引言 前段时间答应朋友做一个hadoop分析日志的教程,说完就后悔了,我已经很久没碰它了,为了实现这个承诺不得以又把以前买的书找出来研究一下。值得庆幸的是以前的笔记还在不需要我从头再来。不过搭建hadoop的环境很复杂,我也不准备做从零开始的教程,我准备把我搭建好的环境直接搬过来了,这样不用纠结环境搭建的复杂,也不需要了解Map/Reducer编程就可以直接体验一下hadoop的魅力。
环境准备
| 序号 | 环境和数据 | 版本 | 下载地址 |
| 1 | CentOS-8.3.2011-x86_64-minimal.iso | 8.3 |
链接: https://pan.baidu.com/s/1kWRffCoup2Oxat953ZAe5w 提取码: ml2e |
| 2 | hadoop-2.6.4.tar.gz | 2.6.4 |
链接: https://pan.baidu.com/s/1A_fqViL62xrZ6rnA1M8nYQ 提取码: nfna |
| 3 | jdk-7u80-linux-x64.rpm | 1.7 |
链接: https://pan.baidu.com/s/1sGneDO4jcfk5ZlbOLVZVpA 提取码: 5nmj |
| 4 | access.txt |
链接: https://pan.baidu.com/s/1aKlVcXrrWo5kEmoWa7DD8Q 提取码: 5bgu |
