1.线性表顺序表倒置算法:
int len=strlen(l);
int i=0;
while(i<len/2){
int tmp=l[i];
l[i]=l[len-i-1];
l[len-i-1]=tmp;
}
2.画二叉排序树
每次与子树根节点比较,从而向下左右选择移动,左小右大。
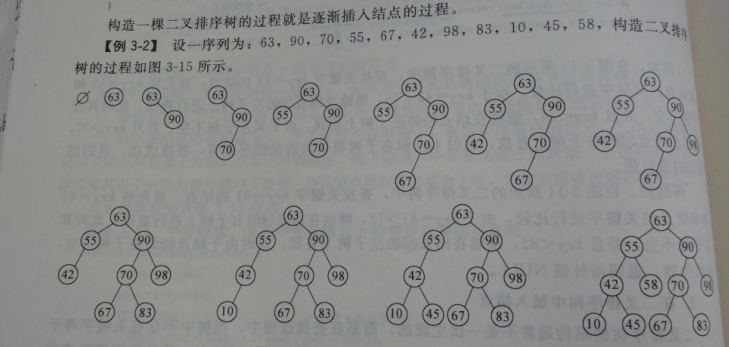
中序遍历可得到有序序列。
3.线索二叉树
1) 扩展结点结构,增加两个标志域,以记录左右孩子域记录的为孩子还是前驱后继。标志域为0,表示指示孩子;为1,表示指示前驱后继。另外,增设一头结点,其数据域不存储数据,左孩子域指向二叉树根结点,右孩子域指向遍历的最后一个结点,故而LTag为0,RTag为1。而二叉树在某种遍历下的第一个结点的前驱以及最后一个结点的后继都指向该头结点。
2) 找前驱后继(以中序为例)
Node InPreNode(Node p){
Node pre=p->lchird;
if(p->LTag!=1)
while(pre->RTag!=1) pre=pre->rchild;
return pre;
}
Node InPostNode(Node p){
Node post=p->rchird;
if(p->RTag!=1)
while(post->LTag!=1) post=post->lchild;
return post;
}
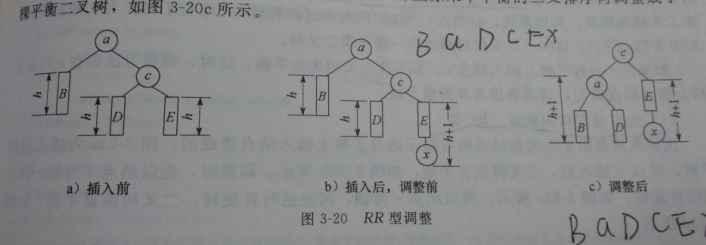
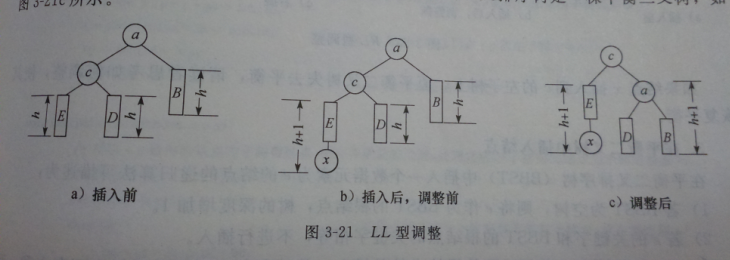
4.平衡二叉树→对二叉排序树进行调整
每个结点的左右子树深度差不超过1。(左减右)
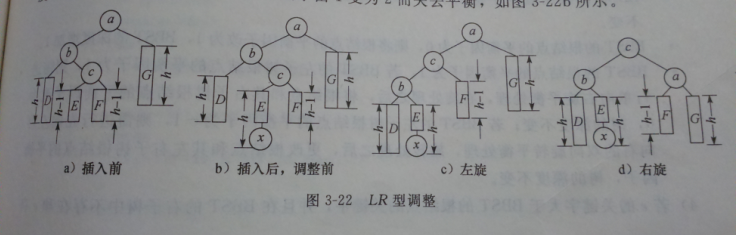
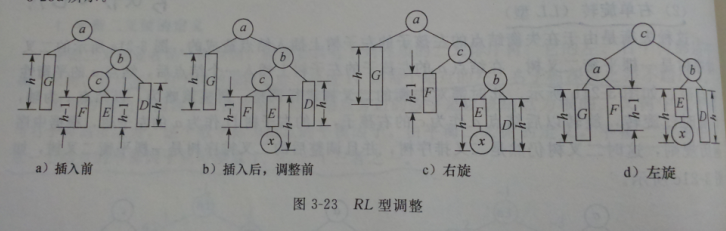
5.大小顶堆(以小顶堆为例)
1)所有双亲的值均不大于左右孩子
2)筛选算法:
Void f1(type *a, int k, int n){ //a[k]为双亲结点
int i=k, j=i*2, x=a[i], status=false;
while(j<n&&status==false){
if(j<n&&a[j]>a[j+1]) j++;
if(x<=a[j]) status=true;
else { a[i]=a[j]; i=j; j*=2;}
}
a[i]=x;
}
3)建堆:按层次遍历顺序的逆序,倒着对每个双亲对应子树进行筛选。
Void f2(type *a){
for(int i=n/2;i>=1;i--) f1(a,i,n);
}
4)堆排序:每次取走堆顶元素,然后用最后一个元素(按层次遍历顺序)代替堆顶元素,进而筛选。依次循环。
Void f3(type *a,int n){
int I,m=n;
f2(a);
for(i=1;i<=n;i++){
s[i]=a[1];
a[1]=a[m--];
f1(a,1,m);
}
}
6.求树的深度
int depth(node t){
if(t==NULL) return 0;
if(t->lchild==NULL&&t->rchild==NULL) return 1;
int dl=depth(t->lchild);
int dr=depth(t->rchild);
