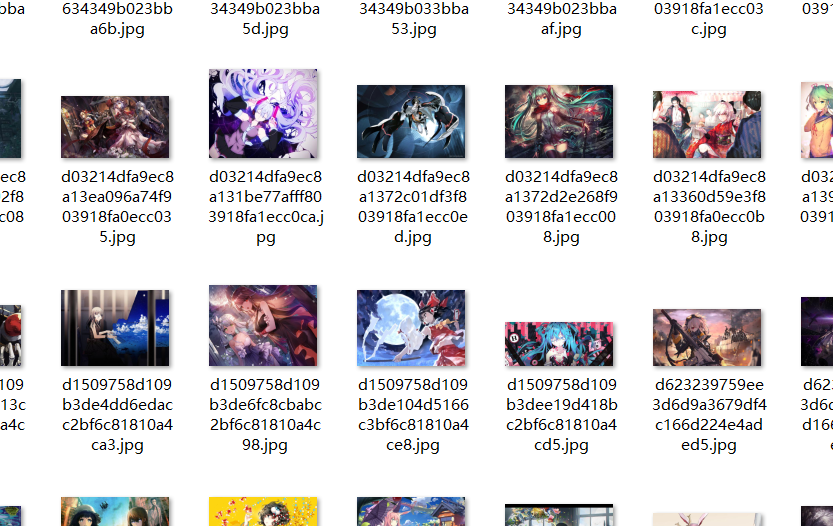
下载 百度贴吧-动漫壁纸吧 所有图片
定义item

Spider
spider 只需要得到图片的url,必须以列表的形式给管道处理
class PictureSpiderSpider(scrapy.Spider):
name = 'picture_spider'
allowed_domains = ['tieba.baidu.com']
start_urls = ['https://tieba.baidu.com/f?kw=%E5%8A%A8%E6%BC%AB%E5%A3%81%E7%BA%B8']
def parse(self, response):
# 贴吧中一页帖子的ID和标题
theme_urls = re.findall(r'<a rel="noreferrer" href="/p/(d+)" title="(.*?)" target="_blank" class="j_th_tit ">',
response.text, re.S)
for theme in theme_urls:
# 帖子的url
theme_url = 'https://tieba.baidu.com/p/' + theme[0]
# 进入各个帖子
yield scrapy.Request(url=theme_url, callback=self.parse_theme)
# 贴吧下一页的url
next_url = re.findall(
r'<a href="//tieba.baidu.com/f?kw=%E5%8A%A8%E6%BC%AB%E5%A3%81%E7%BA%B8&ie=utf-8&pn=(d+)" class="next pagination-item " >下一页></a>',
response.text, re.S)
if next_url:
next_url = self.start_urls[0] + '&pn=' + next_url[0]
yield scrapy.Request(url=next_url)
# 下载每个帖子里的所有图片
def parse_theme(self, response):
item = PostBarItem()
# 每个贴子一页图片的缩略图的url
pic_ids = response.xpath('//img[@class="BDE_Image"]/@src').extract()
# 用列表来装图片的url
item['pic_urls'] = []
for pic_url in pic_ids:
# 取出每张图片的名称
item['pic_name'] = pic_url.split('/')[-1]
# 图片URL
url = 'http://imgsrc.baidu.com/forum/pic/item/' + item['pic_name']
# 将url添加进列表
item['pic_urls'].append(url)
# 将item交给pipelines下载
yield item
# 下完一页图片后继续下一页
next_url = response.xpath('//a[contains(text(),"下一页")]/@href').extract_first()
if next_url:
yield scrapy.Request('https://tieba.baidu.com' + next_url, callback=self.parse_theme)
ImagesPipeline
- from scrapy.pipelines.images import ImagesPipeline
- 继承ImagesPipeline,重写get_media_requests()和file_path()方法
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class PostBarPipeline(ImagesPipeline):
# 需要headers的网站,再使用
headers = {
'User-Agent': '',
'Referer': '',
}
def get_media_requests(self, item, info):
for pic_url in item['pic_urls']:
# 为每个url生成一个Request
yield scrapy.Request(pic_url)
# 需要请求头的时候,添加headers参数
# yield scrapy.Request(pic_url, headers=self.headers)
def file_path(self, request, response=None, info=None):
# 重命名(包含后缀名),若不重写这函数,图片名为哈希
pic_path = request.url.split('/')[-1]
return pic_path
settings文件
-
激活管道

-
设置图片保存地址
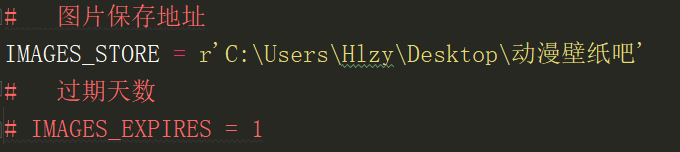
运行结果