1. MR程序在yarn上运行的基本流程
此篇博客可以看看(https://www.cnblogs.com/kocdaniel/p/11637888.html)
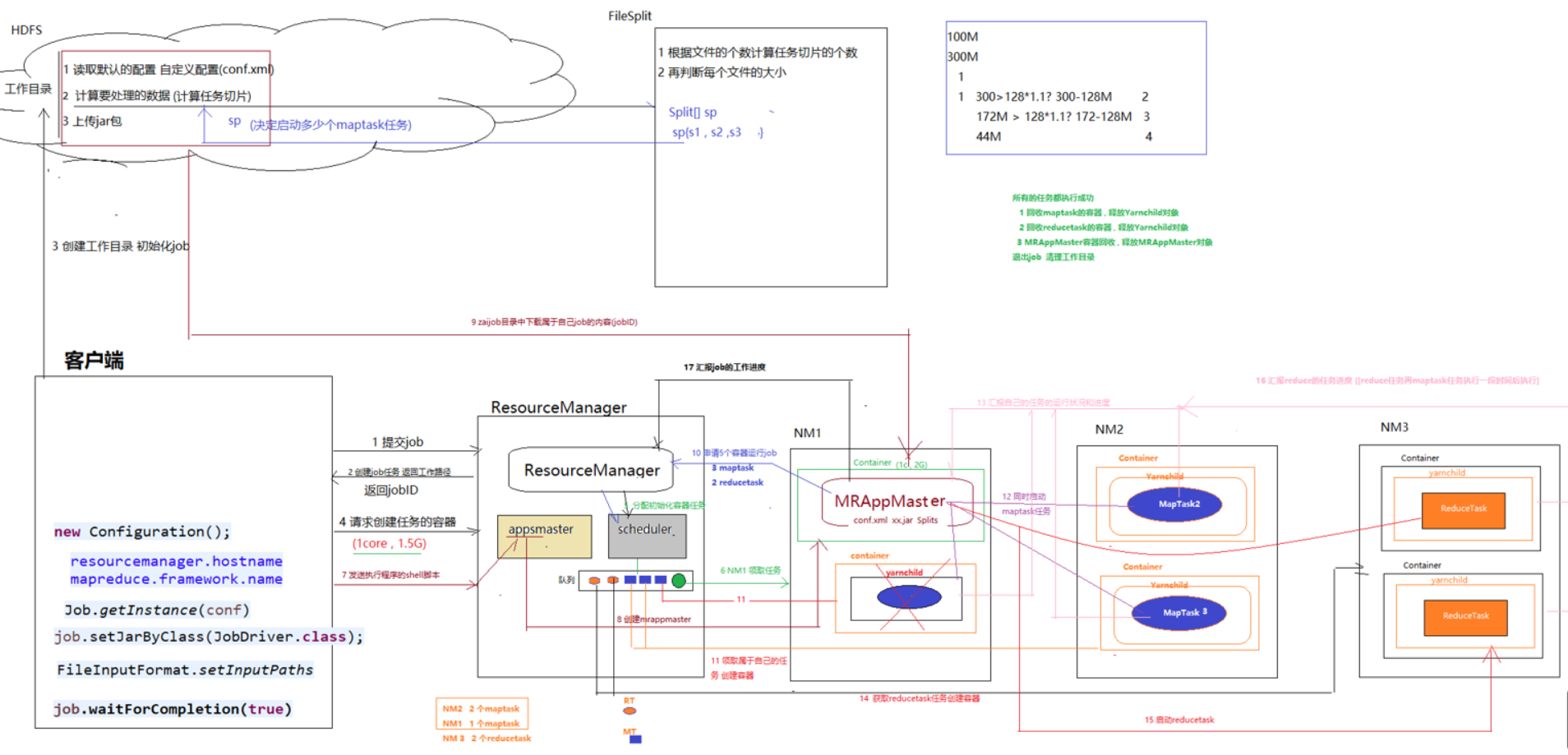
(1)client提交作业申请
- client向ResourceManager提交job申请
- RM创建job任务,并根据申请内容返回相关的信息(例如根据input文件的路径,返回文件的元数据,以及job的工作路径)
- 客户端根据从RM返回的信息创建工作目录以及资源文件(job.split,job.xml,app.jar)并将资源文件提交至工作路径(一般存在hdfs上面),完成job的初始化
(2)ResourceManager(RM)处理用户请求
- 客户端请求RM创建任务的容器(cpu+ram等)
- RM将用户的请求打包为task,放置调度队列(FIFO)
补充:客户端请求RM创建任务的容器后,RM会将这个请求交给scheduler,scheduler根据各个节点的运算资源来创建一个任务,并将这个任务放到队列中
(3)NM从队列中领取task
- 创建contianer容器
- 客户端发送执行程序的shell脚本至appsmaster
- 通过appsmaster创建MRAppMaster
- 下载job资源至本地
(4)MRAppMaster(MRAM)向RM申请运行maptask以及reducemap的容器
- RM将MRAppMaster的请求打包为task放置在调度队列
- 各个nodemanager领取属于自己的任务,并创建容器
(5)MRAppMaster向maptask发送程序启动命令
- container中的mapTask会向MRAppMaster汇报自己任务的运行情况和精度(即MRAM负责这些任务的监控和调度)
(6)获取reducetask任务,创建相应的容器
(7)同(5),只是此次变成reducetask
(8)MRAM向RM汇报job的工作进度
(9)程序运行完成后,MRAM向RM注销自己
2. 数据倾斜解决方案
由于mapreduce程序是按照key的hash值进行分区的 , 如果某些单词特别多 , 特别多的单词就会被分到同一个reduce去处理。
有些reducere任务处理的数据量小,有些reducere任务处理的数据量小,只有所有的reduce任务完成以后job才算完成 , 造成job的工作时间变长 [任务分配不均匀]
解决方案:
(1)将key打散:在key上添加随机数,根据reduce的数量打散
案例:
有一个文件,内容如下(正常使用mr程序处理的话,处理a的reduce相比其他的时间要多很多)
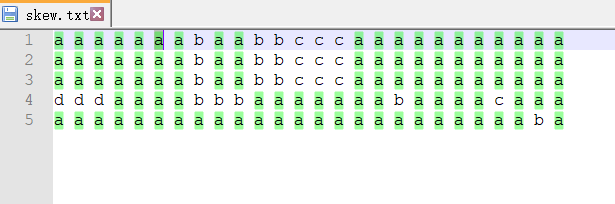
思路:通过两次MR程序的计算,第一次获取到 a-随机数 1 这种文件,第二次讲这些数据拆开合并
第一次MR代码(注意:reduce聚合得到的结果是/t,不是一个空格)
Skew


public class Skew{ static Text k = new Text(); static IntWritable v = new IntWritable(); static class SkewMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ int numReduceTasks = 0; // 用来获取reducetask的个数 @Override protected void setup(Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { numReduceTasks = context.getNumReduceTasks(); } Random ran = new Random(); // maptask @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 处理数据并给每个key添加随机数 String line = value.toString(); String[] split = line.split(" "); for (String word : split) { String newWord = word+"-"+ran.nextInt(numReduceTasks); k.set(newWord); v.set(1); context.write(k, v); } } } // reducetask static class SkewReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> iters, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : iters) { int i = intWritable.get(); count += i; } k.set(key); v.set(count); context.write(k, v); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setMapperClass(SkewMapper.class); job.setReducerClass(SkewReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setNumReduceTasks(3); // 输出好输入的数据路径 FileInputFormat.setInputPaths(job, new Path("E:/javafile/skew.txt")); FileOutputFormat.setOutputPath(job, new Path("E:/wc/skew/output5/")); // true 执行成功 boolean b = job.waitForCompletion(true); // 退出程序的状态码 404 200 500 System.exit(b ? 0 : -1); } }
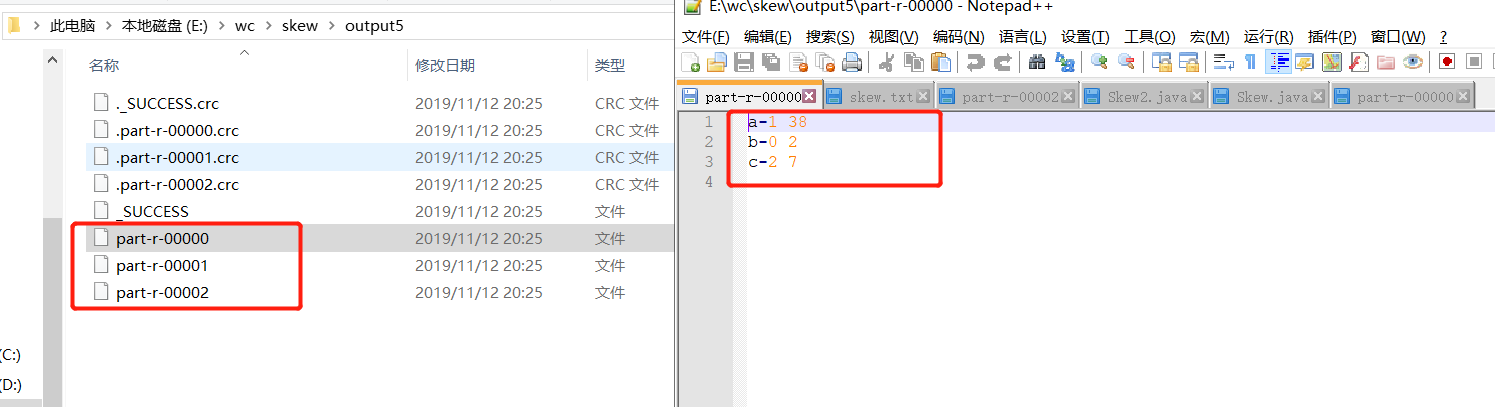
结果:(因为设置了三个reducetask,所以有3个part文件)
第二次MR代码
Skew2
public class Skew2 { static Text k = new Text(); static IntWritable v = new IntWritable(); static class SkewMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); String[] split = line.split("\t"); k.set(split[0].split("-")[0]); v.set(Integer.parseInt(split[1])); context.write(k, v); } } static class SkewReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> iters, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : iters) { int i = intWritable.get(); count += i; } k.set(key); v.set(count); context.write(k, v); } } public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setMapperClass(SkewMapper.class); job.setReducerClass(SkewReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // job.setNumReduceTasks(3); // 输出好输入的数据路径 FileInputFormat.setInputPaths(job, new Path("E:/wc/skew/output5/")); FileOutputFormat.setOutputPath(job, new Path("E:/wc/skew/output8/")); // true 执行成功 boolean b = job.waitForCompletion(true); // 退出程序的状态码 404 200 500 System.exit(b ? 0 : -1); } }
即可得到相应的结果
(2)避免reduce任务
此处以join案例为例(day08中的做法数据一多会有数据倾斜的问题,此处直接省去了reduce任务)
mapJoin
