HTTP协议是什么?
你浏览的每一个网页都是基于 HTTP 协议呈现的,HTTP 协议是互联网应用中,客户端(浏览器)与服务器之间进行数据通信的一种协议。协议中规定了客户端应该按照什么格式给服务器发送请求,同时也约定了服务端返回的响应结果应该是什么格式。
只要大家都按照协议规定方式发起请求和返回响应结果,任何人都可以基于HTTP协议实现自己的Web客户端(浏览器、爬虫)和Web服务器(Nginx、Apache等)。
HTTP 协议本身是非常简单的。它规定,只能由客户端主动发起请求,服务器接收请求处理后返回响应结果,同时 HTTP 是一种无状态的协议,协议本身不记录客户端的历史请求记录。

HTTP 协议是如何规定请求格式和响应格式的呢?换言之,客户端按照什么格式才能正确发起 HTTP 请求呢?服务端按照什么格式返回响应结果客户端才能正确解析?
HTTP 请求
HTTP 请求由3部分组成,分别是请求行、请求首部、请求体,首部和请求体是可选的,并不是每个请求都需要的。

请求行
请求行是每个请求必不可少的部分,它由3部分组成,分别是请求方法(method)、请求URL(URI)、HTTP协议版本,以空格隔开。
HTTP协议中最常用的请求方法有:GET、POST、PUT、DELETE。GET 方法用于从服务器获取资源,90%的爬虫都是基于GET请求抓取数据。
请求 URL 是指资源所在服务器的路径地址,比如上图的例子表示客户端想获取 index.html 这个资源,它的路径在服务器 http://foofish.net 的根目录(/)下面。
请求首部
因为请求行所携带的信息量非常有限,以至于客户端还有很多想向服务器要说的事情不得不放在请求首部(Header),请求首部用于给服务器提供一些额外的信息,比如 User-Agent 用来表明客户端的身份,让服务器知道你是来自浏览器的请求还是爬虫,是来自 Chrome 浏览器还是 FireFox。HTTP/1.1 规定了47种首部字段类型。HTTP首部字段的格式很像 Python 中的字典类型,由键值对组成,中间用冒号隔开。比如:
User-Agent: Mozilla/5.0
因为客户端发送请求时,发送的数据(报文)是由字符串构成的,为了区分请求首部的结尾和请求体的开始,用一个空行来表示,遇到空行时,就表示这是首部的结尾,请求体的开始。
请求体
请求体是客户端提交给服务器的真正内容,比如用户登录时的需要用的用户名和密码,比如文件上传的数据,比如注册用户信息时提交的表单信息。
现在我们用 Python 提供的最原始API socket 模块来模拟向服务器发起一个 HTTP 请求
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
# 1. 与服务器建立连接
s.connect(("www.seriot.ch", 80))
# 2. 构建请求行,请求资源是 index.php
request_line = b"GET /index.php HTTP/1.1"
# 3. 构建请求首部,指定主机名
headers = b"Host: seriot.ch"
# 4. 用空行标记请求首部的结束位置
blank_line = b"
"
# 请求行、首部、空行这3部分内容用换行符分隔,组成一个请求报文字符串
# 发送给服务器
message = b"
".join([request_line, headers, blank_line])
s.send(message)
# 服务器返回的响应内容稍后进行分析
response = s.recv(1024)
print(response)
HTTP 响应
服务端接收请求并处理后,返回响应内容给客户端,同样地,响应内容也必须遵循固定的格式浏览器才能正确解析。HTTP 响应也由3部分组成,分别是:响应行、响应首部、响应体,与 HTTP 的请求格式是相对应的。
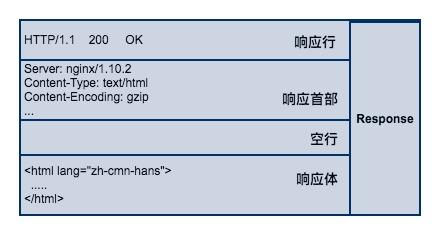
响应行
响应行同样也是3部分组成,由服务端支持的 HTTP 协议版本号、状态码、以及对状态码的简短原因描述组成。
状态码是响应行中很重要的一个字段。通过状态码,客户端可以知道服务器是否正常处理的请求。如果状态码是200,说明客户端的请求处理成功,如果是500,说明服务器处理请求的时候出现了异常。404 表示请求的资源在服务器找不到。除此之外,HTTP 协议还很定义了很多其他的状态码,不过它不是本文的讨论范围。
响应首部
响应首部和请求首部类似,用于对响应内容的补充,在首部里面可以告知客户端响应体的数据类型是什么?响应内容返回的时间是什么时候,响应体是否压缩了,响应体最后一次修改的时间。
响应体
响应体(body)是服务器返回的真正内容,它可以是一个HTML页面,或者是一张图片、一段视频等等。
我们继续沿用前面那个例子来看看服务器返回的响应结果是什么?因为我只接收了前1024个字节,所以有一部分响应内容是看不到的。
b'HTTP/1.1 200 OK
Date: Tue, 04 Apr 2017 16:22:35 GMT
Server: Apache
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Set-Cookie: PHPSESSID=66bea0a1f7cb572584745f9ce6984b7e; path=/
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
118d
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html;charset=iso-8859-1" />
<meta http-equiv="content-language" content="en" />
...
</html>
从结果来看,它与协议中规范的格式是一样的,第一行是响应行,状态码是200,表明请求成功。第二部分是响应首部信息,由多个首部组成,有服务器返回响应的时间,Cookie信息等等。第三部分就是真正的响应体 HTML 文本。
至此,你应该对 HTTP 协议有一个总体的认识了,爬虫的行为本质上就是模拟浏览器发送HTTP请求,所以要想在爬虫领域深耕细作,理解 HTTP 协议是必须的。
当然 HTTP 协议远不止这么一点内容,也根本不可能用一篇文章就试图把它全部讲清楚,我在这里也只是抛砖引玉,想深入了解HTTP的,可参考「Python之禅」推荐的延伸阅读。