1. flink简介
1.1 什么是flink
Apache Flink是一个分布式大数据处理引擎,可以对有限数据流(如离线数据)和无限流数据及逆行有状态计算(不太懂)。可以部署在各种集群环境,对各种大小的数据规模进行快速计算。
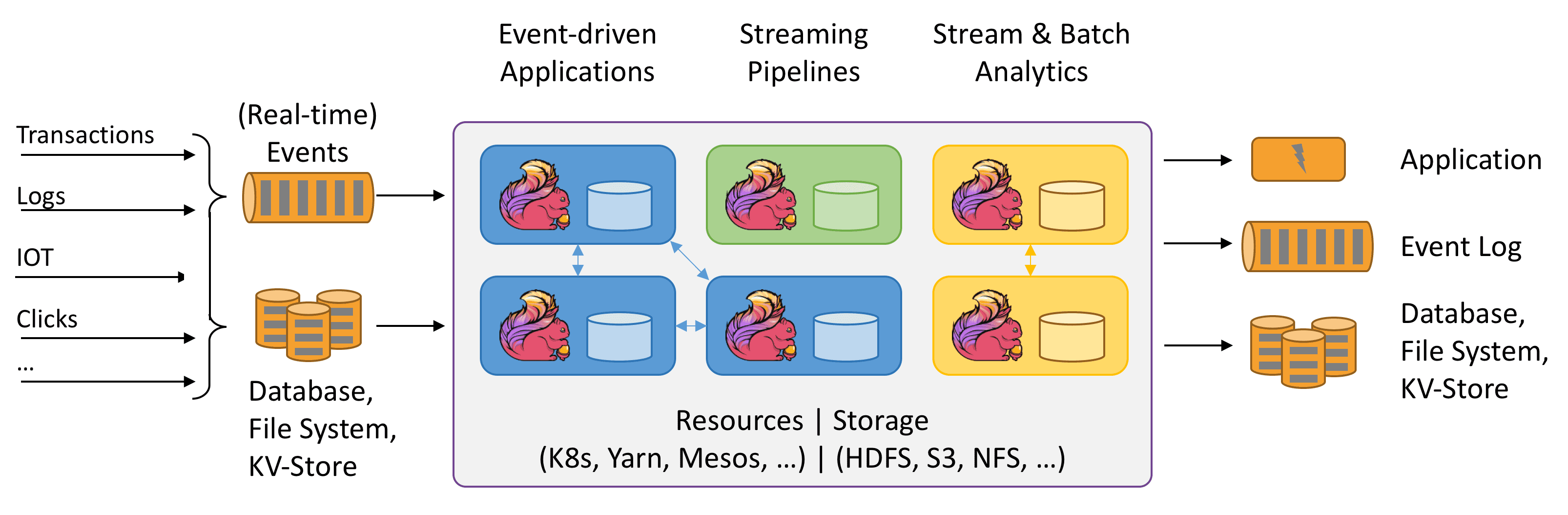
1.2 flink的架构体系
具体见文档
2. flink的安装
- 修改flink-conf.yaml
jobmanager.rpc.address: feng05 // 注意,此处冒号后需要空一格,并且参数要顶行写(yaml文件格式的规定,否则会报错) taskmanager.numberOfTaskSlots: 2
- 将配置好的Flink安装包拷⻉贝到其他节点
for i in {4..7}; do scp -r flink-1.10.1/ feng05:$PWD; done
- 启动集群(standalone模式)
bin/start-cluster.sh
- 查看Java进程(jps)
StandaloneSessionClusterEntrypoint (JobManager,即Master)
TaskManagerRunner (TaskManager,即Worker)
- 访问JobManager的web管理界面
feng05:8081
3. flink提交任务的两种方式
第一种:通过web页面提交
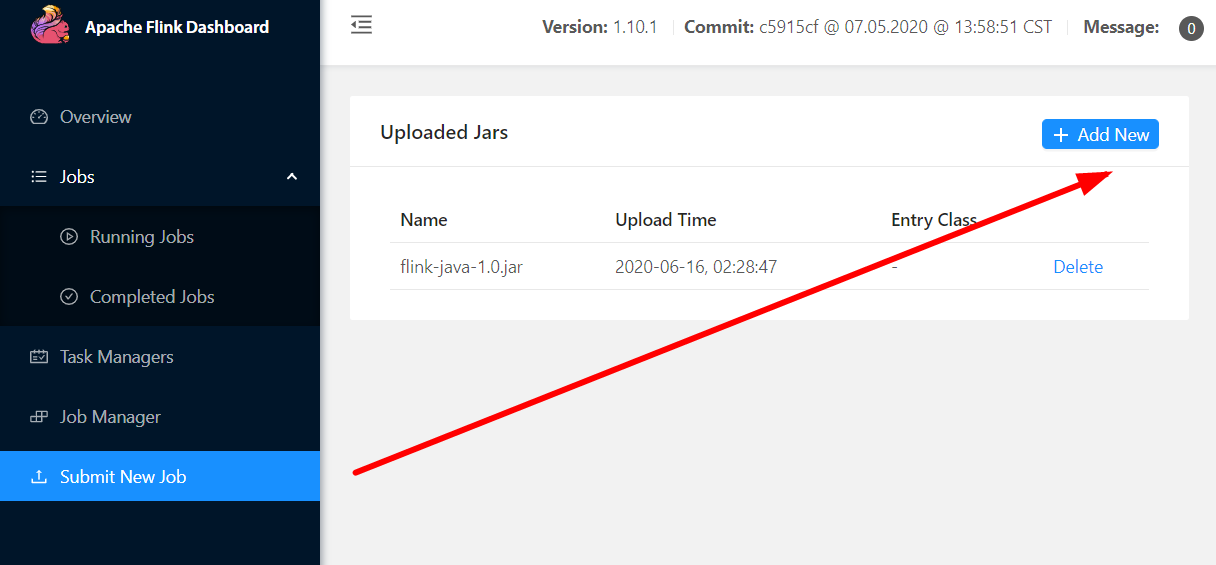
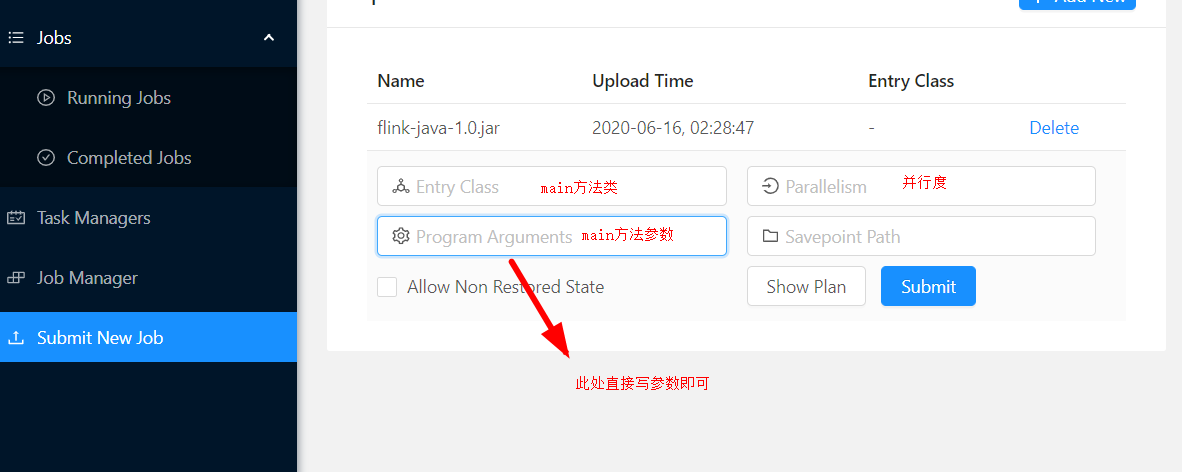
第二种:通过命令行提交
./flink run -m feng05:8081 -p 4 -c cn._51doit.flink.day1.HelloFlink /root/flink-in-action-1.0-SNAPSHOT.jar --hostname feng05 --port 8888
4.flink快速入门
4.0 创建flink工程
- java形式(window上)
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.10.1 -DgroupId=cn._51doit.flink -DartifactId=flink-java -Dversion=1.0 -Dpackage=cn._51doit.flink -DinteractiveMode=false
- scala形式
同理
- 也可以直接在IDEA上创建相应的maven项目,导入pom文件(这里jar的版本不好弄,所以直接用上面的命令更方便)
4.1 wordCount案例
StreamWordCount(匿名内部类的形式)


package cn._51doit.flink.day01; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class StreamWordCount { public static void main(String[] args) throws Exception { // 创建一个Stream计算执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 调用Source创建DataStream DataStreamSource<String> lines = env.socketTextStream(args[0], Integer.parseInt(args[1])); int parallelism = lines.getParallelism(); // DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { // @Override // public void flatMap(String line, Collector<String> out) throws Exception { // String[] words = line.split(" "); // for (String word : words) { // out.collect(word); // } // } // }); // SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() { // @Override // public Tuple2<String, Integer> map(String word) throws Exception { // return Tuple2.of(word, 1); // } // }); SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1)); } } }); KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0); SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyed.sum(1); //Transformation 结束 //调用Sink summed.print(); //执行程序 env.execute("StreamWordCount"); } }
LambdaStreamWordCount(lambda的形式)
package cn._51doit.flink.day01; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; public class LambdaStreamWordCount { public static void main(String[] args) throws Exception { // 创建一个stream计算的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream("feng05", 8888); // SingleOutputStreamOperator<String> words = lines // .flatMap((String line, Collector<String> out) -> Arrays.asList(line.split(" ")).forEach(out::collect)) // .returns(Types.STRING); // // SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words // .map(word -> Tuple2.of(word, 1)) // .returns(Types.TUPLE(Types.STRING, Types.INT)); SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap((String line, Collector<Tuple2<String, Integer>> out)->{ Arrays.stream(line.split(" ")).forEach(w -> out.collect(Tuple2.of(w, 1))); }).returns(Types.TUPLE(Types.STRING, Types.INT)); SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(0).sum(1); result.print(); env.execute(); } }
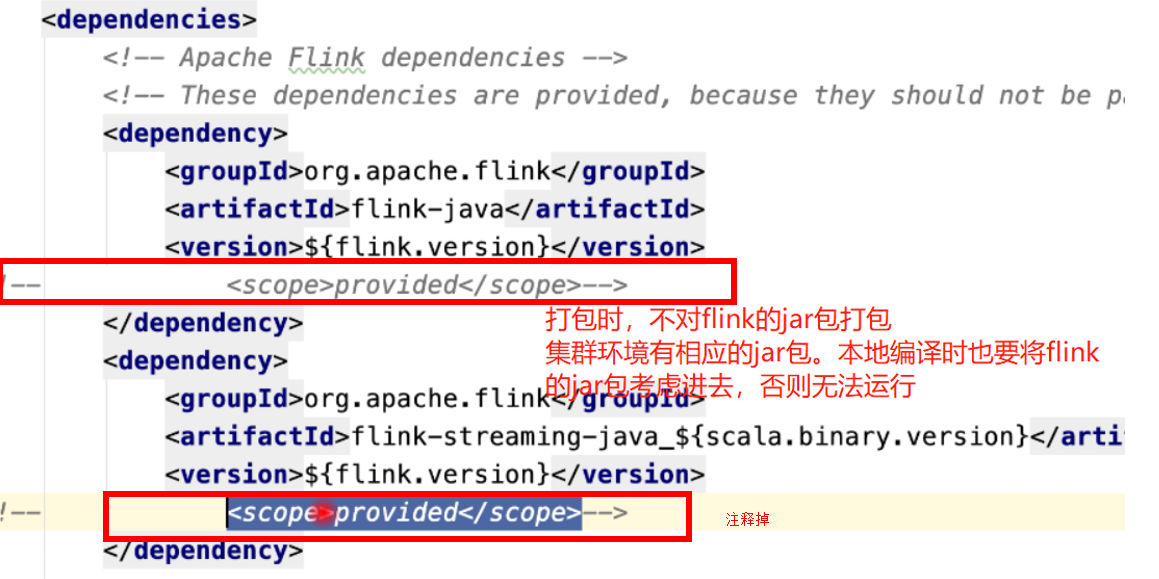
自己运行时遇到的小问题
5.source
- 单并行source
只有一个source来产生数据,如fromCollection、socketTextStream
- 双并行source
有多个source实例来产生数据
6 常用算子
6.1 keyBy
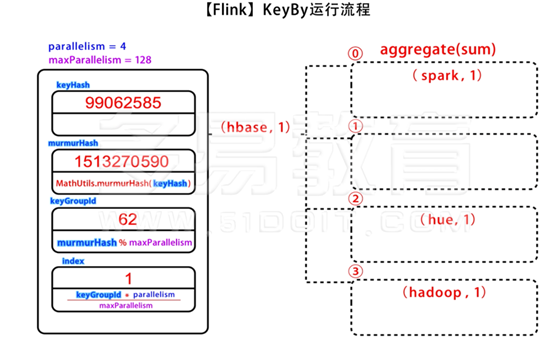
- 分组的对象是元组中的数据,可以直接指定角标,而且可以是多个
