python爬虫分析冰雪奇缘影评,并对关键字生成词云
1,从豆瓣电影上进行爬取影评,并保存为bxqy.csv文件
import requests;
from lxml import etree
import time
url = "https://movie.douban.com/subject/25887288/reviews?start=%d"
'''
使用ctrl+r键进行替换,使用(.*?): (.*)来匹配headers进行'$1': '$2',将其替换为字典替换
'''
# 请求头必须要为字典
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'bid=2kVXwdWZeMw; ll="108301"; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1577408430%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DZ9ckN1KJW1JO8LetqcHNw_EpRXfP8M7thIHnPSuuwCunbidpPUid9bMYnngvA-dS%26wd%3D%26eqid%3Da4ee110000486cf8000000065e0557a7%22%5D; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.1534063425.1569670281.1569670281.1577408430.2; __utmz=30149280.1577408430.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=30149280; __utmc=223695111; __utma=223695111.528350327.1577408430.1577408430.1577408430.1; __utmz=223695111.1577408430.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmt=1; __gads=ID=0379800c7797856f:T=1577408438:S=ALNI_Man_1mimIVqMBoWKYD4NxKArBMQQQ; __yadk_uid=ddEOZgUO3cWlTAq7yge0eufiInrHkSje; __utmt=1; __utmb=30149280.1.10.1577408430; _vwo_uuid_v2=DD6DFBB7AA0D3A60734ECB8E8B5188216|fbc6c67dc4eac6e41dd6678dfe11a683; dbcl2="208536278:6OQfpDVXgQc"; push_noty_num=0; push_doumail_num=0; ck=8rj9; _pk_id.100001.4cf6=4cb7f01585a36431.1577408430.1.1577408979.1577408430.; __utmb=223695111.21.10.1577408430',
'Host': 'movie.douban.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36 Edg/79.0.309.56',
}
if __name__ == '__main__':
fp = open("./bxqy.csv", mode="w", encoding="utf-8")
fp.write("author comment reply
")
for i in range(25):
url_movies = url%(20*i)
response = requests.get(url_movies,headers=headers)
response.encoding = 'utf-8'
text = response.text
# with open('./movies.html', 'w', encoding='utf-8') as fp:
# fp.write(text)
html = etree.HTML(text)
# xpath解析时使用div[@id=]的方式解析位置
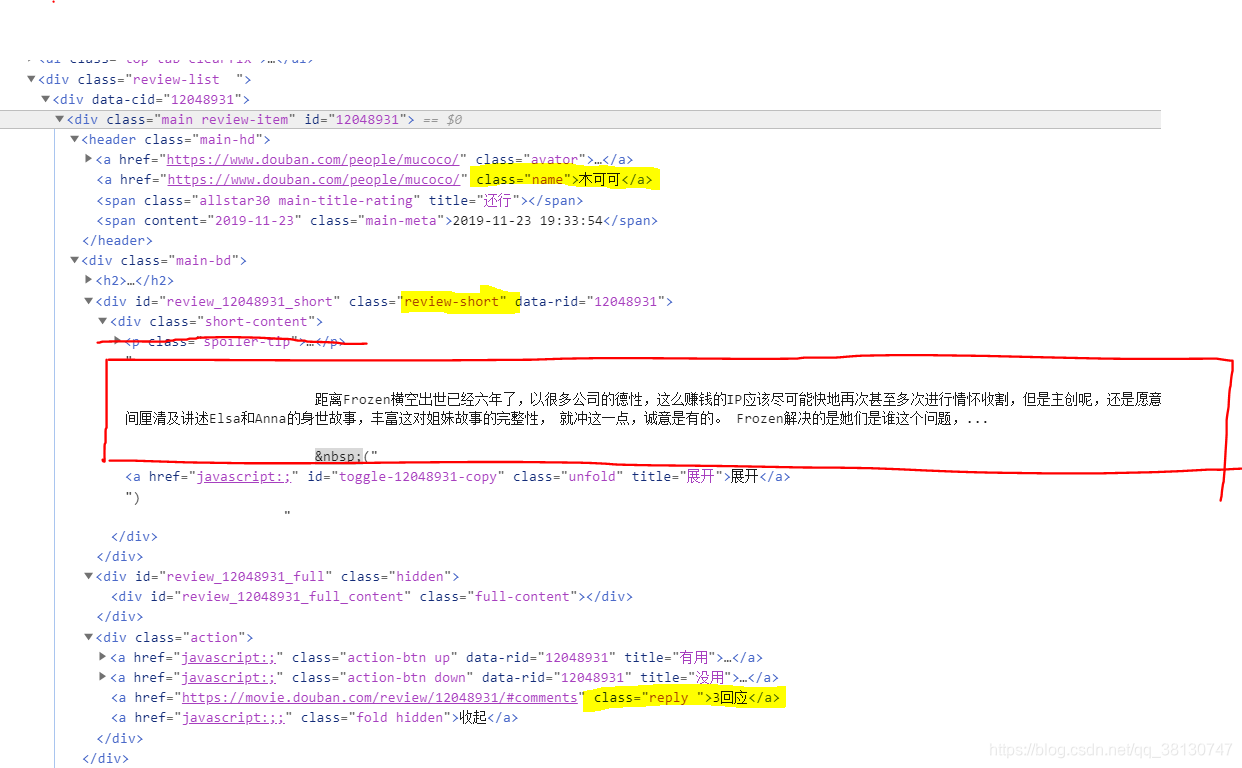
commets = html.xpath('//div[@class="review-list "]/div[@data-cid]')
for commet in commets:
