从这篇文章开始,我会写好一个系列的文章,就叫掌握机器学习数学基础之XX(重点知识)吧,主要讲述在机器学习中主要的一些数学基础。
为什么要写这个系列?
- 网上文章过于全面,一上来就推荐什么MIT线性代数,推荐各种微积分,推荐什么《微积分入门》啊,《概率论入门》啊等等,甚至很多还是英文版的,还要学很多英文术语才能看懂,我觉得没有必要全看,因为就像MIT的线性代数,很多是我们在机器学习中用不到或者用的及其少但又很难理解的。什么马尔可夫矩阵,快速傅里叶变换,若尔当形,哇,有点头晕....
- 网上文章写的过于简略,机器学习虽说不用把多门数学完全学通,但和数学还是有很大关系的,很多文章一篇想概括所有在机器学习中重要的数学基础。不赞同!写的太简略了,还不如写个目录,或者跳过太多重要数学基础,还不如不写。
- 梳理并复习,我会尽量截取我认为重要的,并会指出在机器学习哪里有应用的数学基础,并尽量写的通俗,亦写的有深度。有助于我复习,并达到更新专栏的作用!
注意:我将写下我认为于机器学习高度相关的数学基础,很多知识是其他地方学习的,主要来自《deep learning》,我也只是知识的搬运工以及加上自己的看法。
下面开始分节叙述,线性代数部分主要包括如下:
- 标量、向量、矩阵和张量
- 矩阵向量的运算
- 单位矩阵和逆矩阵
- 行列式
- 方差,标准差,协方差矩阵
- 范数
- 特殊类型的矩阵和向量
- 特征分解以及其意义
- 奇异值分解及其意义
- Moore-Penrose 伪逆
- 迹运算
标量、向量、矩阵和张量
- 标量:一个标量就是一个单独的数,一般用小写的变量名称表示。当然,当我们介绍标量时,要明确它们是哪种类型的数值。这个在写论文时要注意,比如:在定义自然数标量时,我们可能会说”令n ∈ N表示元素的数目”。
- 向量:在物理学和工程学中,几何向量更常被称为矢量,这个学过高中数学和物理的就知道,但在线性代数中,经过进一步的抽象,大小和方向的概念亦不一定适用,但我们可以简单的理解为一列数,通过这列数中的索引,我们可以确定每个单独的数。通常会赋予向量粗体的小写名称。当我们需要明确表示向量中的元素时,我们会将元素排列成一个方括号包围的纵柱(如下图):

- 矩阵:矩阵是二维数组,其中的每一个元素被两个索引而非一个所确定。我们通常会赋予矩阵粗体的大写变量名称,比如A。 如果一个实数矩阵高度为m,宽度为n,那么我们说
,当我们到明确表达矩阵的时候,我们将它们写在用方括号包围起来的数组中,如下图:

- 张量:线性代数或几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解的话,我们可以将标量视为零阶张量,向量(矢量)视为一阶张量,那么矩阵就是二阶张量。例如,可以将任意一张彩色图片表示成一个三阶张量(就像C语言中的三维数组),三个维度分别是图片的高度、宽度和色彩数据。 使用字体 A 来表示张量 “A’’。张量 A 中坐标为 (i, j, k) 的元素记作
。
上面的知识重要性不言而喻,这些都不知道就别说学过机器学习了...几乎一切运算都是基于向量矩阵来进行的,而在tensorflow中,用张量来表示一切数据,并用来运算。
矩阵向量的运算
矩阵乘法:是矩阵运算中最重要的操作之一。两个矩阵 A 和 B 的 矩阵乘积(matrix product)是第三个矩阵 C。为了使乘法定义良好,矩阵 A 的列数必须和矩阵 B 的行数相等。如果矩阵 A 的形状是 m × n,矩阵 B 的形状是 n × p,那么矩阵C 的形状是 m × p。我们可以通过将两个或多个矩阵并列放置以书写矩阵乘法,例如C = AB.
