Spring-data-jpa 学习笔记(一)
作者:zeng1994
出处:http://www.cnblogs.com/zeng1994/
Spring家族越来越强大,作为一名javaWeb开发人员,学习Spring家族的东西是必须的。在此记录学习Spring-data-jpa的相关知识,方便后续查阅。
一、spring-data-jpa的简单介绍
SpringData : Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。
SpringData 项目所支持 NoSQL 存储:
- MongoDB (文档数据库)
- Neo4j(图形数据库)
- Redis(键/值存储)
- Hbase(列族数据库)
SpringData 项目所支持的关系数据存储技术:
- JDBC
- JPA
JPA Spring Data : 致力于减少数据访问层 (DAO) 的开发量, 开发者唯一要做的就只是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成!
框架怎么可能代替开发者实现业务逻辑呢?比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
Spring Data JPA 进行持久层(即Dao)开发一般分三个步骤:
- 声明持久层的接口,该接口继承 Repository(或Repository的子接口,其中定义了一些常用的增删改查,以及分页相关的方法)。
- 在接口中声明需要的业务方法。Spring Data 将根据给定的策略生成实现代码。
- 在 Spring 配置文件中增加一行声明,让 Spring 为声明的接口创建代理对象。配置了 <jpa:repositories> 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
二、QuickStart
(1)创建项目并添加Maven依赖
首先我们在eclipse中创建一个Maven的java项目,然后添加依赖。
项目结构见右图: 
主要依赖有:
- spring-data-jpa
- Hibernate相关依赖
- c3p0依赖
- mysql驱动
pom.xml文件的代码如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.zxy</groupId><artifactId>springdata-demo</artifactId><version>0.0.1-SNAPSHOT</version><!-- 全局属性配置 --><properties><project.source.encoding>utf-8</project.source.encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!-- 防止控制输出台中文乱码 --><argLine>-Dfile.encoding=UTF-8</argLine></properties><dependencies><!-- junit_jar包依赖 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><!--保留到测试 --><scope>test</scope></dependency><!-- spring-data-jpa相关依赖(这个依赖自动把一堆spring的东西依赖进来了,所有可以不需要再引入spring的包)--><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-jpa</artifactId><version>1.11.7.RELEASE</version></dependency><!-- Hibernate --><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>5.0.11.Final</version></dependency><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-entitymanager</artifactId><version>5.0.11.Final</version></dependency>- <!-- https://mvnrepository.com/artifact/com.mchange/c3p0 -->
<dependency><groupId>com.mchange</groupId><artifactId>c3p0</artifactId><version>0.9.5.2</version></dependency><!-- mysql驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.29</version></dependency></dependencies><build><plugins><!-- 编译插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>2.5.1</version><configuration><!-- 源码用1.8 --><source>1.8</source><!-- 打成jar用1.8 --><target>1.8</target><encoding>utf-8</encoding></configuration></plugin></plugins></build></project>
