一、 并查集概述
并查集是一种树形结构,用来判断两个元素是否在同一棵树上,以及合并两个元素所在的树。
二、 并查集特性
并查集是一种树形结构,但它的特性不像2-3树,二叉树,红黑树那么复杂:
1、 每个结点都只有一个元素,每一组元素都在一棵树上
2、 一个组中的元素和另一组的元素间没有任何联系
3、 元素在树中没有严格的父子大小要求

三、 并查集实现
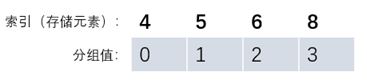
在初始化并查集时,我们通常把元素作为数组的索引,数组的值为元素所在的组别(如果元素非int类型,则可使用其他映射结构来使元素和int类型的数据对应)
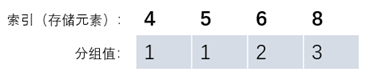
当我们合并元素A和B时,只需修改索引A和B的值为相同值即可,如下让元素4和5合并成一个组
|
/** * 并查集实现 * @author jiyukai */ public class UF {
//记录结点元素和该结点所在组的标识 public int[] valueAndgroup;
//并查集的组个数 public int N;
/** * 并查集构建 * @param N */ public UF(int n) { //分组个数赋值 this.N = n; //数组初始化 valueAndgroup = new int[n]; //数组的索引为结点元素的值,值为所在组的标志,初始化时假设每个组有一个元素,则索引用元素表示,所在组可以初始化为i //使用整数来表示节点的值,如果需要其他数据类型,可以用hashTable来进行映射。如:将string映射为int类型 for(int i=0;i<n;i++) { valueAndgroup[i] = i; } }
/** * 并查集分组个数 * @return */ public int count() { return N; }
/** * 查找元素p所在分组的标志 * @param p * @return */ public int find(int p) { return valueAndgroup[p]; }
/** * 判断元素p和q是否在同个分组中 * @param p * @param q * @return */ public boolean isConnected(int p,int q) { return valueAndgroup[p]==valueAndgroup[q]; }
/** * 合并元素p和q * @param p * @param q */ public void union(int p,int q) { //p和q已在同一组别中,不用合并 if(isConnected(p, q)) { return; }
//找出p和q所在的组 int p_group = find(p); int q_group = find(q);
//将valueAndgroup中p所在组的值更新为q的所在组 for(int i=0;i<valueAndgroup.length;i++) { if(valueAndgroup[i]==p_group) { valueAndgroup[i] = q_group; } }
//组别-1 N--; }
} |
四、 并查集合并优化
在计算机网络中,假设并查集的每个元素为每台计算机的ip,那么通过调用isConnected方法则可知道两台计算机是否互联,调用union方法则可以让两台计算互联。
在实际运用中,若要使所有计算机两两互联,需要调用N^2次,时间复杂度是相当高的,因此我们需要对算法进行优化。
假设有两棵独立的树,为了无需在union合并时,遍历整个数组去修改两棵树中元素的组,我们希望将两根树的进行合并,归属于同一个根结点,这样则需要并查集数组中存放的值为元素的父结点
这样我们在合并时只需将两棵树的根结点修改为同一个,则省去了union的遍历带来的耗时,算法优化如下。
在如下示意图中,当我们顺着元素(即索引)找父节点,当找到元素和父节点相同时,则认为该元素为根结点,如下图我们可找到4为0的根结点。
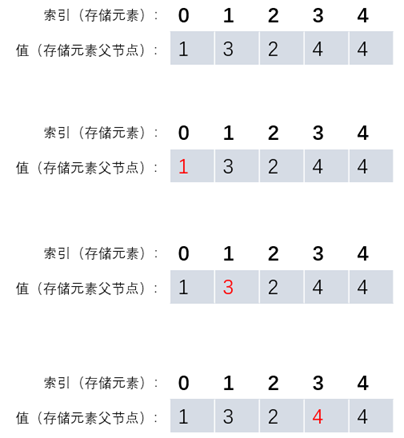
在union合并中,我们只需将两棵树的根结点修改为同一个元素,即可将两棵独立的树进行合并
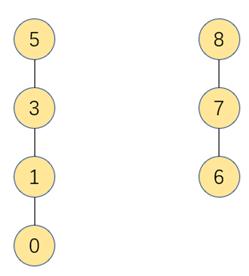
合并后成为如下,只需一步操作完成
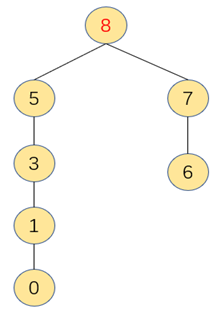

