--SQL2005静态写法
--创建测试数据
create table Test(月份 varchar(4), 工资 int, 福利 int, 奖金 int)
insert Test
select '1月',100,200,300 union all
select '2月',110,210,310 union all
select '3月',120,220,320 union all
select '4月',130,230,330
go
SELECT * FROM
(
SELECT 考核月份,月份,金额 FROM
(SELECT 月份, 工资, 福利, 奖金 FROM Test) p
UNPIVOT
(金额 FOR 考核月份 IN (工资, 福利, 奖金))AS unpvt
) T
PIVOT
(MAX(金额) FOR 月份 in ([1月],[2月],[3月],[4月]))AS pt
drop table test
/*
项目 1月 2月 3月 4月
-------- ------ -------- -------- --------
奖金 300 310 320 330
工资 100 110 120 130
福利 200 210 220 230
(3 行受影响)
*/
-----------------------------------------下面为语法解释----------------------------------------------------------------------------
在输出统计结果时可能需要将列变成行,而将聚合结果(如count、sum)作为记录的第一行,先看如下的SQL语句:

insert @t
select 'abc' union all
select 'xxx' union all
select 'xxx' union all
select 'ttt'
select * from @t
在执行上面的SQL语句后,会输出如图1所示的记录集。

上图显示的是一个普通的记录集,如果要统计name字段的每个值的重复数,需要进行分组,如下面的SQL如示:
执行上面的SQL语句后的查询结果如图2所示。

如果我们有一个需求,需要如图3所示的聚合结果。
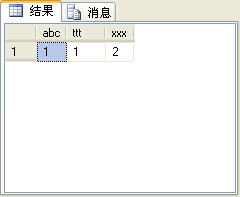
从图3可以看出,查询结果正好是图2的结果逆时针旋转90度,也就是说,name列的值变成了列名,而c列的值变成了第一行的记录。图2所示的c和name字段消失了。
当然,要达到这个结果并不困难,看如下的SQL语句:
(select count(name) from @t where name='ttt') as xxx,
(select count(name) from @t where name='xxx') as ttt
上面的SQL语句会出输出如图3的查询结果。但这里有个问题,上面的SQL语句是枚举了name列所有可能的值,在本例中只有三个值('abc','ttt','xxx'),这非常好枚举,但如果有很多值,SQL语句会变得非常长,非常不利于编写。当然,可以通过编程的方式自动生成,但最终结果仍然会生成很长的SQL语句。
为了解决这个问题,在SQL Server2005中提供了一个pivot函数,该函数可以很容易地输出如图3所示的记录集,如下面的SQL语句所示:
在执行上面的SQL语句同样可以获得图3所示的查询结果。实际上,pivot函数也起到了分组的作用。在使用pivot函数时应注意如下几点:
1. pivot函数需要指定聚合函数,如count、sum等,for关键字和聚合函数都要使用需要聚合的字段名,在本例中是name。
2. in关键字负责指定每组需要聚合的值,用[...]将这些值括起来。实际上,这些值也相当于我们第一种聚合方法中的where条件,例如,where name='abc'、where name='ttt',当然,这些值也是输出记录集的列名。
3. 在最后要为pivot函数起一个别名。
虽然当要聚合的值很多时(或不确定),也需要动态生成SQL语句,但使用pivot函数的SQL语句却短很多。
如果我们还有一个需求,要将图3的结果变成图2的结果,也就是顺时针旋转90度,仍然以c和name作为字段名。也许方法很多,但SQL
Server2005提供了一个unpivot函数,该函数是pivot函数的逆过程。也就是将记录集顺时针旋转90度,先看下面的SQL语句:
insert @t
select 'abc' union all
select 'xxx' union all
select 'xxx' union all
select 'ttt'
;
with tt as(
select * from @t pivot(count(name) for name in([abc] ,[ttt],[xxx])) p)
select * from tt
上面的SQL语句将输出如图3所示的结果。如果将最后一条SQL语句(select * from tt)换成如下的SQL语句,将输出如图2所示的结果。
要注意的是,[c]中的c表示聚合结果列的字段名,name表示要聚合列的字段名,这两个值可以是任意满足字段名命名规则的字符串, [abc] ,[xxx],[ttt]分别是图3所示的记录集的字段名,这些值必须一致。执行下面的SQL语句将获得图4的输出结果。
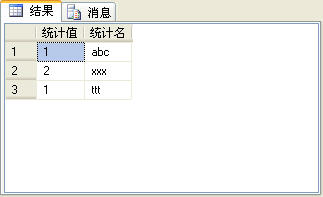
图4