(2)整合SpringData,配置applicationContext.xml
jdbcUrl=jdbc:mysql://localhost:3306/springdata?useUnicode=true&characterEncoding=utf8driverClass=com.mysql.jdbc.Driveruser=rootpassword=rootinitialPoolSize=10maxPoolSize=30
- 开启包扫描,扫描service层,让service层的对象交给Spring容器管理
- 读取properties文件
- 配置数据源dataSource
- 配置JPA的EntityManagerFactory, 这里面有个包扫描,是扫描实体类那一层的
- 配置事务管理器transactionManager
- 配置支持注解的事务
- 配置SpringData这里包扫描是扫描dao层,扫描那些定义的接口
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:tx="http://www.springframework.org/schema/tx"xmlns:jpa="http://www.springframework.org/schema/data/jpa"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsdhttp://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa-1.3.xsdhttp://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd"><!-- 配置自动扫描的包,扫描service层,service上面有注解就直接被spring容器实例化 --><context:component-scan base-package="com.zxy.service"/><!-- 1. 配置数据源 --><context:property-placeholder location="classpath:db.properties"/><bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"><property name="jdbcUrl" value="${jdbcUrl}"/><property name="driverClass" value="${driverClass}"/><property name="user" value="${user}"/><property name="password" value="${password}"/><property name="initialPoolSize" value="${initialPoolSize}"/><property name="maxPoolSize" value="${maxPoolSize}"/></bean><!-- 2. 配置 JPA 的 EntityManagerFactory --><bean id="entityManagerFactory"class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"><property name="dataSource" ref="dataSource"/><property name="jpaVendorAdapter"><bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"></bean></property><!-- 配置包扫描,扫描实体 --><property name="packagesToScan" value="com.zxy.entity"/><property name="jpaProperties"><props><!-- 生成的数据表的列的映射策略 --><prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop><!-- hibernate 基本属性 --><prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop><prop key="hibernate.show_sql">true</prop><prop key="hibernate.format_sql">true</prop><prop key="hibernate.hbm2ddl.auto">update</prop></props></property></bean><!-- 3. 配置事务管理器 --><bean id="transactionManager"class="org.springframework.orm.jpa.JpaTransactionManager"><property name="entityManagerFactory" ref="entityManagerFactory"/></bean><!