package cn._51doit.flink.day01; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class KeyByDemo1 { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream("localhost", 8888); //辽宁省,沈阳市,1000 SingleOutputStreamOperator<Tuple3<String, String, Double>> provinceCityAndMoney = lines.map(new MapFunction<String, Tuple3<String, String, Double>>() { @Override public Tuple3<String, String, Double> map(String line) throws Exception { String[] fields = line.split(","); String province = fields[0]; String city = fields[1]; double money = Double.parseDouble(fields[2]); return Tuple3.of(province, city, money); } }); KeyedStream<Tuple3<String, String, Double>, Tuple> keyed = provinceCityAndMoney.keyBy(0, 1); SingleOutputStreamOperator<Tuple3<String, String, Double>> summed = keyed.sum(2); summed.print(); env.execute(); } }
- 分组的对象不是元组中的元素,比如javabean中定义的字段,这个时候只能按照一个字段分组
package cn._51doit.flink.day01; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class KeyByDemo2 { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream("localhost", 8888); //辽宁省,沈阳市,1000 SingleOutputStreamOperator<OrderBean> provinceCityAndMoney = lines.map(new MapFunction<String, OrderBean>() { @Override public OrderBean map(String line) throws Exception { String[] fields = line.split(","); String province = fields[0]; String city = fields[1]; double money = Double.parseDouble(fields[2]); return new OrderBean(province, city, money); } }); KeyedStream<OrderBean, Tuple> keyed = provinceCityAndMoney.keyBy("province", "city"); SingleOutputStreamOperator<OrderBean> res = keyed.sum("money"); //provinceCityAndMoney.keyBy(OrderBean::getProvince) 只能按照一个字段分组 res.print(); env.execute(); } }
6.2 max和min
min、max返回分组的字段和参与比较的数据,如果有多个字段,其他字段的返回值是第一次出现的数据。
