniqueConstraint</code> annotation at the table * level and is useful for when the unique key constraint * corresponds to only a single column. This constraint applies * in addition to any constraint entailed by primary key mapping and * to constraints specified at the table level. */ boolean unique() default false; /** * (Optional) Whether the database column is nullable. */ boolean nullable() default true; /** * (Optional) Whether the column is included in SQL INSERT * statements generated by the persistence provider. */ boolean insertable() default true; /** * (Optional) Whether the column is included in SQL UPDATE * statements generated by the persistence provider. */ boolean updatable() default true; /** * (Optional) The SQL fragment that is used when * generating the DDL for the column. * <p> Defaults to the generated SQL to create a * column of the inferred type. */ String columnDefinition() default ""; /** * (Optional) The name of the table that contains the column. * If absent the column is assumed to be in the primary table. */ String table() default ""; /** * (Optional) The column length. (Applies only if a * string-valued column is used.) */ int length() default 255; /** * (Optional) The precision for a decimal (exact numeric) * column. (Applies only if a decimal column is used.) * Value must be set by developer if used when generating * the DDL for the column. */ int precision() default 0; /** * (Optional) The scale for a decimal (exact numeric) column. * (Applies only if a decimal column is used.) */ int scale() default 0; }
(1) name 可选,列名(默认值是属性名)
a.columnDefinition属性
column注解中的columnDefinition属性用于覆盖数据库DDL中的语句:(MySql)
@Column(columnDefinition = "int(11) DEFAULT NULL COMMENT '类型'") public Integer getType() { return type; }
因此,又可以为该列添加comment注释。
然而,columnDefinition不推荐使用,因为可能导致移植性不好,各个数据库不兼容等。
b.如何设置列默认值?
@Column(name="C_NAME",length=40) private String name="nnnn";
直接在bean中赋值即可。
c.oracle中char 和byte如何选择?
varchar2最大长度为4000。
d.char,varchar,varchar2区别
1.CHAR的长度是固定的,而VARCHAR2的长度是可以变化的, 比如,存储字符串“abc",对于CHAR (20),表示你存储的字符将占20个字节(包括17个空字符),而同样的VARCHAR2 (20)则只占用3个字节的长度,20只是最大值,当你存储的字符小于20时,按实际长度存储。
2.CHAR的效率比VARCHAR2的效率稍高。
3.目前VARCHAR是VARCHAR2的同义词。工业标准的VARCHAR类型可以存储空字符串,但是oracle不这样做,尽管它保留以后这样做的权利。Oracle自己开发了一个数据类型VARCHAR2,这个类型不是一个标准的VARCHAR,它将在数据库中varchar列可以存储空字符串的特性改为存储NULL值。如果你想有向后兼容的能力,Oracle建议使用VARCHAR2而不是VARCHAR。
4.VARCHAR2虽然比CHAR节省空间,但是如果一个VARCHAR2列经常被修改,而且每次被修改的数据的长度不同,这会引起‘行迁移’(Row Migration)现象,而这造成多余的I/O,是数据库设计和调整中要尽力避免的,在这种情况下用CHAR代替VARCHAR2会更好一些。
e.precision与scale
NUMBER[(precision[,scale])] 存储零,正数和负数。
precision 是总共的数字位数,默认是38位十进制数——最大的数。
scale是小数点右边的数,默认是零。
比如:
pay NUMBER 和pay NUMBER (38,0)意思一样。
一个正数的scale告诉数据库,小数点右边结束的位数。scale的合法范围是-84~127.
scale为负数的意思是说从小数点前面的第几个数开始四舍五入。
要重新设置精度,必须清空该列。
precision的精度范围是指经过四舍五入后的精度。比如定义number(3,1),则12.3456 ->12.3不会报错;而123.4则报错,因为四舍五入后为123.4超过precision范围。
Integer 定义Number(10,0)
Long的话直接定义成Number(38,0)即可。
f.Oracle中Date和Timestamp区别
DATE数据类型的主要问题是它粒度不能足够区别出两个事件哪个先发生。ORACLE已经在DATE数据类型上扩展出来了TIMESTAMP数据类型,它包括了所有DATE数据类型的年月日时分秒的信息,而且包括了小数秒的信息
g.其他
Clob,Blob
CLOB使用CHAR来保存数据。 如:保存XML文档。
BLOB就是使用二进制保存数据。 如:保存位图。
2.注解定义Bean
参考:http://hi.baidu.com/wjx_5893/item/7b773aab2acbf217a9cfb7fe
和http://blog.163.com/lidan_grace/blog/static/5669483720113285648242/
1、@Entity(name="EntityName")
必须,name为可选,对应数据库中一的个表
2、@Table(name="",catalog="",schema="")
可选,通常和@Entity配合使用,只能标注在实体的class定义处,表示实体对应的数据库表的信息
name:可选,表示表的名称.默认地,表名和实体名称一致,只有在不一致的情况下才需要指定表名
catalog:可选,表示Catalog名称,默认为Catalog("").
schema:可选,表示Schema名称,默认为Schema("").