-- 4. 配置支持注解的事务 --><tx:annotation-driven transaction-manager="transactionManager"/><!-- 5. 配置 SpringData,需要加入 jpa 的命名空间 --><!-- base-package: 扫描 Repository Bean 所在的 package --><jpa:repositories base-package="com.zxy.dao" entity-manager-factory-ref="entityManagerFactory"></jpa:repositories></beans>
(3)测试整合
- 通过静态代码块创建 ClassPathXmlApplicationContext对象,让它读取applicationContext.xml,这样就启动了Spring容器
- 通过Spring容器获取dataSource对象,如果成功获取,说明整合成功了。
package com.zxy.test;import org.springframework.context.ApplicationContext;import org.springframework.context.support.ClassPathXmlApplicationContext;- import java.sql.SQLException;
- import javax.sql.DataSource;
- import org.junit.Test;
/*** 整合效果测试类* @author ZENG.XIAO.YAN* @date 2017年9月14日 下午11:01:20* @version v1.0*/public class TestConfig {private static ApplicationContext ctx ;static {// 通过静态代码块的方式,让程序加载spring的配置文件ctx = new ClassPathXmlApplicationContext("classpath:applicationContext.xml");}/** 测试spring容器是否实例化了数据源 。如果实例化了,说明Spring容器整合没问题 */@Testpublic void testDataSouce() throws SQLException {DataSource dataSouce = (DataSource) ctx.getBean("dataSource");System.out.println("数据源:"+ dataSouce);System.out.println("连接:"+ dataSouce.getConnection());}}
- 有一个前提,数据库必须先创建。这里springdata这个数据库我先创建了
- 给实体类加上注解,然后开启Hibernate自动建表功能,启动Spring容器;如果数据库自动建表成功,那就整合成功
package com.zxy.entity;import java.util.Date;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.GenerationType;import javax.persistence.Id;import javax.persistence.Table;/*** Person实体* @author ZENG.XIAO.YAN* @date 2017年9月14日 下午2:44:23* @version v1.0*/@Entity@Table(name="jpa_persons")public class Person {@Id@GeneratedValue(strategy=GenerationType.IDENTITY)private Integer id;@Columnprivate String name;@Columnprivate String email;@Columnprivate Date birth;/** setter and getter method */public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getEmail() {return email;}public void setEmail(String email) {this.email = email;}public Date getBirth() {return birth;}public void setBirth(Date birth) {this.birth = birth;}}
(4)在dao层声明接口