注意:请一定使用以上的地址下载的,不然可能出现很多未知的问题。hadoop-2.6.4.tar.gz 配置文件是我改过的,access.txt 是用来测试的tomcat日志数据。
第一步 使用虚拟机软件安装操作系统(没有装过的同学可以去补下课,这里就不讲了)
第二步 操作系统安装好后,先关闭防火墙顺便安装一下vim,具体操作如下:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
yum -y install vim #安装vim
第三步 使用上面的下载地址下载jdk1.7上传到刚才创建的centos8.3虚拟机使用命令安装(这里一定要使用rpm安装因为这个安装目录是固定的)安装目录为/usr/java/jdk1.7.0_80 这个jdk的目录已经被我写在hadoop配置中。安装命令如下
rpm -ivh jdk-7u80-linux-x64.rpm #rpm 安装jdk
java -version #查看安装是否成功
第四步 使用上面地址下载hadoop-2.6.4.tar.gz(注意这个包基本配置都是配置好的,不需要做调整的) 包 然后解压到 /usr/local 目录下 解压命令如下
tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
第五步 编辑 /etc/profile 文件添加内容如下
vim /etc/profile # 打开文件编辑 # 在文件尾部追加以下内容 export JAVA_HOME=/usr/java/jdk1.7.0_80 export JRE_HOME=$JAVA_HOME/jre export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/jre export HADOOP_HOME=/usr/local/hadoop-2.6.4/bin export PATH=$PATH:$HADOOP_HOME
source /etc/profile #保存文件后执行
完成后 执行 hadoop 或者hdfs 命令看看是否成功 正确结果如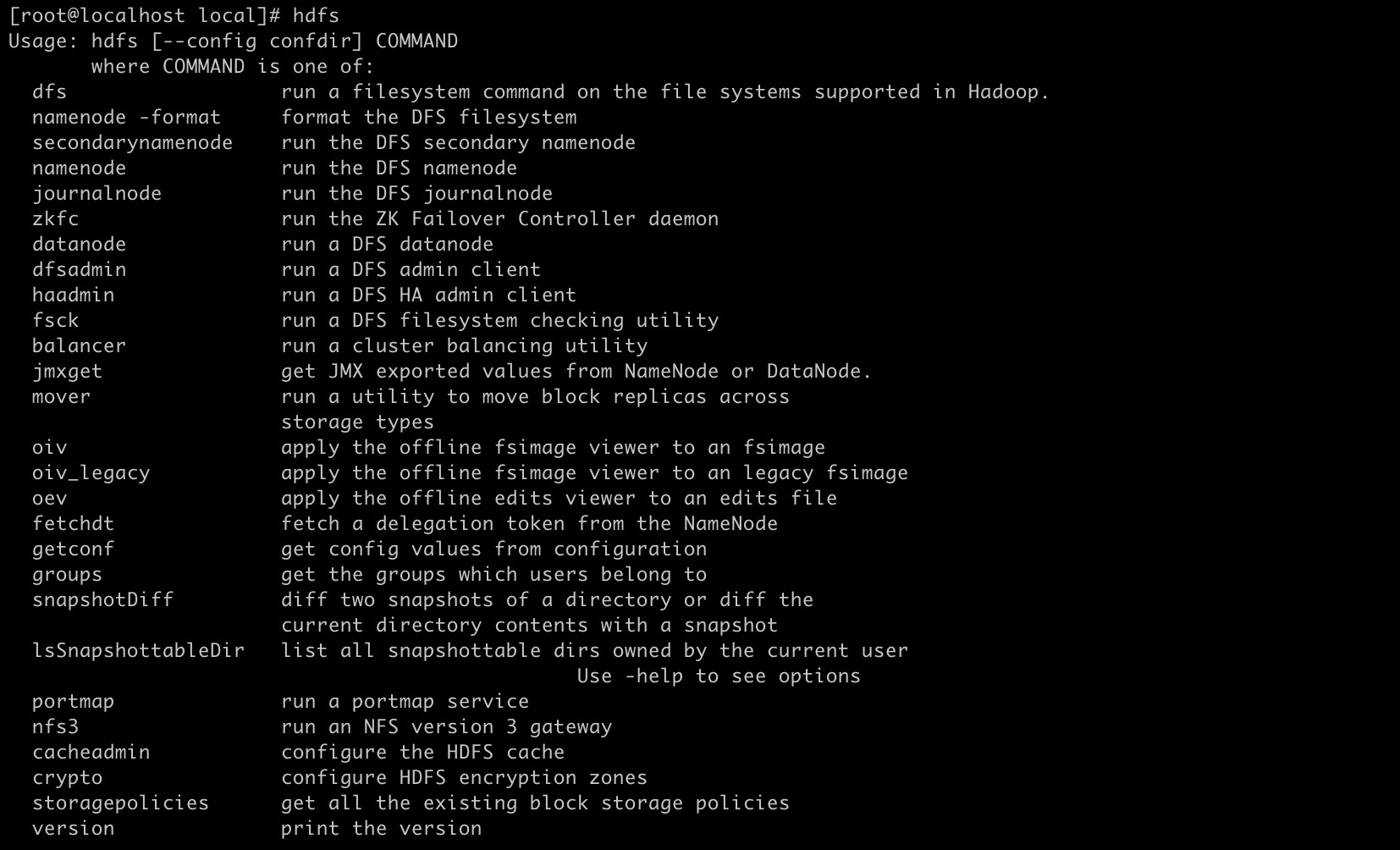
第六步 关闭虚拟机然后克隆一台实例(这里做实验克隆一台就够了)
克隆完成修改实例名称 第一台实例hostname 更改为master 第二台实例更改为slave1 如下图:
vim /etc/hostname #编辑实例名称
reboot #重启boot
第七步 配置ssh 无密钥访问
1.在master实例执行
ssh-keygen -t rsa
注意这里所有输入直接回车
2.在slave1实例执行(同上所有输入直接回车)
ssh-keygen -t rsa