注:一个数据库通常包含多个catalog,一个catalog包含多个schema
3.主键设置
@id定义了映射到数据库表的主键的属性.
详细的主键生成策略见http://hi.baidu.com/wjx_5893/item/7b773aab2acbf217a9cfb7fe
4.@Transient
可选
@Transient表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性.
如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,ORM框架默认其注解为@Basic
示例:
//根据birth计算出age属性
@Transient
public int getAge() {
return getYear(new Date()) - getYear(birth);
}
5.@Basic(fetch=FetchType,optional=true)
可选
@Basic 表示一个简单的属性到数据库表的字段的映射 , 对于没有任何标注的 getXxxx() 方法 , 默认即为 @Basic
fetch: 表示该属性的读取策略 , 有 EAGER 和 LAZY 两种 , 分别表示主支抓取和延迟加载 , 默认为 EAGER.
optional: 表示该属性是否允许为 null, 默认为 true
示例 :
@Basic(optional=false)
public String getAddress() {
return address;
}
3.关联映射
关联关系映射通常情况是最难配置正确的。在这个部分中,我们从单向关系映射开始,然后考虑双向关系映射,逐步讲解典型的案例。
a.@ManyToOne
表示一个多对一的映射,该注解标注的属性通常是数据库表的外键
optional:是否允许该字段为null,该属性应该根据数据库表的外键约束来确定,默认为true (optional表示该字段是否是可选的)
fetch:表示抓取策略,默认为FetchType.EAGER (FetchType.LAZY,FetchType.EAGER)
cascade:表示默认的级联操作策略,可以指定为ALL,PERSIST,MERGE,REFRESH和REMOVE中的若干组合,默认为无级联操作多个属性用cascade={CascadeType.MERGE,CascadeType.REFRESH}来写
targetEntity:表示该属性关联的实体类型.该属性通常不必指定,ORM框架根据属性类型自动判断targetEntity.
b. Cascade详解
CascadeType.MERGE级联更新:若items属性修改了那么order对象保存时同时修改items里的对象。对应EntityManager的merge方法
CascadeType.REFRESH级联刷新:获取order对象里也同时也重新获取最新的items时的对象。对应EntityManager的refresh(object)方法有效。即会重新查询数据库里的最新数据
CascadeType.PERSIST级联保存:对order对象保存时也对items里的对象也会保存。对应EntityManager的presist方法
CascadeType.REMOVE级联删除:对order对象删除也对items里的对象也会删除。对应EntityManager的remove方法
CascadeType.PERSIST只有A类新增时,会级联B对象新增。若B对象在数据库存(跟新)在则抛异常(让B变为持久态)
CascadeType.MERGE指A类新增或者变化,会级联B对象(新增或者变化)
CascadeType.REMOVE只有A类删除时,会级联删除B类;
CascadeType.ALL包含所有;
CascadeType.REFRESH没用过。
综上:大多数情况用CascadeType.MERGE就能达到级联跟新又不报错,用CascadeType.ALL时要斟酌下CascadeType.REMOVE
c.@JoinColumn
@JoinColumn和@Column类似,介量描述的不是一个简单字段,而一一个关联字段,例如.描述一个@ManyToOne的字段.
name:该字段的名称.由于@JoinColumn描述的是一个关联字段,如ManyToOne,则默认的名称由其关联的实体决定.
d.@OneToMany
描述一个一对多的关联,该属性应该为集体类型,在数据库中并没有实际字段.