package com.zxy.dao;import org.springframework.data.repository.Repository;import org.springframework.data.repository.RepositoryDefinition;import com.zxy.entity.Person;/*** PersonDao* @author ZENG.XIAO.YAN* @date 2017年9月18日 下午4:25:39* @version v1.0*//** 1.Repository是一个空接口,即是一个标记接口* 2.若我们定义的接口继承了Repository,则该接口会被IOC容器识别为一个Repository Bean* 注入到IOC容器中,进而可以在该接口中定义满足一定规则的接口* 3.实际上也可以通过一个注解@RepositoryDefination 注解来替代Repository接口*///@RepositoryDefinition(domainClass=Person.class,idClass=Integer.class)public interface PersonDao extends Repository<Person, Integer> {// 通过id查找实体Person getById(Integer id);}
(5)测试dao层接口
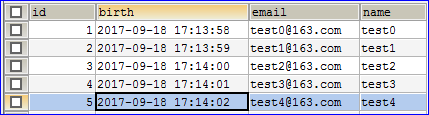

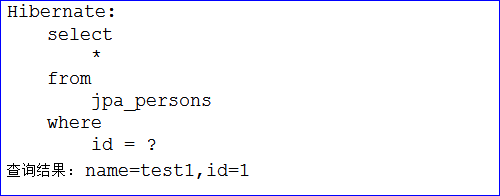
package com.zxy.test;import org.junit.Test;import org.springframework.context.ApplicationContext;import org.springframework.context.support.ClassPathXmlApplicationContext;import com.zxy.dao.PersonDao;import com.zxy.entity.Person;/*** SpringData快速入门测试类* @author ZENG.XIAO.YAN* @date 2017年9月18日 下午5:33:42* @version v1.0*/public class TestQuickStart {private static ApplicationContext ctx ;static {// 通过静态代码块的方式,让程序加载spring的配置文件ctx = new ClassPathXmlApplicationContext("classpath:applicationContext.xml");}/** 测试PersonDao中定义的getById的方法能否查询出结果 */@Testpublic void testGetById() {PersonDao personDao = ctx.getBean(PersonDao.class);Person person = personDao.getById(1);System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId());}}

三、SpringData方法定义规范
(1)简单的条件查询的方法定义规范
- 简单条件查询:查询某一个实体或者集合
- 按照SpringData规范,查询方法于find|read|get开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:属性首字母需要大写。
- 支持属性的级联查询;若当前类有符合条件的属性, 则优先使用, 而不使用级联属性。 若需要使用级联属性, 则属性之间使用 _ 进行连接。
// 通过id和name查询实体,sql: select * from jpa_persons where id = ? and name = ?Person findByIdAndName(Integer id, String name);
/** 测试getByIdAndName方法 */@Testpublic void testGetByIdAndName() {PersonDao personDao = ctx.getBean(PersonDao.class);Person person = personDao.findByIdAndName(1, "test0");System.out.println(person);}
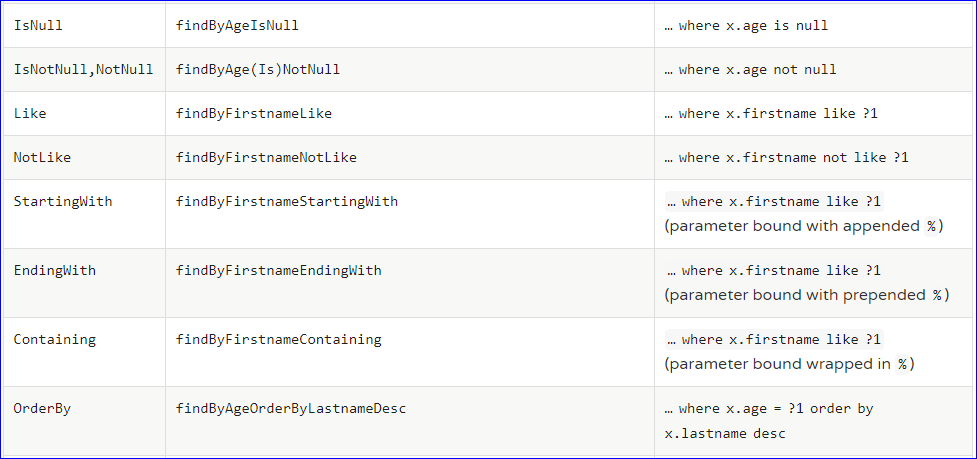
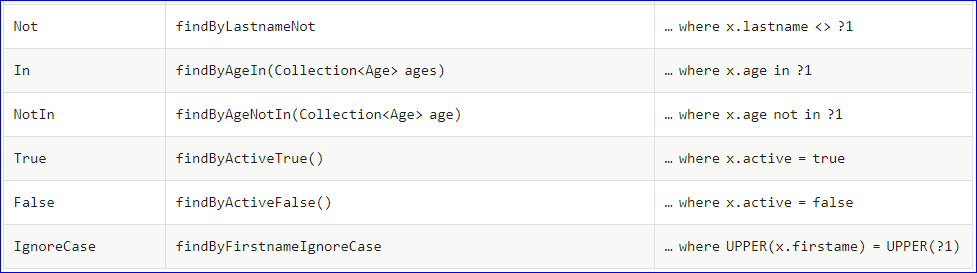
(2)支持的关键字
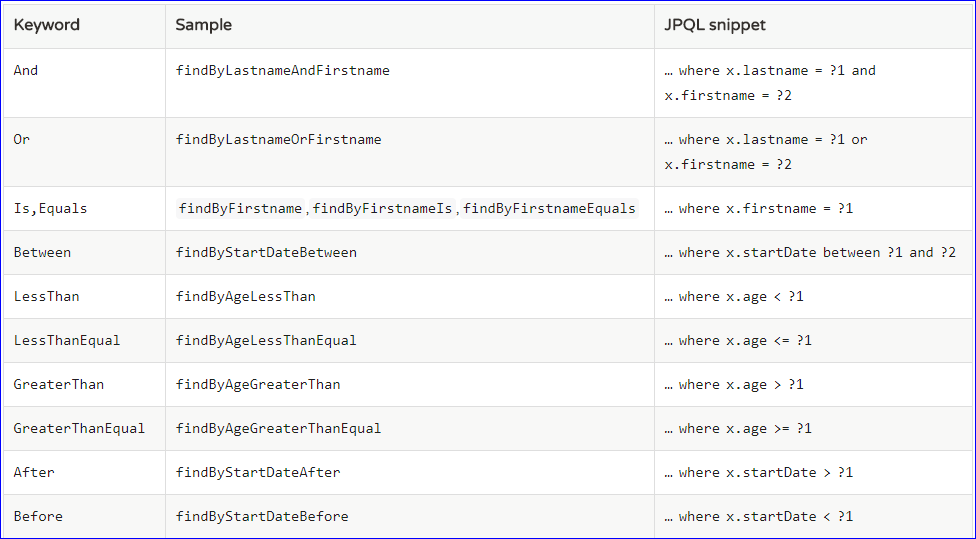
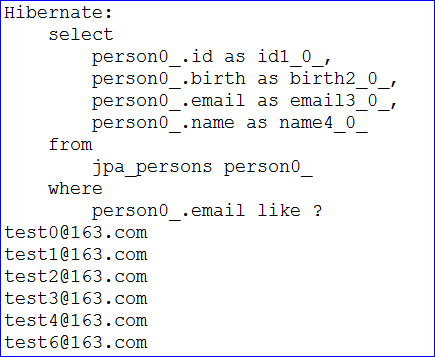
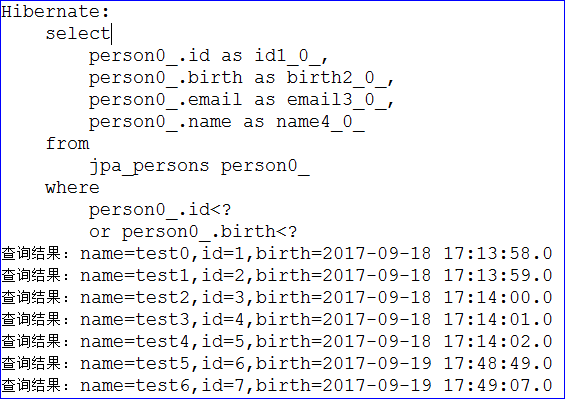
// where id < ? or birth < ?List<Person> findByIdIsLessThanOrBirthLessThan(Integer id, Date birth);// where email like ?List<Person> findByEmailLike(String email);- // 也支持count查询
- long countByEmailLike(String email);