author = commet.xpath(".//a[@class='name']/text()")[0].strip() # 获取作者名字
content = commet.xpath(".//div[@class='short-content']/text()")[1][:-1].strip()
reply = commet.xpath(".//a[@class='reply ']/text()")[0][:-2].strip()
# print("%s | %s | %s" % (author,content,reply))
fp.write("%s %s %s
" % (author,content,reply))
# fp.write("-----------------------------第%d页------------------------------
"%(i+1))
print("-----------------------------第%d页的数据保存成功------------------------------
"%(i+1))
time.sleep(1)
fp.close()
- 1,分析url


我们可以清楚的看到,每一页有20条评论,并且都是以start进行传递的,所以我们就可以构造上面代码中url
-
2,由于请求头,如果自己不登陆的话,当你请求时,返回回来的是登陆页面也就请求不到想要的数据,所以要登陆。
-
3,获取请求头,(记得要刷新一下浏览下,才会有)
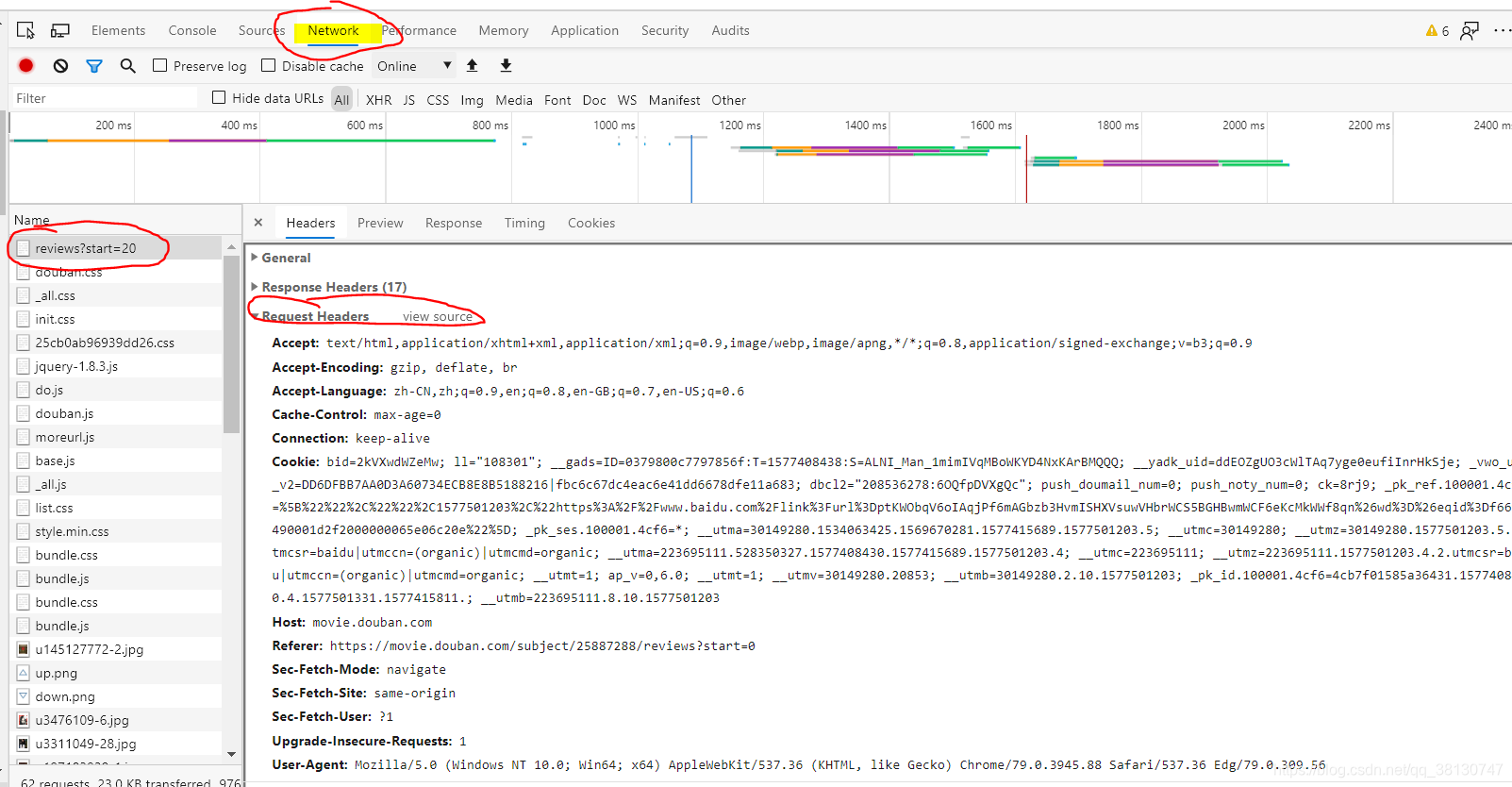
-
4,对返回的数据进行xpath解析,
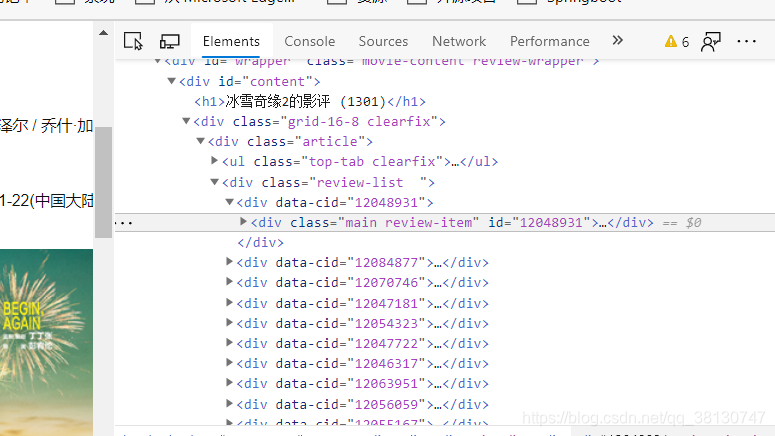
-
我们可以很清晰的看出html结构,通过xpath的语法进行解析。
-
具体语法,可以查看下面这篇博客,写的很清晰
Python爬虫之Xpath语法
2,使用SnowNLP进行情感分析
import pandas as pd
from snownlp import SnowNLP
pd.set_option("display.max_columns", 5)
def convert(comment):
# 情感分析
snownlp = SnowNLP(str(comment))