package cn._51doit.flink.day01; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class MinMaxDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream("localhost", 8888); //省份,城市,人数 SingleOutputStreamOperator<Tuple3<String, String, Integer>> provinceCityAmount = lines.map(line -> { String[] fields = line.split(","); String province = fields[0]; String city = fields[1]; Integer amount = Integer.parseInt(fields[2]); return Tuple3.of(province, city, amount); }).returns(Types.TUPLE(Types.STRING, Types.STRING, Types.INT)); KeyedStream<Tuple3<String, String, Integer>, Tuple> keyed = provinceCityAmount.keyBy(0); //min、max返回分组的字段和参与比较的数据,如果有多个字段,其他字段的返回值是第一次出现的数据。 SingleOutputStreamOperator<Tuple3<String, String, Integer>> max = keyed.max(2); max.print(); env.execute(); } }
比如
江西,鹰潭,1000 //先输入此数据,max后得到本身 江西,南昌,2000 //输入该数据,max后得到的是江西,鹰潭,2000 并不能得到南昌字段
解决办法=====>使用maxBy和minBy
6.3 maxBy和minBy
package cn._51doit.flink.day01; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class MinByMaxByDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream("localhost", 8888); //省份,城市,人数 江西,鹰潭,1000 江西,南昌,2000 SingleOutputStreamOperator<Tuple3<String, String, Integer>> provinceCityAmount = lines.map(line -> { String[] fields = line.split(","); String province = fields[0]; String city = fields[1]; Integer amount = Integer.parseInt(fields[2]); return Tuple3.of(province, city, amount); }).returns(Types.TUPLE(Types.STRING, Types.STRING, Types.INT)); KeyedStream<Tuple3<String, String, Integer>, Tuple> keyed = provinceCityAmount.keyBy(0); //minBy、maxBy返回最大值或最小值数据本身(全部字段都返回)。 SingleOutputStreamOperator<Tuple3<String, String, Integer>> max = keyed.maxBy(2); max.print(); env.execute(); } }
这种形式又会出现另外一个难点,就是当按照key进行分组后,比较大小的值一样时,其它字段返回的值又是第一次出现的数据,解决办法===>加一个参数(可以从源码中得出此结论),如下:加上false
