首先先建立数据库和插入数据
我们要查询的命令如下,前提是以mysql数据库为准
select * from test where a=? and b>? order by c limit 0,100
结果和我想的不太一样,先准备好环境和所需的数据库和表
准备阶段
CREATE TABLE `test` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
准备插入数据
DROP PROCEDURE IF EXISTS test_initData; DELIMITER $ CREATE PROCEDURE test_initData() BEGIN DECLARE i INT DEFAULT 1; WHILE i<=100000 DO INSERT INTO test(id,a,b,c) VALUES(i,i*2,i*3,i*4); SET i = i+1; END WHILE; END $ CALL test_initData();
由于mysql有最左前缀规则,对abc进行排列,创建6个索引,涵盖了全部查询的情况(就是全部查询abc)
create INDEX idx_a_b_c on test(a,b,c); create INDEX idx_a_c_b on test(a,c,b); create INDEX idx_b_a_c on test(b,a,c); create INDEX idx_b_c_a on test(b,c,a); create INDEX idx_c_a_b on test(c,a,b); create INDEX idx_c_b_a on test(c,b,a);
使用EXplain验证
1、自动选用索引
explain select * from test where a>10 and b >10 order by c
首先,我们拿上面的sql语句进行验证。结果发现,查询使用了索引idx_a_b_c,只用到了前缀a,b。而extra部分,则用到了filesort,也就是性能非常差的方式。
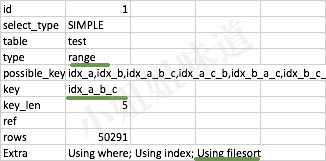
可有换一下查询参数的位置
explain select * from test where c>10 and b >10 order by a

可以看到这次自动选择了idx_b_a_c,但依然使用的filesort,查询效果是一样的。按照上面的逻辑,不是应该选择idx_b_c_a么?
2、指定索引
我们采用使用force index方式,强制指定索引。 这里直接给出结果,就是下面的sql。
explain select * from test FORCE INDEX(idx_c_b_a) where a>10 and b >10 order by c
结果为:
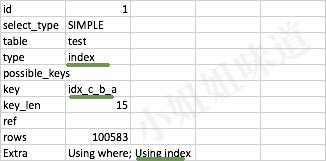
但是,这与我们的经验是相悖的。idx_c_b_a的索引,是在字段(c,b,a)上创建的。按照最左原则,支持的搜索条件有:c,cb,cba。在这个例子中,order by后面的参数,却被当作了前缀的头部信息。
我们删掉其他索引,只留下idx_c_b_a,然后去掉force index部分。结果发现,mysql现在能够自动的选择索引了。
explain select * from test FORCE INDEX(idx_b_c_a) where a>10 order by b,c
结果:

使用idx_b_c_a,不走filesort,其他索引都不是最优。
3、explain部分返回值意义
可以得出上面的结论,是根据mysql自己提供的explain工具,这个工具可以输出一些有用的信息,下边是部分返回值的意义。


select_type
表示SELECT的类型,常见的取值有:
SIMPLE 简单表,不使用表连接或子查询。
PRIMARY 主查询,即外层的查询。
UNION UNION中的第二个或者后面的查询语句。
SUBQUERY 子查询中的第一个。
type
表示MySQL在表中找到所需行的方式,或者叫访问类型。常见访问类型如下,从下到上,性能越来越差。
system,const 表只有一行记录(等于系统表),这是const类型的特列。
eq_ref 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。
ref 非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
range 只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引。这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
index Full Index Scan,Index与All区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。
all 全表扫描,性能最差
Extra
using index
表示相应的select操作中使用了覆盖索引,避免访问了表的数据行,效率不错。如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。
using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序”。
using temporary
使用了用临时表保存中间结果,mysql在对查询结果排序时使用临时表。常见于排序order by和分组查询group by。
最后
可以看到,在我们创建了多个索引的时候,mysql的查询优化,并不一定能够进行智能的解析、用到最优的方式,需要使用force index指定索引。
mysql中的索引,主要就用在where条件中和排序动作中。分两种情况。
1、先过滤,再排序,会用到过滤条件中的索引参数,但是排序会使用较慢的外部排序。因为这个结果集是经过过滤的,并没有什么索引参与。
2、先排序,再过滤,可以使用同一个索引,排序的优先级高于过滤的优先级。选择合适的索引,在过滤的同时就把这个事给办了。但是扫描的行数会增加。
我想,mysql并不能够了解到这两个过程,到底谁快谁慢,于是选了一个最通用的方式,直接选用了第一种。甚至在索引非常多的时候,直接晕菜了。**索引建多了,你可能间接把mysql给害了。**这是现象,至于深层次的原因,欢迎读过mysql相关源码的给解释一下。
这对经常变换字段进行排序的代码来说,并不是一个好的信号。考虑到程序的稳定性,我想应该要尽量减少where条件过滤后的结果集。这种情况下,创建一个(a,b)的联合索引,或许是一个折衷的方式。
以上内容转载于 https://juejin.im/post/5d6881d4f265da03ab426341