return snownlp.sentiments # 0(消极)~1(积极)
if __name__ == '__main__':
#DataFrame数据格式由行列组成
data = pd.read_csv('bxqy.csv', " ")
# print(data.head())
# print(data.shape)
# 获取数据,进行情感分析,DataFrame就会增加1列
# 属性名为“情感评分”
data["情感评分"] = data.comment.apply(convert)
data.sort_values(by="情感评分", ascending=False, inplace=True)
# 保存数据
data.to_csv("bxqy_snow.csv", sep=" ", index=False, encoding='utf-8')
# print("积极
")
print(data[:10])
# print("消极
")
print(data[-10:])
- snowlp库是一个分析中文情感的库,通过返回0-1的数值解析判断,是否是积极化还是消极
3,对关键词进行jieba分词,并对最重要的的关键字进行绘制条形图和生成词云,并保存。
import pandas as pd
import jieba
from jieba import analyse
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import wordcloud
if __name__ == '__main__':
data = pd.read_csv("./bxqy.csv", sep=' ')
# 获取评论信息
comments = ",".join([str(c) for c in data["comment"].tolist()])
# print(comments)
# 使用jieba库进行分词
gen = jieba.cut(comments)
words = " ".join(gen)
# print(words)
# 对于分好的词进行分析
tags = analyse.extract_tags(words, topK=500,withWeight=True)