注意 slave1实例上我们cd 到/root/.ssh/ 目录 使用ls命令查看 有两个文件分别是 id_rsa 和 id_rsa.pub 我们拷贝id_rsa.pub 文件并且重新命名为slave1 然后复制slave1文件到master实例上 命令如下
cd /root/.ssh/ #跳转到/root/.ssh目录 cp id_rsa.pub ./slave1 #复制 id_rsa.pub文件并且重名命为slave1 scp ./slave1 root@172.16.102.15:/root/.ssh/ #将slave1文件复制到master实例/root/.ssh/目录下 注意 (1).要输入yes 和 master实例的密码。(2)172.16.102.15 这个是master实例的ip根据自己master实际ip修改
如下图:(图片这里master ip地址写错了 应该是172.16.102.15 而不是16)

然后我们来到master实例同样到/root/.ssh 目录下合并master实例的id_rsa.pub 文件和slave1实例复制过来的文件并且命名为 authorized_keys 命令如下:
cd /root/.ssh/ cat id_rsa.pub slave1 >>authorized_keys #合并master和slave1的密钥文件 scp ./authorized_keys root@172.16.102.16:/root/.ssh #复制合并后的文件到slave1实例 注意 172.16.102.16 是slave1的ip要根据自己实际的ip修改命令