|
/** * 并查集实现 * @author jiyukai */ public class UF_Tree {
//记录结点元素和该结点的父结点 public int[] valueAndgroup;
//并查集的组个数 public int N;
/** * 并查集构建 * @param N */ public UF_Tree(int n) { //分组个数赋值 this.N = n; //数组初始化 valueAndgroup = new int[n]; //数组的索引为结点元素的值,值为所在组的标志,初始化时假设每个组有一个元素,则索引用元素表示,所在组可以初始化为i //使用整数来表示节点的值,如果需要其他数据类型,可以用hashTable来进行映射。如:将string映射为int类型 for(int i=0;i<n;i++) { valueAndgroup[i] = i; } }
/** * 并查集分组个数 * @return */ public int count() { return N; }
/** * 查找元素p所在分组的标志 * @param p * @return */ public int find(int p) { while(true) { if(p == valueAndgroup[p]) { return p; }
p = valueAndgroup[p]; } }
/** * 合并元素p和q * @param p * @param q */ public void union(int p,int q) {
//找出p和q所在的根结点 int p_root = find(p); int q_root = find(q);
//如果q和p的根结点相同 if(p_root==q_root) { return; }
//如果p和q不在一个分组,则让p的父节点为q的父节点,这样两颗独立的树就合并到一起,就无需再遍历整个数组去查找 valueAndgroup[p_root] = q_root;
//组别-1 N--; }
} |
五、 并查集搜索优化
上述的优化中,我们修改了union方法,使union原本O(N)的复杂度变成了O(1),但是find方法的复杂度却增加了,变成了O(N),所以如上算法的最坏情况下还是O(N^2)
这时我们需要对find进行再次优化
在合并两棵树时,我们发现,当小树合并大树,即小树的根结点作为大树的根结点时,树的层级会加深,如下图。
而当大树合并小树,即大树的根结点作为小树的根结点时,树的层级不会加深,此时可以在find方法处提高效率。
原始树:

小树合并大树后层级加深
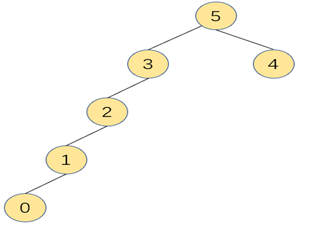
大树合并小树后层级不变
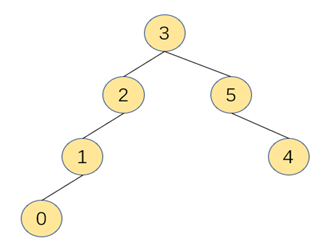
因此,为完成这个需求,我们需要另外一个数组来记录每个元素所在树的层级大小,方便合并时做出判断,实现大树合并小树。
|
/** * 小树合并大树并查集 * @author jiyukai */ public class UF_Shorter_Tree { //记录结点元素和该结点的父结点 public int[] valueAndgroup;
//记录结点元素所在树的深度 private int[] nodeCount;
//并查集的组个数 public int N;
/** * 并查集构建 * @param N */ public UF_Shorter_Tree(int n) { //分组个数赋值 this.N = n; //数组初始化 valueAndgroup = new int[n]; //数组的索引为结点元素的值,值为所在组的标志,初始化时假设每个组有一个元素,则索引用元素表示,所在组可以初始化为i //使用整数来表示节点的值,如果需要其他数据类型,可以用hashTable来进行映射。如:将string映射为int类型 for(int i=0;i<n;i++) { valueAndgroup[i] = i; }
//初始化结点元素所在的深度,每个元素初始化的深度为1 nodeCount = new int[n]; for(int j=0; j<n; j++) { nodeCount[j] = 1; }
}
/** * 并查集分组个数 * @return */ public int count() { return N; }
/** * 查找元素p所在分组的标志 * @param p * @return */ public int find(int p) { while(true) { if(p == valueAndgroup[p]) { return p; }
p = valueAndgroup[p]; } }
/** * 合并元素p和q * @param p * @param q */ public void union(int p,int q) {
//找出p和q所在的根结点 int p_root = find(p); int q_root = find(q);
//如果q和p的根结点相同 if(p_root==q_root) { return; }
if(p_root < q_root) { //p所在树的深度小于q所在树的深度,p相对于q是小树
//大树的根作为小树的根去合并 valueAndgroup[p_root] = q_root;
//更改结点所在树的深度 nodeCount[q_root] = nodeCount[q_root] + nodeCount[p_root]; }else { //q所在树的深度小于p所在树的深度,q相对于p是小树
//大树的根作为小树的根去合并 valueAndgroup[q_root] = p_root; //更改结点所在树的深度 nodeCount[p_root] = nodeCount[p_root] + nodeCount[q_root]; }
//组别-1 N--; }
} |