/** 测试findByEmailLike方法 */@Testpublic void testFindByEmailLike() {PersonDao personDao = ctx.getBean(PersonDao.class);List<Person> list = personDao.findByEmailLike("test%");for (Person person : list) {System.out.println(person.getEmail());}}/** 测试findByIdIsLessThanOrBirthLessThan方法 */@Testpublic void testFindByIdIsLessThanOrBirthLessThan() {PersonDao personDao = ctx.getBean(PersonDao.class);List<Person> list = personDao.findByIdIsLessThanOrBirthLessThan(3, new Date());for (Person person : list) {System.out.println("查询结果: name=" + person.getName()+ ",id=" + person.getId() + ",birth=" + person.getBirth());}}
(3)一个属性级联查询的案例
- 在com.zxy.entity包下新建一个Address的实体,代码如下图,setter和getter方法我省略了

- 修改Person类,添加address属性,使Person和Address成多对一的关系,设置外键列名为address_id ,添加的代码如下图:

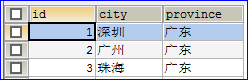
- 运行我们上面的任意一个测试方法,只要启动了项目,数据库的表都会更新。在表更新后我们需要手动插入一些数据,我插入的数据如下:
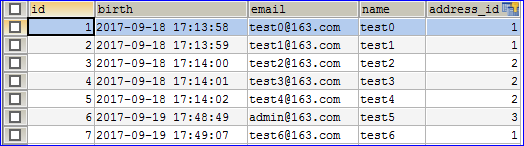
- 修改jpa_persons表,使address_id这个外键列有值,修改后的效果如下图:
- 在PersonDao接口中定义一个方法,代码如下:
// 级联查询,查询address的id等于条件值List<Person> findByAddressId(Integer addressId);
- 在TestQucik这个测试类中定义一个单元测试方法,测试这个dao的方法是否可用。代码如下:
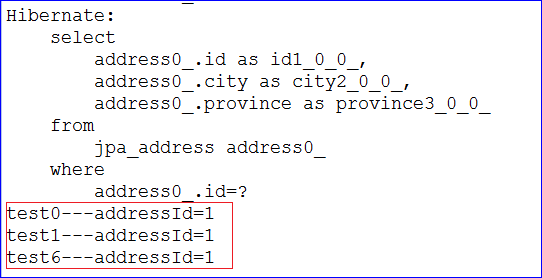
/** 测试findByAddressId方法 */@Testpublic void testFindByAddressId() {PersonDao personDao = ctx.getBean(PersonDao.class);// 查出地址id为1的person集合List<Person> list = personDao.findByAddressId(1);for (Person person : list) {System.out.println(person.getName()+ "---addressId="+ person.getAddress().getId());}}
- 运行测试方法,通过控制台可观察生成的sql语句和查询的结果。结果如下图所示:

(4)查询方法解析流程
- 首先剔除 findBy,然后对剩下的属性进行解析,假设查询实体为Doc
- 先判断 userDepUuid(根据 POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续往下走
- 从右往左截取第一个大写字母开头的字符串(此处为Uuid),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复这一步,继续从右往左截取;最后假设 user 为查询实体的一个属性
- 接着处理剩下部分(DepUuid),先判断 user 所对应的类型是否有depUuid属性,如果有,则表示该方法最终是根据 "Doc.user.depUuid" 的取值进行查询;否则继续按照步骤3的规则从右往左截取,最终表示根据 "Doc.user.dep.uuid" 的值进行查询。
可能会存在一种特殊情况,比如 Doc包含一个 user 的属性,也有一个 userDep 属性,此时会存在混淆。可以明确在级联的属性之间加上 "_" 以显式表达意图,比如 "findByUser_DepUuid()" 或者 "findByUserDep_uuid()"。
四、@Query注解
(1)使用Query结合jpql语句实现自定义查询
- 在PersonDao接口中声明方法,放上面加上Query注解,注解里面写jpql语句,代码如下:
// 自定义的查询,直接写jpql语句; 查询id<? 或者 名字 like?的person集合@Query("from Person where id < ?1 or name like ?2")List<Person> testPerson(Integer id, String name);// 自定义查询之子查询,直接写jpql语句; 查询出id最大的person@Query("from Person where id = (select max(p.id) from Person as p)")Person testSubquery();