操作如下图:
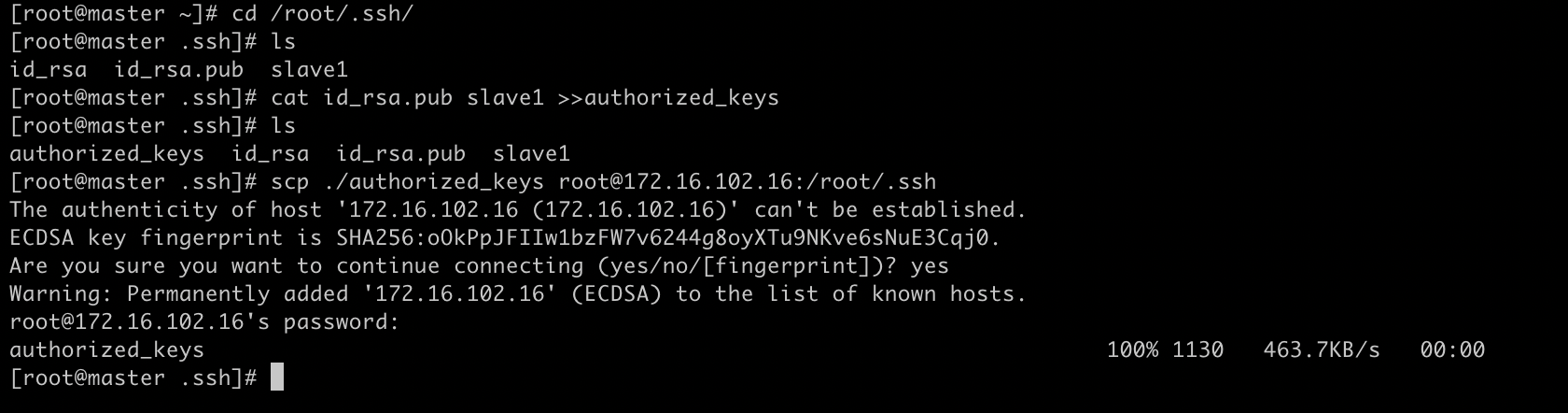
测试效果
 第八步 编辑/etc/hosts文件 如下图
第八步 编辑/etc/hosts文件 如下图

注意这两个ip要改成自己实际的ip 然后同步host文件到其他实例 这里我是在master实例上编辑的所以需要同步到slave1实例。 执行如下命令:
scp /etc/hosts slave1:/etc/hosts

第九步 编辑 master实例子中 hadoop的slave文件 文件位于 /usr/local/hadoop-2.6.4/etc/hadoop 编辑内容很简单之前在slave中我配置了三台slave实例现在只有一台 删除另外两个配置就好 结果如下

第十步 格式化节点 在master、slave实例分别执行
hdfs namenode -format
执行结果如下:
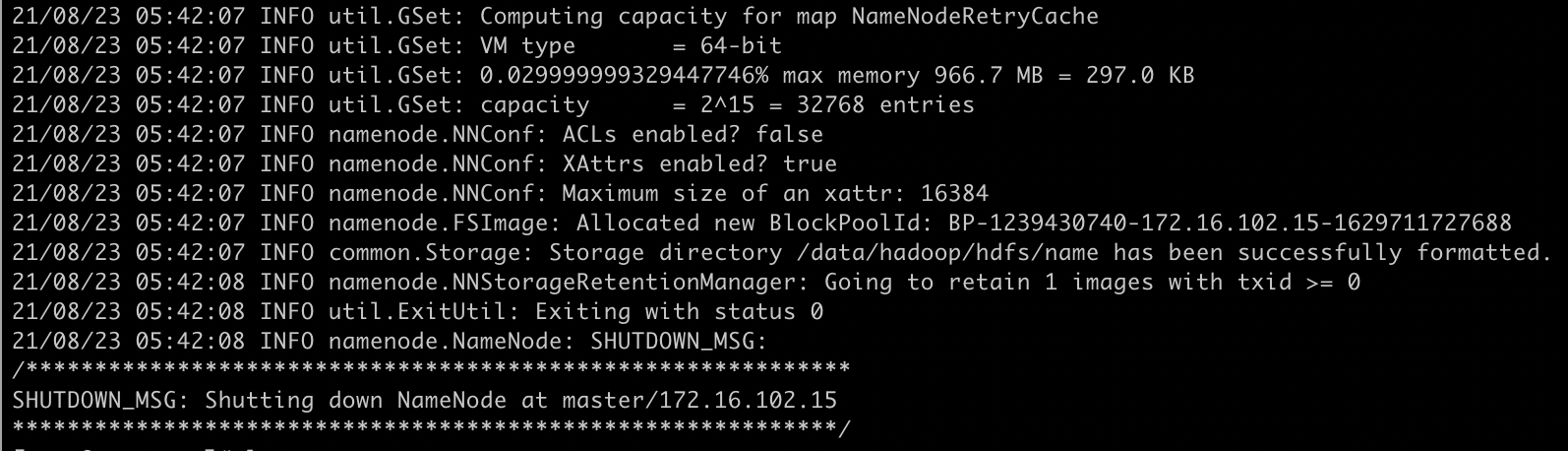

第十一步 尝试启动hadoop 我们来到master实例 /usr/local/hadoop-2.6.4 目录下执行 ./start_hadoop.sh 脚本 正确结果如下

在master实例执行jps命令测试正确结果如下
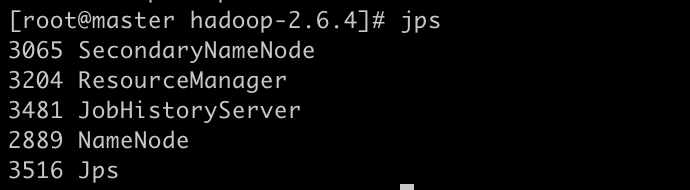