具体地,该乘法操作定义为 :
举个例子,如下所示:
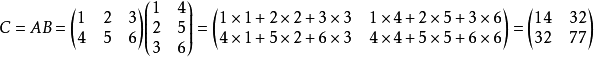
需要注意的是,两个矩阵的标准乘积不是指两个矩阵中对应元素的乘积。 不过,那样的矩阵操作确实是存在的,被称为元素对应乘积或者Hadamard乘积,记为A B
特别地,两个相同维数的向量和
的 点积(dot product)可看作是矩阵乘积
。我们可以把矩阵乘积 C =AB 中计算
的步骤看作是 A 的第 i 行和 B 的第 j 列之间的点积。注意,我们有时候也加两个向量的乘积为内积
矩阵乘积服从分配律:A(B + C) = AB + AC
矩阵乘积也服从结合律:A(BC) = (AB)C
但不同于标量乘积,矩阵乘积并不满足交换律(AB = BA 的情况并非总是满足)。
然而,两个向量的 点积(dot product)满足交换律 :
矩阵转置:
- 矩阵转置的结果为
结果为对称矩阵,由
,得证
矩阵的乘法和其他运算有必要深究,比如矩阵乘法的意义。在机器学习中,很多运算就是矩阵和向量的运算,而Hadamard乘积在反向传播推导中也有应用。
单位矩阵和逆矩阵
线性代数提供了被称为矩阵逆的强大工具。 对于大多数矩阵A,我们都能通过矩阵逆解析地求解。
为了描述矩阵逆,我们首先需要定义单位矩阵的概念。 任意向量和单位矩阵相乘,都不会改变。 我们将保持 维向量不变的单位矩阵记作
。 形式上
。
单位矩阵的结构很简单:所有沿主对角线的元素都是1,而所有其他位置的元素都是0。 如
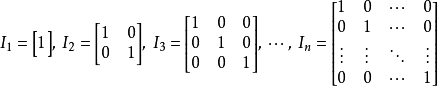
矩阵A的矩阵逆记作 ,其定义的矩阵满足如下条件
现在我们可以通过以下步骤求解:
由 得
由 得
最终:
求一个矩阵的逆矩阵比较简单,但是更加重要还有更加有用的是判断一个矩阵是否存在逆矩阵,这是一个重点难点,由于判别方式也非常的多种,这里就简述一些简单方法:
- 一切不是方阵(行数不等于列数)的矩阵都没有逆矩阵
- 可逆矩阵就是非奇异矩阵,非奇异矩阵也是可逆矩阵(奇异矩阵涉及到秩的运算,不是很必要学啊,但推荐去了解吧,如果不想学,那知道这句就好)
- 行列式等于0的方阵是奇异矩阵,也就是说行列式不等于0等价于是可逆矩阵
矩阵的求逆运算在机器学习中也有非常广泛的应用,比如逻辑回归,比如SVM等等,也是非常重要的,各类的论文中也会涉及到很多这样的运算,所以真的必不可少!
行列式
行列式,记作 det(A):是一个将方阵 A 映射到实数的函数。行列式等于矩阵特征值的乘积。行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或者缩小了多少。如果行列式是 0,那么空间至少沿着某一维完全收缩了,使其失去了所有的体积。如果行列式是 1,那么这个转换保持空间体积不变。
行列式也是一个很大的概念,深究起来非常方,如果不想了解很多,那只需要知道概念就好吧。
方差,标准差,协方差
方差:是衡量随机变量或一组数据时离散程度的度量,方差计算公式:
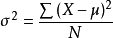
其中 为总体方差,
为变量,
为总体均值,
为总体例数。下面的标准差公式中亦相同。
标准差:也被称为标准偏差,或者实验标准差,公式为
标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。
为什么需要协方差?
我们知道,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的 大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的 猥琐程度跟他受女孩子欢迎程度是否存在一些联系。协方差就是这样一种用来度量两个随机变量关系的统计量。
协方差矩阵
理解协方差矩阵的关键就在于牢记它计算的是不同维度之间的协方差,而不是不同样本之间,拿到一个样本矩阵,我们最先要明确的就是一行是一个样本还是一个维度,心中明确这个整个计算过程就会顺流而下,这么一来就不会迷茫了
举个例子(例子来自这篇文章):
问题:
有一组数据(如下),分别为二维向量,这四个数据对应的协方差矩阵是多少?