- 在TestQuickStart中添加以下代码,测试dao层中使用Query注解的方法是否可用
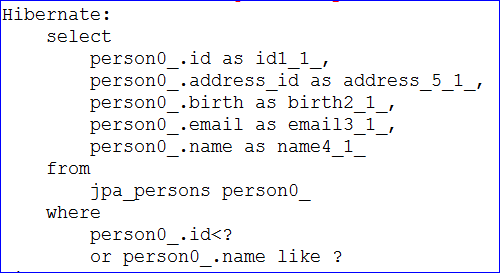
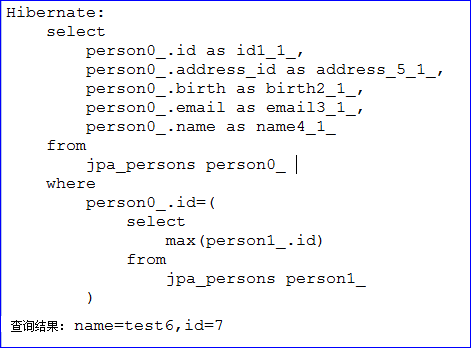
/** 测试用Query注解自定义的方法 */@Testpublic void testCustomMethod() {PersonDao personDao = ctx.getBean(PersonDao.class);List<Person> list = personDao.testPerson(2, "%admin%");for (Person person : list) {System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId());}System.out.println("===============分割线===============");Person person = personDao.testSubquery();System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId());}
- 查询结果及生成的sql语句如下所示

(2)索引参数和命名参数
- 索引参数方式如下图所示,索引值从1开始,查询中'?x'的个数要和方法的参数个数一致,且顺序也要一致

- 命名参数方式(推荐使用这种方式)如下图所示,可以用':参数名'的形式,在方法参数中使用@Param("参数名")注解,这样就可以不用按顺序来定义形参


(3)使用@Query来指定使用本地SQL查询
- dao层接口写法如下图所示

- 测试代码这里直接不贴了,下面是控制台中打印的语句和结果
五、@Modifying注解和事务
(1)@Modifying注解的使用
- dao层代码如下所示
//可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作. 注意: JPQL 不支持使用 INSERT//在 @Query 注解中编写 JPQL 语句, 但必须使用 @Modifying 进行修饰. 以通知 SpringData, 这是一个 UPDATE 或 DELETE 操作//UPDATE 或 DELETE 操作需要使用事务, 此时需要定义 Service 层. 在 Service 层的方法上添加事务操作.//默认情况下, SpringData 的每个方法上有事务, 但都是一个只读事务. 他们不能完成修改操作!@Modifying@Query("UPDATE Person p SET p.name = :name WHERE p.id < :id")int updatePersonById(@Param("id")Integer id, @Param("name")String updateName);
- 由于这个更新操作,只读事务是不能实现的,因此新建PersonService类,在Service方法中添加事务注解。PersonService的代码如下图所示
package com.zxy.service;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;import com.zxy.dao.PersonDao;/*** PersonService* @author ZENG.XIAO.YAN* @date 2017年9月20日 下午2:57:16* @version v1.0*/@Service("personService")public class PersonService {@Autowiredprivate PersonDao personDao;@Transactional(readOnly=false)public int updatePersonById(Integer id, String updateName) {return personDao.updatePersonById(id, updateName);}}
- 测试类中直接调用service的方法就ok了,测试代码如下图
- 方法返回值是int,表示影响的行数
- 在调用的地方必须加事务,没事务不执行
(2)事务
- Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
- 对于自定义的方法,如需改变 Spring Data 提供的事务默认方式,可以在方法上注解 @Transactional 声明
- 进行多个 Repository 操作时,也应该使它们在同一个事务中处理,按照分层架构的思想,这部分属于业务逻辑层,因此,需要在 Service 层实现对多个 Repository 的调用,并在相应的方法上声明事务。
六、本文小结
作者:zeng1994
出处:http://www.cnblogs.com/zeng1994/
本文版权归作者和博客园共有,欢迎转载!但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接!