Spark streaming 和kafka 处理确保消息不丢失的总结
接入kafka
我们前面的1到4 都在说 spark streaming 接入 kafka 消息的事情。讲了两种接入方式,以及spark streaming 如何和kafka协作接收数据,处理数据生成rdd的
主要有如下两种方式
基于分布式receiver
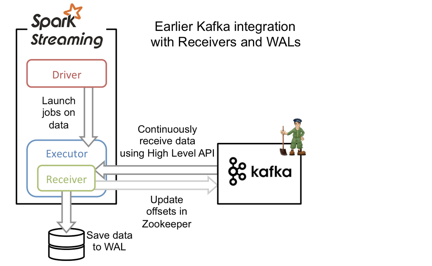
基于receiver的方法采用Kafka的高级消费者API,每个executor进程都不断拉取消息,并同时保存在executor内存与HDFS上的预写日志(write-ahead log/WAL)。当消息写入WAL后,自动更新ZooKeeper中的offset。
它可以保证at least once语义,但无法保证exactly once语义。原因是虽然引入了WAL来确保消息不会丢失,但有可能会出现消息已写入WAL,但更新comsuer 的offset到zk时失败的情况,此时consumer就会按上一次的offset重新发送消息到kafka重新获取一次已保存到WAL的数据。这种方式还会造成数据冗余(WAL中一份,blockmanager中一份,其中blockmanager可能会做StorageLevel.MEMORY_AND_DISK_SER_2,即内存中一份,磁盘上两份),大大降低了吞吐量和内存磁盘的利用率。现在基本都使用下面基于direct stream的方法了。
基于direct stream的方法
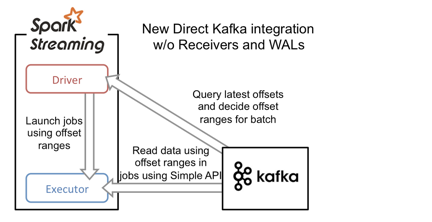
基于direct stream的方法采用Kafka的简单消费者API,大大简化了获取message 的流程。executor不再从Kafka中连续读取消息,也消除了receiver和WAL。还有一个改进就是Kafka分区与RDD分区是一一对应的,允许用户控制topic-partition 的offset,程序变得更加可控。
driver进程只需要每次从Kafka获得批次消息的offset range,然后executor进程根据offset range去读取该批次对应的消息即可。由于offset在Kafka中能唯一确定一条消息,且在外部只能被Streaming程序本身感知到,因此消除了不一致性,保证了exactly once语义。不过,由于它采用了简单消费者API,我们就需要自己来管理offset。否则一旦程序崩溃,整个流只能从earliest或者latest点恢复,这肯定是不稳妥的。
如何保证处理结果不丢失呢?
主要有两种方案:
2.1. 主要是 通过设计幂等性操作,在 at least once 的语义之上,确保数据不丢失
2.2. 在一些shuffle或者是集合计算的结果集中, 在 exactly-once 的基础上,同时更新 处理结果和 offset,这种情况下,一般都是使用事务来做。
现有的支持事务的,也就是传统的数据库了,对于一些缓存系统为了更简单更高效的访问,即使有事务机制,也设计的非常简单,或是只实现了部分功能,例如 redis 的事务是不能支持回滚的。需要我们在代码中做相应的设计,来确保事务的正确执行。
分布式 RDD 计算过程如何确保准确性和一致性?
即分布式RDD计算是如何和确保计算恰好计算一次的呢?后续会出一系列源码分析,分析 spark 是如何做分布式计算的。