public class MapJoin { static class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> { // 在setup的方法中读取分布式缓存的数据 user.txt 将数据存储在map中 Map<String, User> map = new HashMap<>(); // 将缓存数据缓存在类路径下 读取数据的时候直接写文件名 @SuppressWarnings("resource") @Override protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { // 读取user数据 BufferedReader br = new BufferedReader(new FileReader("user.txt")); String line = null ; //遍历每行数据 将每行数据存储在User类中 while((line = br.readLine())!=null) { String[] split = line.split(","); User user = new User() ; user.setUid(split[0]); user.setName(split[1]); user.setAge(Integer.parseInt(split[2])); user.setFriend(split[3]); //将所有的数据存储在map中 map.put(user.getUid(), user) ; } } /** * 只读取订单数据 每行就是一条订单信息 oid uid * 输入的路径中不能有用户信息 */ Text k = new Text() ; @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { //订单的数据 String line = value.toString(); // order011,u001 String[] split = line.split(","); String uid = split[1]; // 当前订单对应 的用户信息数据 User user = map.get(uid); if(user!=null) { k.set(line +","+user.toString()) ; // map的输出作为job的最终输出 没有reduce端 不会shuffle 不会数据倾斜 context.write(k, NullWritable.get()); } } } public static void main(String[] args) throws Exception { // 获取mr程序运行时的初始化配置 Configuration conf = new Configuration(); conf.set("mapreduce.framework.name", "yarn"); // 设置resource manage机器的位置 conf.set("yarn.resourcemanager.hostname", "doit01"); Job job = Job.getInstance(conf); job.setJarByClass(MapJoin.class); // 设置map和reduce类 调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(MapJoinMapper.class); // 设置map端输出的key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); // 将本地的一个文件缓存到分布式的maptask任务的机器中 // 一定是缓存的分布式系统hdfs的文件 URI uri = new Path("/user.txt").toUri(); URI[] files = new URI[] {uri}; // 设置分布式缓存的文件 可以缓存多个文件 // 设置reduce的key-value的类型 结果的最终输出 //设置reducetask的个数 默认1个 //job.setNumReduceTasks(3); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("/join/input")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("/join/res")); // 提交任务 参数等待执行 job.waitForCompletion(true) ; } }
User
public class User { private String uid ; private String name ; private int age ; private String friend ; public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getFriend() { return friend; } public void setFriend(String friend) { this.friend = friend; } @Override public String toString() { return name+","+age+","+friend ; } }
3.高效topN