fetch:表示抓取策略,默认为FetchType.LAZY,因为关联的多个对象通常不必从数据库预先读取到内存
cascade:表示级联操作策略,对于OneToMany类型的关联非常重要,通常该实体更新或删除时,其关联的实体也应当被更新删除
例如:实体User和Order是OneToMany的关系,则实体User被删除时,其关联的实体Order也应该被全部删除
e.mappedBy
a) 只有OneToOne,OneToMany,ManyToMany上才有mappedBy属性,ManyToOne不存在该属性;
b) mappedBy标签一定是定义在the owned side(被拥有方的),他指向the owning side(拥有方);
c) mappedBy的含义,应该理解为,拥有方能够自动维护 跟被拥有方的关系;
当然,如果从被拥有方,通过手工强行来维护拥有方的关系也是可以做到的。
d) mappedBy跟JoinColumn/JoinTable总是处于互斥的一方,可以理解为正是由于拥有方的关联被拥有方的字段存在,拥有方才拥有了被 拥有方。mappedBy这方定义的JoinColumn/JoinTable总是失效的,不会建立对应的字段或者表
f.@JoinTable
2.1单向关联多对一
@Entity @Table(name="T_ACCOUNT") public class Account implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=160,nullable=false) private String name; }
@Entity @Table(name="T_MESSAGE" ) public class Message implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @ManyToOne @JoinColumn(name="C_ACCOUNT_ID") private Account account;
}
一个account拥有多个message
2.2单向关联一对一
@Entity @Table(name="T_ACCOUNT") public class Account implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=160,nullable=false) private String name;
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name="C_PERSON_ID")
private Person person; }
@Entity @Table(name="T_PERSON" ) public class Person implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=40) private String name; @OneToOne(mappedBy = "person") private Account account; }
2.3双向关联多对一
@Entity @Table(name="T_ACCOUNT") public class Account implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=160,nullable=false) private String name;
@OneToMany(cascade = { CascadeType.ALL }, mappedBy = "account")
private Set<Message> messages;
}
@Entity @Table(name="T_MESSAGE" ) public class Message implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @ManyToOne @JoinColumn(name="C_ACCOUNT_ID") private Account account; }
一个account拥有多个message
2.4自关联
@Entity @Table(name="T_CATEGORY") public class Category implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=200) private String name; @ManyToOne @JoinColumn(name = "C_PARENT_ID") private Category parent; @OneToMany(cascade = { CascadeType.ALL }, mappedBy = "parent") @OrderBy("weight") private Set<Category> children;
}
2.5双向多对多关联(有连接表)
@Entity @Table(name="T_ROLE" ) public class Role implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=100) private String name; @ManyToMany(targetEntity=Right.class) @JoinTable(name="T_ROLE_RIGHT", joinColumns={@JoinColumn(name="C_ROLE_ID")}, inverseJoinColumns={@JoinColumn(name="C_RIGHT_ID")}) private Set<Right> rights; }
@Entity @Table(name="T_RIGHT" ) public class Right implements java.io.Serializable { @Id @Column(name="C_ID",length=40) @GeneratedValue(generator="idGenerator") @GenericGenerator(name="idGenerator", strategy="uuid") private String id; @Column(name="C_NAME",length=100) private String name; @ManyToMany(targetEntity=Role.class, mappedBy="rights") private Set<Role> roles; }
4.对象生命周期
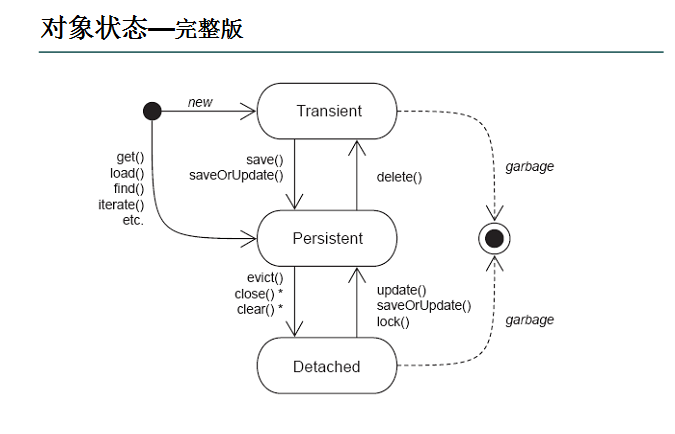
4.1get()和load()区别