word_result = pd.DataFrame(tags, columns=["词语", "重要性"])
word_result.sort_values(by="重要性", inplace=True, ascending=False) # 从大到小排序
# print(word_result)
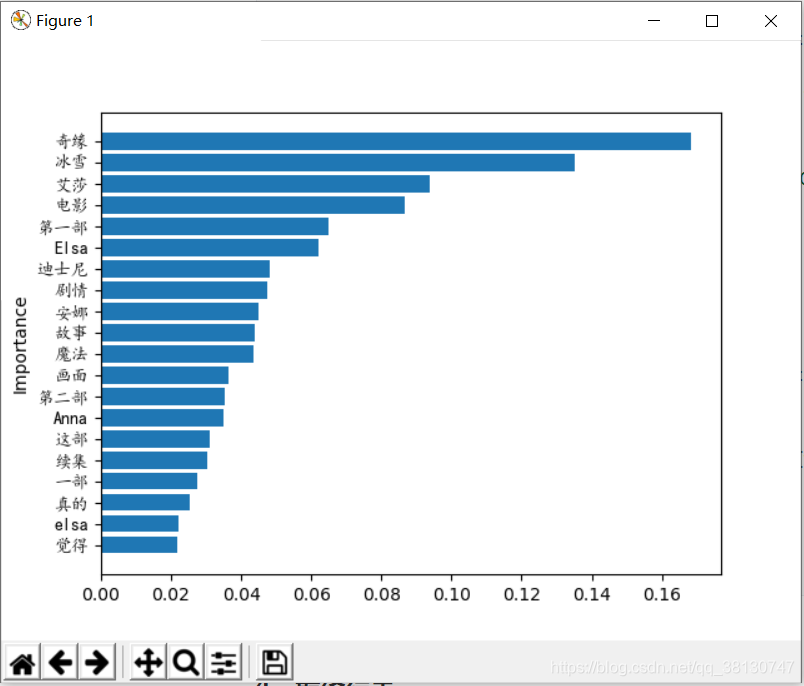
# 可视化,对最重要的20个
plt.barh(y=np.arange(0,20), width=word_result[1:21]["重要性"][::-1])
plt.ylabel("Importance")
plt.yticks(np.arange(0,20), labels=word_result[1:21]["词语"][::-1], fontproperties="KaiTi")
# 对条形图进行保存
plt.savefig("./冰雪奇缘关键词条形图.jpg", dpi=200)
plt.show()
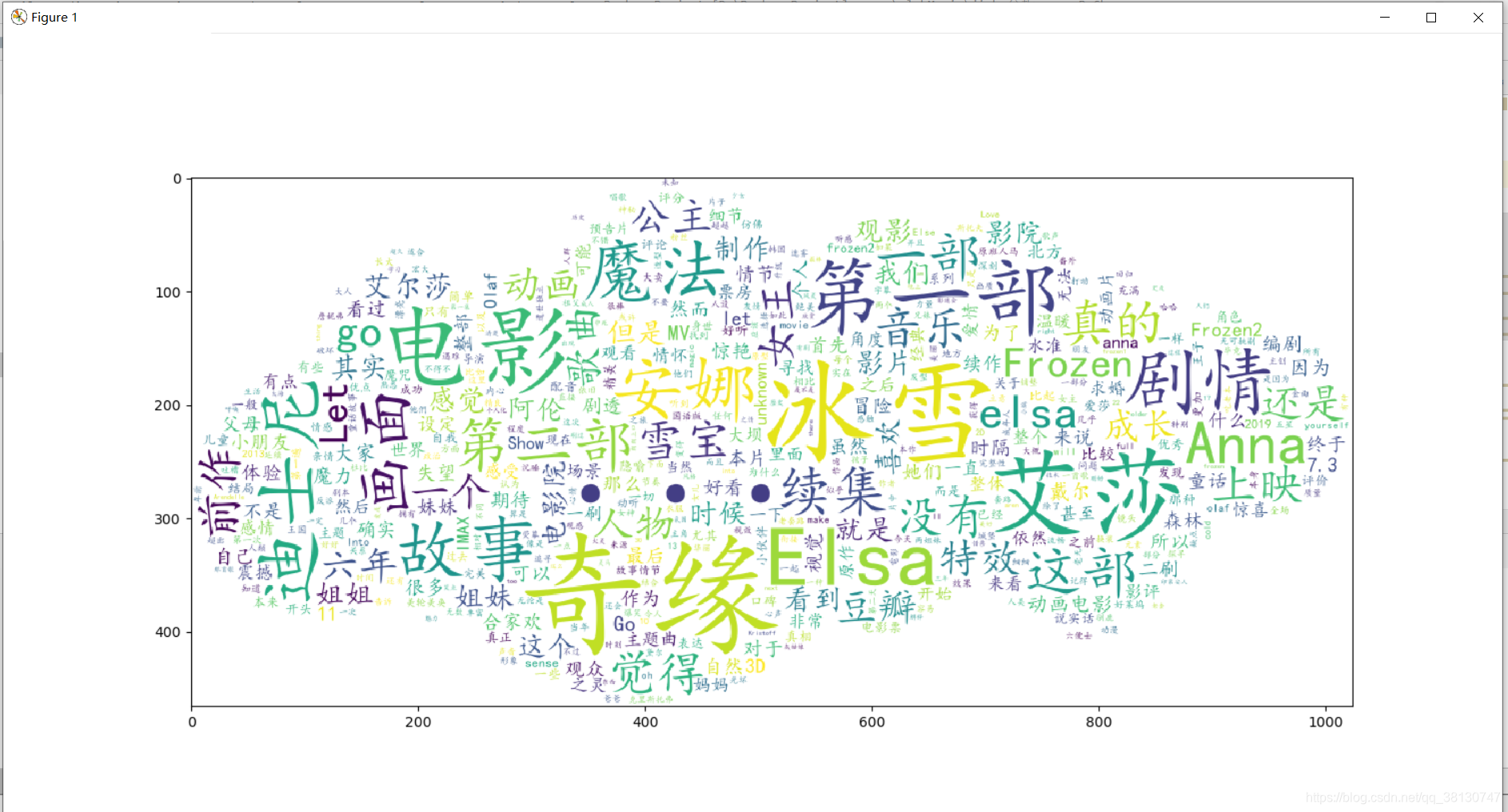
# 生成词云,pip install wordcould
heart = np.array(Image.open("./cloudf2.jpg")) # 词云图片
# 将jieba分词的结果转换为字典
words = dict(tags)
# 使用楷体进行生成,楷体文件simkai.ttf可以从本地c:/windows/font文件夹下获取
cloud = wordcloud.WordCloud(width=1080,height=865,font_path="./simkai.ttf", mask=heart,
background_color="white", max_font_size=150, max_words=500)
word_cloud = cloud.generate_from_frequencies(words)
plt.figure(figsize=(15, 15))
plt.imshow(word_cloud)
plt.savefig("./冰雪奇缘词云.jpg", dpi=200)
plt.show()
- 使用wordcloud库,进行词云生成并保存
4,最终结果
- 项目结构,以及生成的文件