return 1+max(dl,dr);
}
7.深度为k的二叉树至多有2^k -1个结点,至少为2^(k-1)个结点。
8.最短路径:有权图 Dijkstra
Void Dijkstra(){
Dis[start_node]=0;
For(int k=1; k<=node_num;k++){
Int x,m=INF;
For(int i=1;i<=node_num;i++) if(!b[i]&&dis[i]<m) m=dis[x=i];
B[x]=1;
For(int i=node_first[x];i!=-1;i=node_next[i]){
If(!b[node_end[i]]&&dis[node_end[i]]>dis[x]+node_value[i]){
Dis[node_end[i]]=dis[x]+node_value[i];
Node_fa[node_end[i]]=x;
}
}
}
Cout<<dis[final_node]<<endl;
}
Void Road(){
For(int i=final_node;i!=start_node;i=node_fa[i])
road[road_len++]=I;
}
9.最小生成树
1) Prim 复杂度为O(n*n) 适合边稠密的图
Int Prim(){
Int ans=0;
For(int i=1;i<=node_num;i++) choose[i]=0,distance[i]=INF;
Distance[1]=0;
For(int i=1;i<=node_num;i++){
Int x=-1;
For(int j=1;j<=node_num;j++)
If(!choose[j])
If(x==-1) x=j;
Else if(distance[j]<distance[x]) x=j;
Choose[x]=1;
Ans+distance[x];
For(int j=1;j<=node_num;j++)
If(!choose[j]&&a[x][j]!=INF){
Distance[j]=min(distance[j],a[x][j]);
}
}
Return ans;
}
2)Kruskal 复杂度为O(eloge) e为边的数目 适合边稀疏的图
Inline int cmp(cons tint &a,cons tint &b) { return node_w[a]<node_w[b];}
Inline int find(int x){ return p[x]==x?x:p[x]=find(p[x]); }
Int Kruskal(){
Int ans=0;
For(int i=1;i<=node_num;i++) p[i]=i;
For(int i=1;i<=edge_num;i++) r[i]=i;
Sort(&r[1],&r[edge_num+1],cmp);
For(int i=1;i<=edge_num;i++){
Int e=r[i];
Int x=find(node_u[e],y=find(node_v[e]);
If(x!=y) ans+=node_w[e],p[x]=y;
}
Return ans;
}
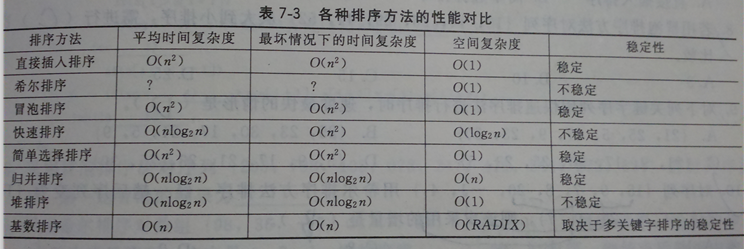
10.哈希表对应平均查找长度(ASL)

11.排序算法的时空复杂度