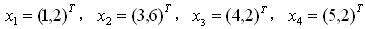
解答:
由于数据是二维的,所以协方差矩阵是一个2*2的矩阵,矩阵的每个元素为:
元素(i,j) = (第 i 维所有元素 - 第 i 维的均值) * (第 j 维所有元素 - 第 j 维的均值) 。
其中「*」代表向量内积符号,即两个向量求内积,对应元素相乘之后再累加。
我们首先列出第一维:
D1: (1,3,4,5) 均值:3.25
D2: (2,6,2,2) 均值:3
下面计算协方差矩阵第(1,2)个元素:
元素(1,2)=(1-3.25,3-3.25,4-3.25,5-3.25)*(2-3,6-3,2-3,2-3)=-1
类似的,我们可以把2*2个元素都计算出来:
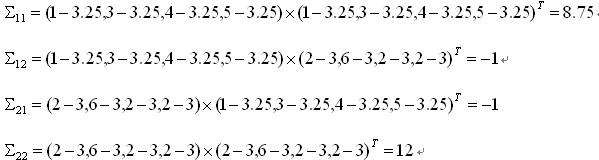
这个题目的最终结果就是:
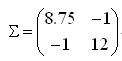
我们来分析一下上面的例子。首先看一下元素(1,1)的计算过程:
把所有数据的第一个维度拿出来,求出均值,之后的求解过程完全是我们熟悉的「方差」的求法。也就是说,这完完全全就是在求所有数据第一维元素(共4个)的方差(8.75)嘛。类似地,元素(2,2)求的是第二维(共4个)元素的方差(12)。
再来看元素(1,2),这分明就是我们高数里面学的求 x 和 y 的协方差,不再单独计算某一维度的分散程度,而是把两个维度的分散值结合起来,这里才真正体现了「协方差矩阵」中「协方差」的意味。从计算过程和计算结果都能看出,元素(2,1)与元素(1,2)是一样的。也就是说,所有协方差矩阵都是一个对称阵。
总结一下协方差矩阵的特点:
- 对角线元素(i,i)为数据第 i 维的方差。
- 非对角线元素(i,j)为第 i 维和第 j 维的协方差。
- 协方差矩阵是对称阵。
现在只需要了解这些就够了。
这些知识也是非常基础的,在各个算法中都有涉及,像偏方差权衡,RL中的方差问题和解决,还有协方差矩阵在二元高斯分布(在下面一片概率论中会讲述)中决定了它的形状,详细演示。
范数
什么是范数,听得那么术语..其实就是衡量一个向量大小的单位。在机器学习中,我们也经常使用被称为范数(norm) 的函数衡量矩阵大小
范数如下:
(为什么是这样的,不要管了,要扯就扯偏了,记得是衡量向量或者矩阵大小的就行了)
常见的:
范数
:为x向量各个元素绝对值之和;
范数
:为x向量各个元素平方和的开方,这个也就是两点直线距离嘛,回忆初高中的知识!
注意:当 p = 2 时, 范数被称为 欧几里得范数(Euclidean norm)。它表示从原点
出发到向量 x 确定的点的欧几里得距离。 范数在机器学习中出现地十分频繁
经常简化表示为 ∥x∥,略去了下标 2。平方 范数也经常用来衡量向量的大小,可以
简单地通过点积 计算。
这些知识在各大算法(如SVM)中亦有涉及,而且在距离量度中的欧式距离,华盛顿距离都有密切关系。
特殊类型的矩阵和向量
有些特殊类型的矩阵和向量是特别有用的,也相当于一些术语,比如一些文章直接说是XX矩阵或者XX向量,这个时候我们应该要明白这些矩阵或者向量是什么样子的,还有什么样的性质!
对角矩阵(diagonal matrix):只在主对角线上含有非零元素,其他位置都是零。形式上,矩阵 是对角矩阵,当且仅当对于所有的
特殊的:单位矩阵是对角元素全部是 1的对角矩阵。
单位向量:指模等于1(具有 单位范数)的向量。由于是非零向量,单位向量具有确定的方向。单位向量有无数个。
也就是说:对于单位向量,有 = 1.
