数据库优化
第一级
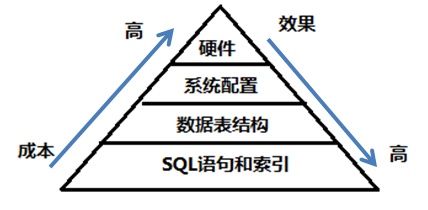
简单DDL、DML调优。SQL写的好不好?group by、order by对不对?select别用*,记得要用hit index啊。数据库表设计好点啊,主键外键索引啊,执行计划看一看啊。
SQL语句和索引的优化是最重要的。我们追求的就是写出结构良好的SQL,然后根据SQL在表中建立有效的索引。如果索引过多,不但会影响写入的效率,对查询也有一定的影响。
要根据一些范式来进行表结构的设计。设计表结构时,就需要考虑如何设计才能够更有效的查询。
第二级
第二级是DBA层级调优。MSSQL,ORACLE,MYSQL都各自有几十项配置。在不同的应用场景下需要针对性调整系统配置的优化。MySQL数据库是基于文件的,如果打开的文件数达到一定的数量,无法打开之后就会进行频繁的IO操作。
参考这里
第三级
是数据库中间件和infra层级调优。
参考《MySQL数据库优化两三事》(大佬,打扰了!小弟告辞)
优化成本和效果
一、SQL语句优化
-
查询慢日志
可以通过开启查询慢日志的方式进行定位效率有问题的SQL
-
查看MySQL是否开启慢查询日志
show variables like 'slow_query_log';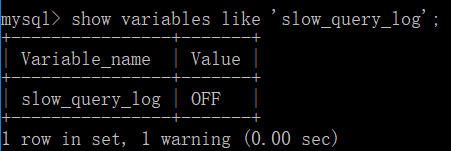
-
设置没有索引的记录到慢查询日志
set global log_queries_not_using_indexes=on; -
查看超过多长时间的sql进行记录到慢查询日志
show variables like 'long_query_time'; -
开启慢查询日志
set global slow_query_log=on -
设置超时时间
Set global long_query_time=5; --超过5s的语句才记录日志 -
查看慢查询日志的位置
show variables like 'slow%'
-
-
慢查询日志内容分析
慢查询日志主要分为5部分,第一部分是慢查询时间,第二部分是慢查询的来源主机和用户,第三部分是查询的执行时间、锁定时间、发送的行数、扫描的行数。最后是时间戳形式记录的命令以及该命令的执行的时间戳。
系统运行一段时间后,慢查询日志可能比较多,需要通过mysqldumpslow、pt-query-digest等工具分析慢查询日志。参考这里。
-
通过explain查看SQL的执行计划
具体的分析过程可以参考这里,里面的例子描述的很清晰。
二、索引优化
索引一般情况下都是高效的。不过凡是都有两面性,索引是以空间换时间的一种策略,索引本身在提高查询效率的同时会影响插入、更新、删除的效率。不当的使用索引不仅增加了写操作的负担,也会影响读取的效率。索引越多,数据库分析的越慢。注意点:
- InnoDB 每个索引都会加上主键,联合索引不要加上主键,innodb会自动加,否则会冗余。
- 索引存在的目的是为了加快查询的效率,不过不是索引越多越好,建立索引要适当才好。过多的索引会增加数据库判断使用什么索引来查询的开销,所以,有时候也会出现以去掉重复或者无效的索引为优化手段的优化方式。
- 主键已经是索引了,所以primay key 的主键不用再设置unique唯一索引了。
索引的原理可以参考这里或者这里。理解索引原理对于索引优化有很大帮助。
三、数据表结构优化
-
选择合适的数据类型
- 使用可存下数据的最小的数据类型;
- 使用简单地数据类型,int要比varchar类型在mysql处理上更简单;
- 尽可能使用not null定义字段,这是由innodb的特性决定的,因为非not null的数据可能需要一些额外的字段进行存储,这样就会增加一些IO。可以对非null的字段设置一个默认值;
- 尽量少用text,非用不可最好分表,将text字段存放到另一张表中,在需要的时候再使用联合查询,这样可提高查询主表的效率;
-- 例子1、用int存储日期时间from_unixtime()可将Int类型的时间戳转换为时间格式 select from_unixtime(1392178320); -- 输出为 2014-02-12 12:12:00 -- unix_timestamp()可将时间格式转换为Int类型 select unix_timestamp('2014-02-12 12:12:00'); -- 输出为1392178320 -- 例子2、存储IP地址——bigInt -- 利用inet_aton(),inet_ntoa()转换 select inet_aton('192.169.1.1'); -- 输出为3232301313select inet_ntoa(3232301313); -- 输出为192.169.1.1