MySQL源码关于链表的实现在ut0lst.h文件中,其设计思路与常规略有不同,基本思想是指针嵌于对象之内,如下图所示。
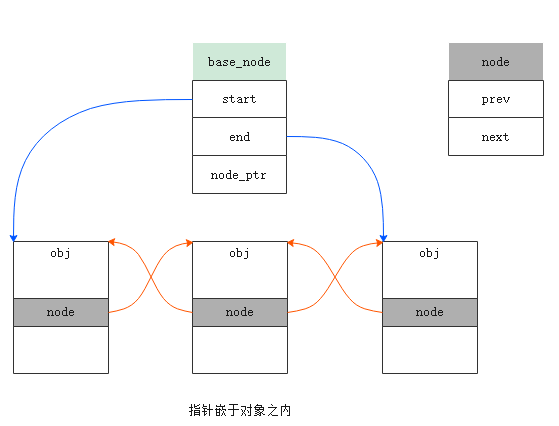
在这种实现方式下,构造一个链表需要同时指定对象类型和对象内指针节点的地址。为什么这么复杂呢?我们对比一下C++11标准库中list的实现,发现其就是一个模板类,构造一个list只需要传入对象类型即可,这更符合我们的理解。研究了下源码,也没找到这样设计的合理之处。突然想起了MySQL磁盘数据文件的存储格式,发现这种设计与其很相符。
简单来说,MySQL的数据文件(其实就是一个namespace)被分成了很多extent,每个extent包含64个page,也就是1M。那如何管理这些extent呢?没256个extent分为一组,每组的第一个page包含了256个extent_entry,每个entry包含64个page的状态和一个指针node,分别指向前后的entry,跟上面的图是不是很像?
现在来说一下为什么要这样设计。在内存中,我们可以使用两种设计方式:指针嵌于对象之内和对象嵌于节点之内。为什么C++11中list的实现只需要传入对象类型就可以呢?因为在代码里面我们可以直接通过符号来获取prev和next指针的值,那你想想磁盘上面list能这样做吗?肯定不行了啊,在磁盘上面我们只能通过地址或偏移来获取值。
其实上面说了这么多,总结下来就是一个问题:我们怎么把list持久化到磁盘中?上面给出了一种很好的实现。
再延伸一个问题:我们怎么把B+Tree持久化到磁盘中?MySQL索引就是这么干的,具体可以在网上找下这方面的介绍。
为什么不用C++11中list的实现?
以insert为例,首先我们要构造一个对象,然后再insert,这里面涉及到一次拷贝构造,降低了效率。(尽管是通过引用传参,但insert函数要把这个对象拷贝到list中)那如果把对象的地址insert进去呢?对象的析构怎么办。正常使用pop_back或pop_front时会自动调用析构函数,如果对象是一个指针,就存在析构的问题。
struct Node {
Node() {
cout << "Construct." << endl;
}
Node(const Node &node) {
cout << "Copy construct." << endl;
}
};
int main() {
list<Node> l;
l.push_back(Node());
return 0;
}
Output:
Construct.
Copy construct.
如果采用MySQL的实现方案,可以直接在构造函数里面把当前对象的地址加入到list中,不需要再insert,效率极高,并且这样一来,我们只需要关注对象的创建,不需要关注list的更新。
MySQL源码中关于sys_var的实现也是这种方式,每个sys_var中都会包含一个next指针,用于串起整个sys_var,并用一个all_sys_vars作为base节点。