对称矩阵:是转置和自己相等的矩阵:
当某些不依赖参数顺序的双参数函数生成元素时,对称矩阵经常会出现, 例如,如果A是一个距离度量矩阵, 表示点
到点
的距离,那么
,因为距离函数是对称的。
正交矩阵:是指行向量和列向量是分别标准正交的方阵:
这意味着
所以正交矩阵受到关注是因为求逆计算代价小。 我们需要注意正交矩阵的定义。 违反直觉的是,正交矩阵的行向量不仅是正交的,还是标准正交的。 对于行向量或列向量互相正交但不是标准正交的矩阵,没有对应的专有术语。
特征分解以及其意义
许多数学对象可以通过将它们分解成多个组成部分,或者找到它们的一些属性而更好地理解,这些属性是通用的,而不是由我们选择表示它们的方式引起的。
例如:整数可以分解为质数。 我们可以用十进制或二进制等不同方式表示整数12,但质因数分解永远是对的12=2×3×3。 从这个表示中我们可以获得一些有用的信息,比如12不能被5整除,或者12的倍数可以被3整除。
正如我们可以通过分解质因数来发现整数的一些内在性质,我们也可以通过分解矩阵来发现矩阵表示成数组元素时不明显的函数性质。
- 特征分解是使用最广的矩阵分解之一,即我们将矩阵分解成一组特征向量和特征值。
- 一个变换(或者说矩阵)的特征向量就是这样一种向量,它经过这种特定的变换后保持方向不变,只是进行长度上的伸缩而已。
特征向量的原始定义:
可以很容易看出, 是方阵
对向量
进行变换后的结果,显然
和
的方向相同。
是特征向量的话,
表示的就是特征值。
求解:令 A 是一个 N×N 的方阵,且有 N 个线性无关的特征向量
这样, A 可以被分解
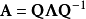
其中 Q 是N×N方阵,且其第 i列为 A 的特征向量 。 Λ 是对角矩阵,其对角线上的元素为对应的特征值,也即
这里需要注意只有可对角化矩阵才可以作特征分解。比如
![]()
不能被对角化,也就不能特征分解。
特征值及特征向量的几何意义和物理意义:
在空间中,对一个变换而言,特征向量指明的方向才是很重要的,特征值不那么重要。虽然我们求这两个量时先求出特征值,但特征向量才是更本质的东西!特征向量是指经过指定变换(与特定矩阵相乘)后不发生方向改变的那些向量,特征值是指在经过这些变换后特征向量的伸缩的倍数,也就是说矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。
物理的含义就是图像的运动:特征向量在一个矩阵的作用下作伸缩运动,伸缩的幅度由特征值确定。特征值大于1,所有属于此特征值的特征向量身形暴长;特征值大于0小于1,特征向量身形猛缩;特征值小于0,特征向量缩过了界,反方向到0点那边去了。
注意:常有教科书说特征向量是在矩阵变换下不改变方向的向量,实际上当特征值小于零时,矩阵就会把特征向量完全反方向改变,当然特征向量还是特征向量。我也赞同特征向量不改变方向的说法:特征向量永远不改变方向,改变的只是特征值(方向反转特征值为负值了)。特征向量也是线性不变量。
特征分解的重要应用--PCA(主成分分析):
举个栗子:机器学习中的分类问题,给出178个葡萄酒样本,每个样本含有13个参数,比如酒精度、酸度、镁含量等,这些样本属于3个不同种类的葡萄酒。任务是提取3种葡萄酒的特征,以便下一次给出一个新的葡萄酒样本的时候,能根据已有数据判断出新样本是哪一种葡萄酒。
原数据有13维,但这之中含有冗余,减少数据量最直接的方法就是降维。做法:把数据集赋给一个178行13列的矩阵R,减掉均值并归一化,它的协方差矩阵C是13行13列的矩阵,对C进行特征分解,对角化,其中U是特征向量组成的矩阵,D是特征值组成的对角矩阵,并按由大到小排列。然后,另R’ =RU,就实现了数据集在特征向量这组正交基上的投影。嗯,重点来了,R’中的数据列是按照对应特征值的大小排列的,后面的列对应小特征值,去掉以后对整个数据集的影响比较小。比如,现在我们直接去掉后面的7列,只保留前6列,就完成了降维。
这个降维方法就叫PCA(Principal Component Analysis)。降维以后分类错误率与不降维的方法相差无几,但需要处理的数据量减小了一半(不降维需要处理13维,降维后只需要处理6维)。在深度学习之前,图像处理是很常用到PCA的,PCA是一个非常不错的降维方法!