在slave1实例上测试正确结果如下
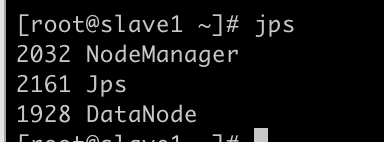
第十二步访问管理界面
修改自己本机器的hosts文件 添加
172.16.102.15 master 172.16.102.16 slave1
http://master:50070/dfshealth.html#tab-overview
http://master:8088/cluster
http://master:19888/jobhistory
http://master:50070/nn_browsedfscontent.jsp 本次实验主要使用的是这个地址
访问后界面如下
到这环境终于准备好了,即使我是复制之前搭建的环境,还是有点复杂。现在我们开始准备日志分析。
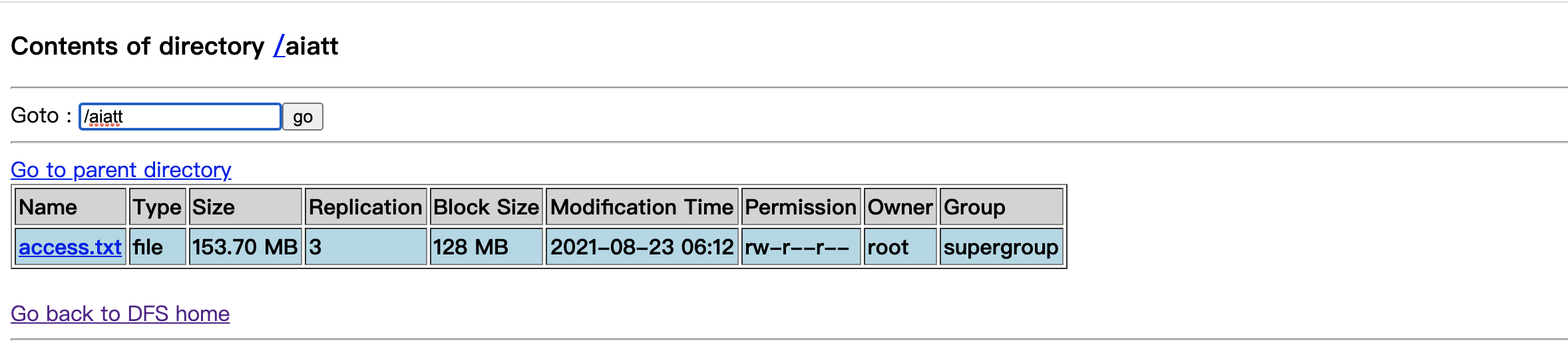
第一步上传日志文件到master实例然后在上传到hdfs 上传文件到hdfs需要先hdfs文件夹 创建和上传命令如下
hdfs dfs -mkdir /aiatt #创建aiatt文件夹
hdfs dfs -put ./access.txt /aiatt #上传access 日志文件到hdfs文件系统 aiatt目录下
操作结果如下:

然后我们刷新 http://master:50070/nn_browsedfscontent.jsp 页面查看结果