1.从返回结果上对比:
load方式检索不到的话会抛出org.hibernate.ObjectNotFoundException异常
get方法检索不到的话会返回null
2.从检索执行机制上对比: get方法和find方法都是直接从数据库中检索 而load方法的执行则比较复杂首先查找session的persistent Context中是否有缓存,如果有则直接返回 如果没有则判断是否是lazy,如果不是直接访问数据库检索,查到记录返回,查不到抛出异常 如果是lazy则需要建立代理对象,对象的initialized属性为false,target属性为null 在访问获得的代理对象的属性时,检索数据库,如果找到记录则把该记录的对象复制到代理对象的target上,并将initialized=true,如果找不到就抛出异常。
3.根本区别说明
如果你使用load方法,hibernate认为该id对应的对象(数据库记录)在数据库中是一定存在的,所以它可以放心的使用,它可以放心的使用代理来 延迟加载该对象。在用到对象中的其他属性数据时才查询数据库,但是万一数据库中不存在该记录,那没办法,只能抛异常。所说的load方法抛异常是指在使用 该对象的数据时,数据库中不存在该数据时抛异常,而不是在创建这个对象时(注意:这就是由于“延迟加载”在作怪)。
由于session中的缓存对于hibernate来说是个相当廉价的资源,所以在load时会先查一下session缓存看看该id对应的对象是否存在,不存在则创建代理。所以如果你知道该id在数据库中一定有对应记录存在就可以使用load方法来实现延迟加载。
对于get方法,hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查数据库,数据库中没有就返回null。
对于load和get方法返回类型:虽然好多书中都这么说:“get()永远只;实体类”,但实际上这是不正确的,get方法如果在 session缓存中找到了该id对应的对象,如果刚好该对象前面是被代理过的,如被load方法使用过,或者被其他关联对象延迟加载过,那么返回的还是 原先的代理对象,而不是实体类对象,如果该代理对象还没有加载实体数据(就是id以外的其他属性数据),那么它会查询二级缓存或者数据库来加载数据,但是 返回的还是代理对象,只不过已经加载了实体数据。
get方法首先查询session缓存,没有的话查询二级缓存,最后查询数据库;反而load方法创建时首先查询session缓存,没有就创建代理,实际使用数据时才查询二级缓存和数据库。
4.简单总结
总之对于get和load的根本区别,一句话,hibernate对于load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方法,hibernate一定要获取到真实的数据,否则返回null。
4.2merge
merge的作用是:新new一个对象,如果该对象设置了ID,则这个对象就当作游离态处理: 当ID在数据库中不能找到时,用update的话肯定会报异常(org.hibernate.NonUniqueObjectException: a different object with the same identifier value was already associated with the session : ),然而用merge的话,就会insert。 当ID在数据库中能找到的时候,update与merge的执行效果都是更新数据,发出update语句。
用merge的话,它会把第一个的对象数据赋值给已经处于持久化的那个对象中,自己本身不得变为持久态;
4.3flush
该方法进行清理缓存的操作,执行一系列的SQL语句,但不提交事务。由此可见该方法提前将SQL缓冲区的SQL语句发送到数据库中。另外执行flush方法时Hibernate会对当前所操作的对象加锁,且该锁为行级别锁,防止其他事务对当前对象脏读。
4.4evict
清除指定的缓存对象。session.evict(ohj)
4.5clear
该方法会强制清空当前session中的缓存 。
5.事务控制
5.1Spring事务的传播行为
在service类前加上@Transactional,声明这个service所有方法需要事务管理。每一个业务方法开始时都会打开一个事务。
Spring默认情况下会对运行期例外(RunTimeException)进行事务回滚。这个例外是unchecked
如果遇到checked意外就不回滚。
如何改变默认规则:
1 让checked例外也回滚:在整个方法前加上 @Transactional(rollbackFor=Exception.class)
2 让unchecked例外不回滚: @Transactional(notRollbackFor=RunTimeException.class)
3 不需要事务管理的(只查询的)方法:@Transactional(propagation=Propagation.NOT_SUPPORTED)
在整个方法运行前就不会开启事务 .
还可以加上:@Transactional(propagation=Propagation.NOT_SUPPORTED,readOnly=true),这样就做成一个只读事务,可以提高效率。
propagation.属性含义:
REQUIRED:业务方法需要在一个容器里运行。如果方法运行时,已经处在一个事务中,那么加入到这个事务,否则自己新建一个新的事务。
NOT_SUPPORTED:声明方法不需要事务。如果方法没有关联到一个事务,容器不会为他开启事务,如果方法在一个事务中被调用,该事务会被挂起,调用结束后,原先的事务会恢复执行。
REQUIRESNEW:不管是否存在事务,该方法总汇为自己发起一个新的事务。如果方法已经运行在一个事务中,则原有事务挂起,新的事务被创建。
MANDATORY:该方法只能在一个已经存在的事务中执行,业务方法不能发起自己的事务。如果在没有事务的环境下被调用,容器抛出例外。
SUPPORTS:该方法在某个事务范围内被调用,则方法成为该事务的一部分。如果方法在该事务范围外被调用,该方法就在没有事务的环境下执行。
NEVER:该方法绝对不能在事务范围内执行。如果在就抛例外。只有该方法没有关联到任何事务,才正常执行。
NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务,则按REQUIRED属性执行。它使用了一个单独的事务,这个事务拥有多个可以回滚的保存点。内部事务的回滚不会对外部事务造成影响。它只对DataSourceTransactionManager事务管理器起效。
6.Session
详细:http://aixiangct.blog.163.com/blog/static/9152246120113652732924/