奇异值分解及其意义
奇异值分解就是将矩阵 A 分解成三个矩阵的乘积:
假设 A 是一个 m × n 的矩阵,那么 U 是一个 m × m 的矩阵,D 是一个 m × n的矩阵,V 是一个 n × n 矩阵。这些矩阵中的每一个经定义后都拥有特殊的结构。矩阵 U 和 V 都被定义为正交矩阵,而矩阵 D 被定义为对角矩阵。注意:矩阵 D 不一定是方阵。
求解比较复杂,详细推荐查看这篇奇异值分解
奇异值分解的意义:
奇异值分解的含义是,把一个矩阵A看成线性变换(当然也可以看成是数据矩阵或者样本矩阵),那么这个线性变换的作用效果是这样的,我们可以在原空间找到一组标准正交基V,同时可以在对应空间找到一组标准正交基U,我们知道,看一个矩阵的作用效果只要看它在一组基上的作用效果即可,在内积空间上,我们更希望看到它在一组标准正交基上的作用效果。而矩阵A在标准正交基V上的作用效果恰好可以表示为在U的对应方向上只进行纯粹的伸缩!这就大大简化了我们对矩阵作用的认识,因为我们知道,我们面前不管是多么复杂的矩阵,它在某组 标准正交基上的作用就是在另外一组标准正交基上进行伸缩而已。
更加详细的讲述请看:奇异值的意义
特征分解也是这样的,也可以简化我们对矩阵的认识。对于可对角化的矩阵,该线性变换的作用就是将某些方向(特征向量方向)在该方向上做伸缩。
有了上述认识,当我们要看该矩阵对任一向量x的作用效果的时候,在特征分解的视角下,我们可以把x往特征向量方向上分解,然后每个方向上做伸缩,最后再把结果加起来即可;在奇异值分解的视角下,我们可以把x往V方向上分解,然后将各个分量分别对应到U方向上做伸缩,最后把各个分量上的结果加起来即可。
奇异值分解和上面所讲的特征分解有很大的关系,而我的理解是:
- 不是所有的矩阵都能对角化(对称矩阵总是可以),而所有矩阵总是可以做奇异值分解的。那么多类型的矩阵,我们居然总是可以从一个统一且简单的视角去看它,我们就会感叹奇异值分解是多么奇妙了!
- 协方差矩阵(或
)的奇异值分解结果和特征值分解结果一致。所以在PCA中,SVD是一种实现方式
上面的知识可能需要其他的一些前置知识,但我认为也不必要非学,用的不多,可以遇到再学吧,我们知道其主要公式,意义和应用就好,重要性也一目了然,对于矩阵的变换运算,比如降维(PCA)或推荐系统中都有其重要的作用。
Moore-Penrose 伪逆
对于非方矩阵而言,其逆矩阵没有定义。假设在下面问题中,我们想通过矩阵A的左逆B来求解线性方程:
等式两边同时左乘左逆B后,得到:
是否存在唯一的映射将A映射到B取决于问题的形式。
如果矩阵A的行数大于列数,那么上述方程可能没有解;如果矩阵A的行数小于列数,那么上述方程可能有多个解。
Moore-Penrose伪逆使我们能够解决这种情况,矩阵A的伪逆定义为:
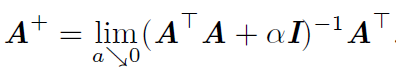
但是计算伪逆的实际算法没有基于这个式子,而是使用下面的公式:

其中,矩阵U,D 和V 是矩阵A奇异值分解后得到的矩阵。对角矩阵D 的伪逆D+ 是其非零元素取倒之后再转置得到的。
注意,这里的伪逆也是应用奇异值分解来求得的,这就很好体现知识是联系的啦,伪逆的应用在机器学习中也是大量存在的,比如最简单的线性回归中求广义逆矩阵,也就是伪逆。
迹运算
迹运算返回的是矩阵对角元素的和:
迹运算因为很多原因而有用。 若不使用求和符号,有些矩阵运算很难描述,而通过矩阵乘法和迹运算符号可以清楚地表示。 例如,迹运算提供了另一种描述矩阵Frobenius 范数的方式:
(不必知道是什么,只要知道有这样的运算就好,如果有兴趣,当然可以去了解)
用迹运算表示表达式,我们可以使用很多有用的等式巧妙地处理表达式。 例如,迹运算在转置运算下是不变的:
多个矩阵相乘得到的方阵的迹,和将这些矩阵中的最后一个挪到最前面之后相乘的迹是相同的。 当然,我们需要考虑挪动之后矩阵乘积依然定义良好:Tr(ABC) = Tr(CAB) = Tr(BCA).
迹运算也是常用的数学知识,比如这些知识在正规方程组计算中就有着重要的作用。