学习一个新框架方法:
推荐:官网+源码
跪在坚持
hadoop.apache.org
spark.apache.org
flink.apache.org
storm.apache.org
Hadoop:由HDFS/YARN/Map Reduce构成
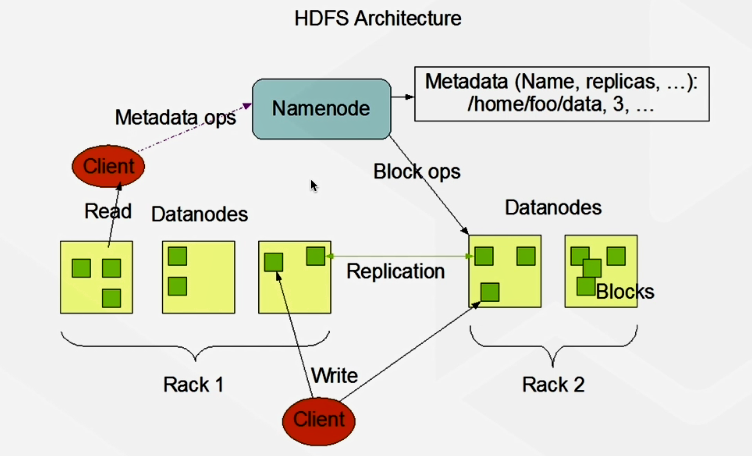
HDFS 一个NameNode 和多个DATa Node 构成
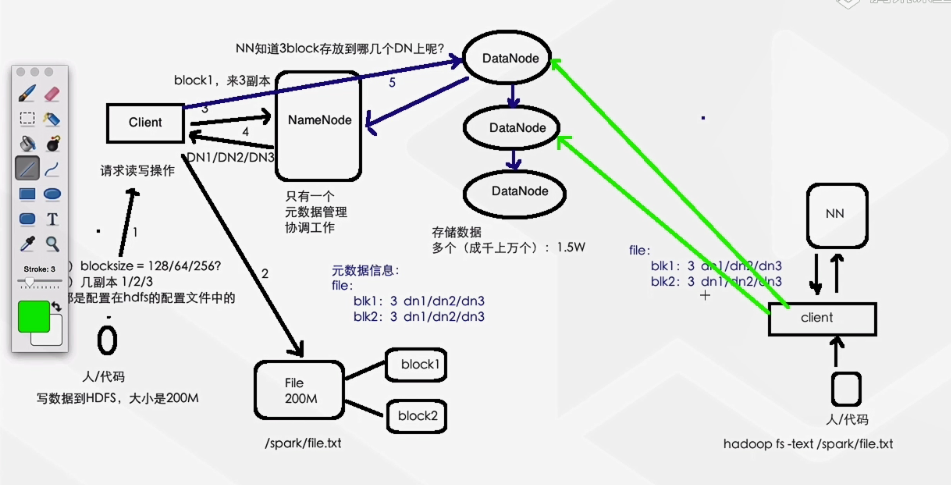
Namenode: 管理文件系统命名空间。(1个)引发一个单点故障问题(Single Point of ailure) ==> HA , Namenode它存放一些元数据(metadata)信息
metadata:谁创建的?权限?文件对应的block块在哪里
DataNode: 负责数据的存储,和Namenode之间有心跳机制,
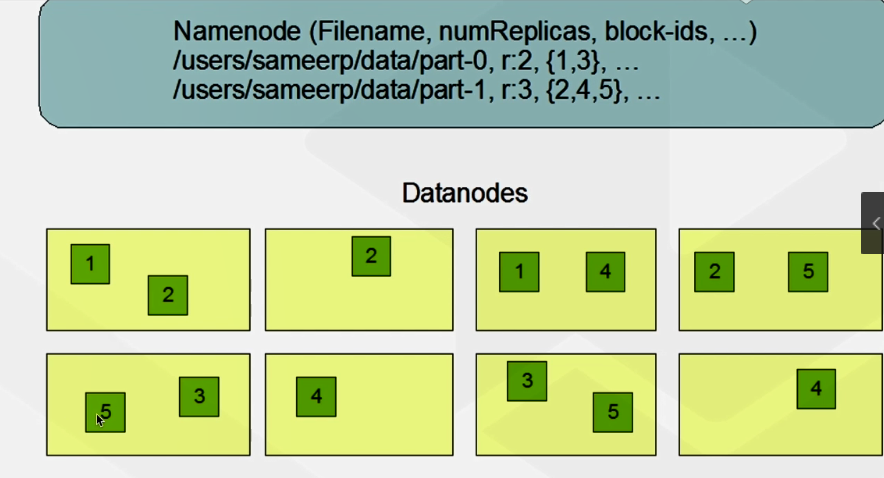
Block:文件存入HDFS,是按照block进行拆分 每个块大小为128M
客户端发起读取,从namenode拿元数据信息,才能知道去哪些DataNode读数据
下图为HDFS架构图,参照官网截取下来的
下图为BLock容错机制图解,参考官网
文件读写到HDFS图解:
HA 高可用 HDFS 架构图

NN active 对外提供服务,NN standby同步NNactive的一个状态,当NNactive挂了之后,NNstandby可以快速的切换。
NNactive 和NN standby 处于俩个独立的机器上,当出现问题是,它俩是如何进行切换的?
通过主和备,然后通过各自的一个进程监控它,然后同过zookper来进行一个状态的切换,不需要人工进行干预
HA配置请参考官网