现在我们开始执行Map/Reduce 任务任务如下:
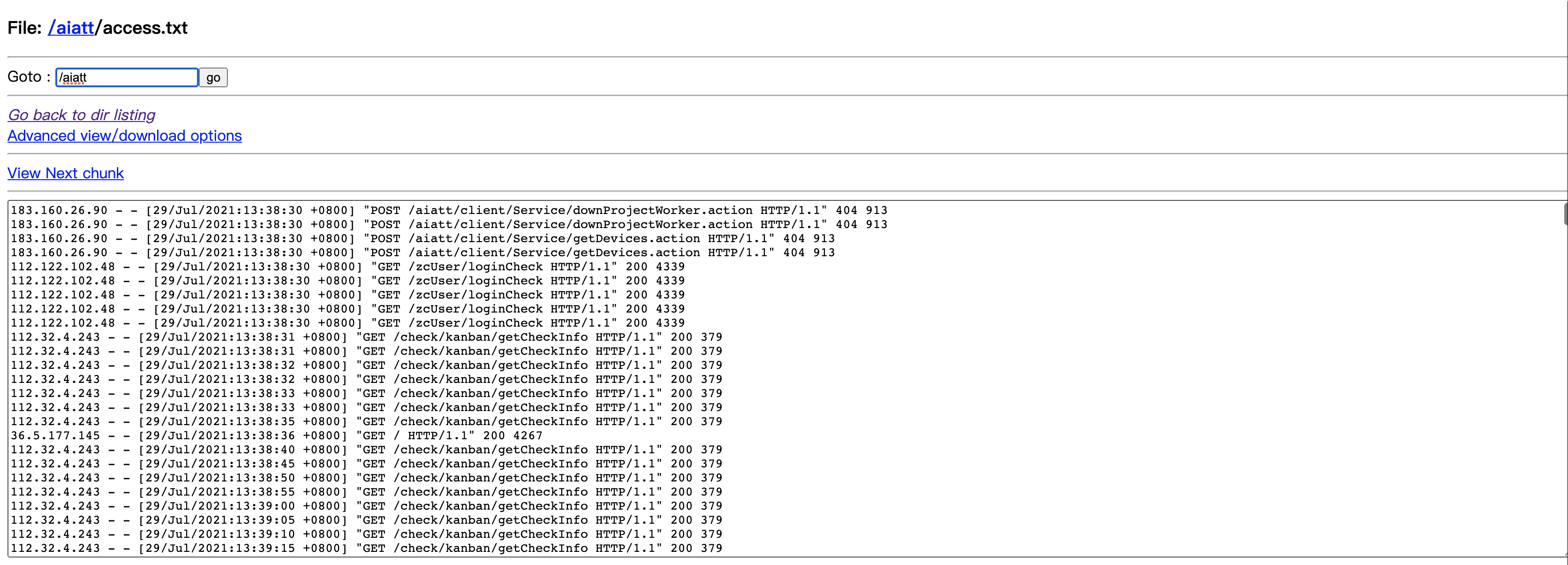
这段日志是某个tomcat的请求记录日志,现在我们想要的结果是计算出每个请求请求的频率 然后针对有请求频率过高的接口做优化或者缓存。针对这个任务的MapReduce我也已经写好了 直接下载
链接: https://pan.baidu.com/s/1Wu6uDSBBZK9Wsaue1kmWXQ 提取码: obw5
然后上传到master实例执行一下命令
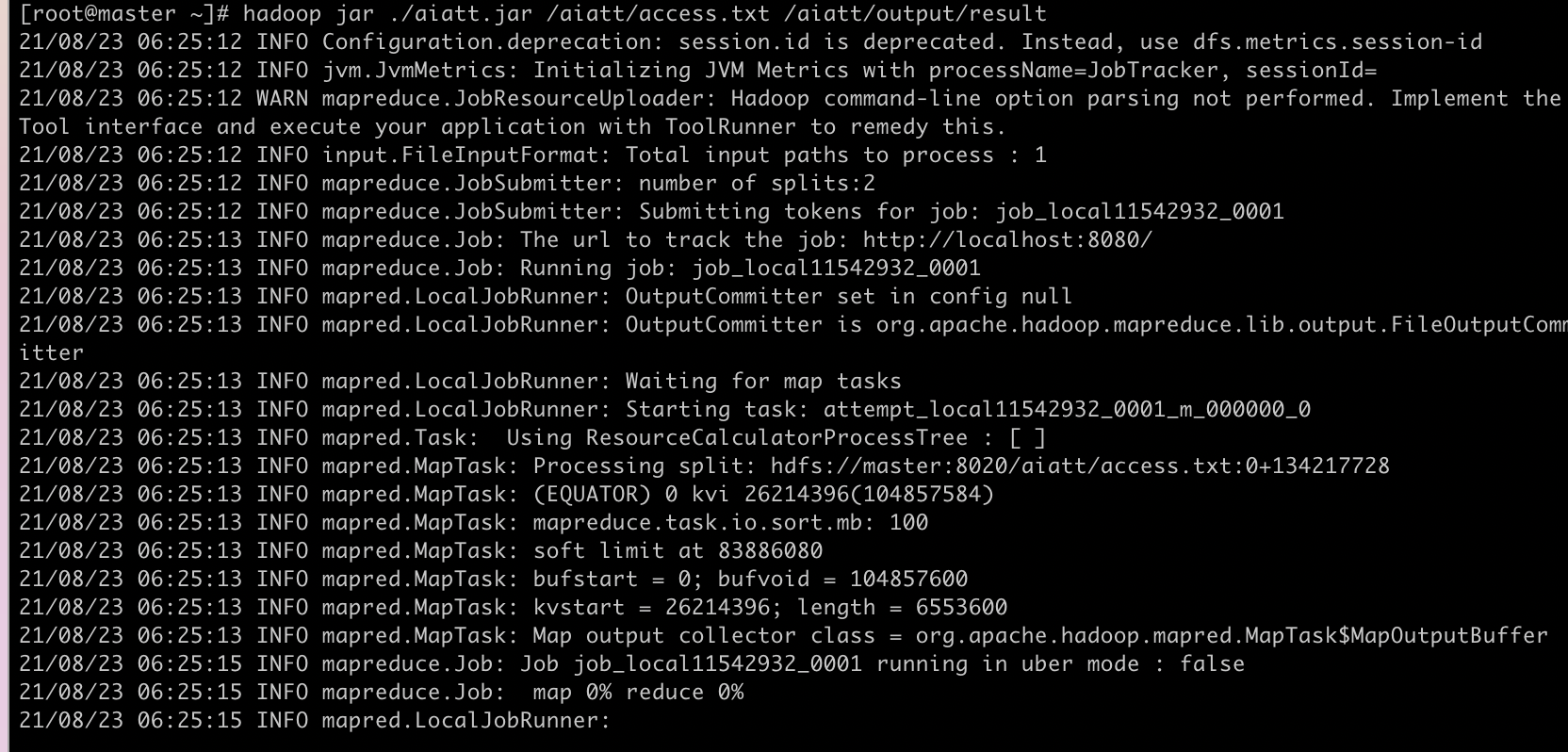
hadoop jar ./aiatt.jar /aiatt/access.txt /aiatt/output/result
/aiatt/access.txt 是输入的文件地址 /aiatt/output/result 输出结果地址
这个两个地址都是hdfs 的地址 另外要注意重复执行任务输出地址不能一致,不然会报错。执行结果如下图:
最后我们刷新 刚才的hdfs文件查看的地址查看计算结果
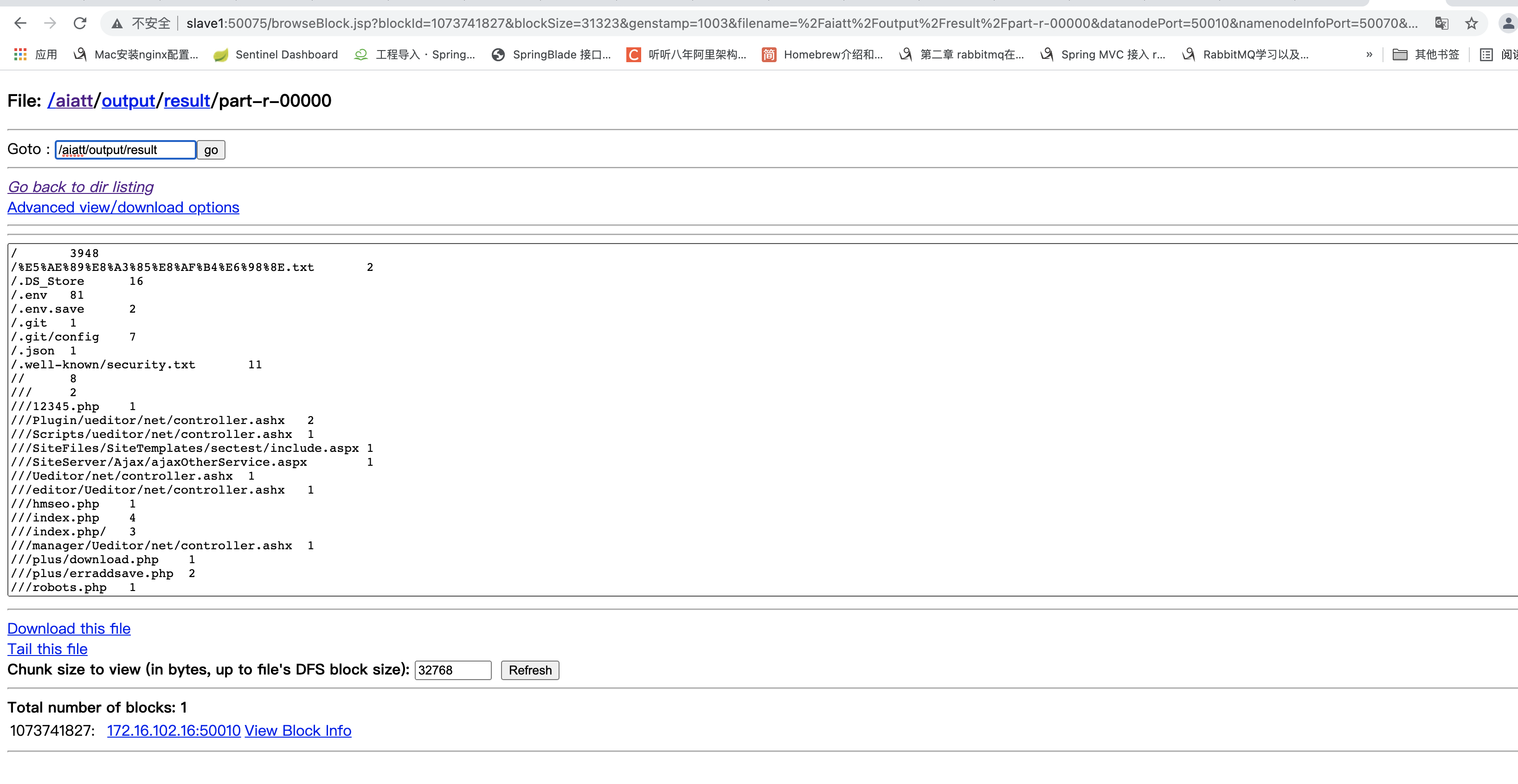

到这里就结束了 这个实验主要是想让未接触过hadoop的体验一下,如果真的想学习的话推荐 《Hadoop大数据开发基础》这本书 ,我就是看这本书自学的,虽然这本书有几个小错误但是还是不错的入门书