SingleOutputStreamOperator<Tuple3<String, String, Integer>> max = keyed.maxBy(2, false);
此时其它字段返回的值就是最后依次出现的字段了。
6.4 connect
DataStream转换成ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了同一个流中,内部依然保持各自的数据和形式不不发生任何变化,两个流相互独?立。
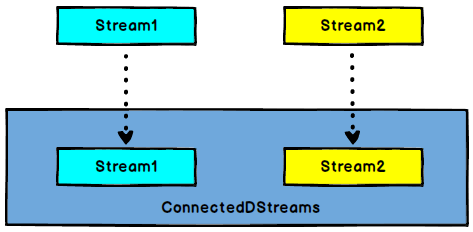
ConnectDemo
package cn._51doit.flink.day02; import org.apache.flink.streaming.api.datastream.ConnectedStreams; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoMapFunction; public class ConnectDemo2 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> words = env.fromElements("a", "b", "c", "d", "e"); DataStreamSource<Integer> nums = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8); ConnectedStreams<Integer, String> connected = nums.connect(words); SingleOutputStreamOperator<String> res = connected.map(new CoMapFunction<Integer, String, String>() { @Override public String map1(Integer value) throws Exception { return value * 10 + ""; } @Override public String map2(String value) throws Exception { return value.toUpperCase(); } }); res.print(); env.execute(); } }
6.5 union
DataStream转换成DataStream,对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
注意:unoin要求两个流的数据类型必须一致,并且不去重
UnionDemo
package cn._51doit.flink.day02; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class UnionDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Integer> num1 = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9); DataStreamSource<Integer> num2 = env.fromElements( 10, 11, 12); //unoin要求两个流的数据类型必须一致 DataStream<Integer> union = num1.union(num2); union.print(); env.execute(); } }
6.6 split+select
DataStream转换成SplitStrram,根据某些特征把一个DataStream拆分成两个或者多个DataStream。split一般是结合select使用的,若是将一个数据划分成多个类,split+select的效率会更高,若只是筛选出一个类型的数据,则用filter效率高些。