对SerializerManager的说明:
它是为各种Spark组件配置序列化,压缩和加密的组件,包括自动选择用于shuffle的Serializer。spark中的数据在network IO 或 local disk IO传输过程中。都需要序列化。其默认的 Serializer 是 org.apache.spark.serializer.JavaSerializer,在一定条件下,可以使用kryo,即org.apache.spark.serializer.KryoSerializer。
支持的两种序列化方式
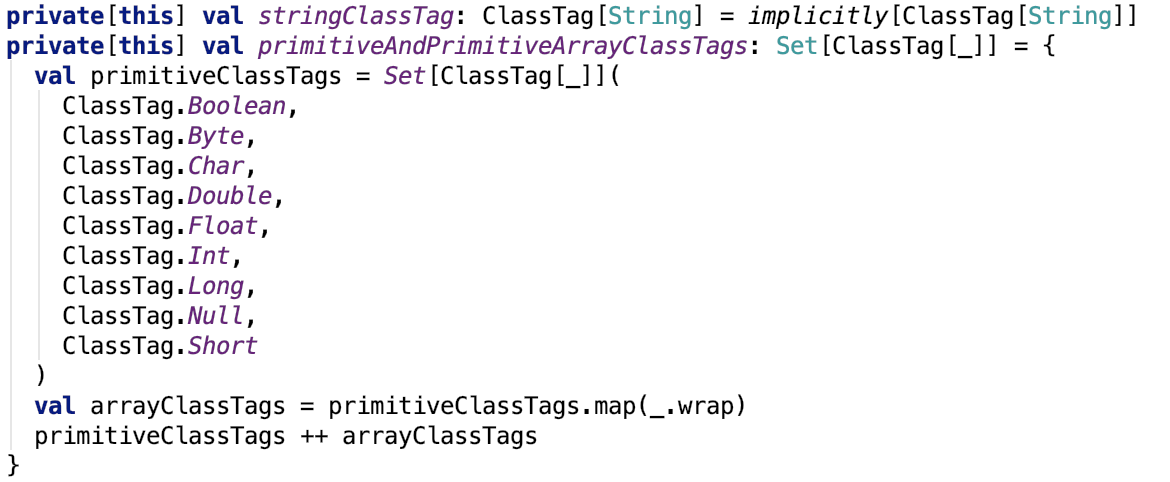
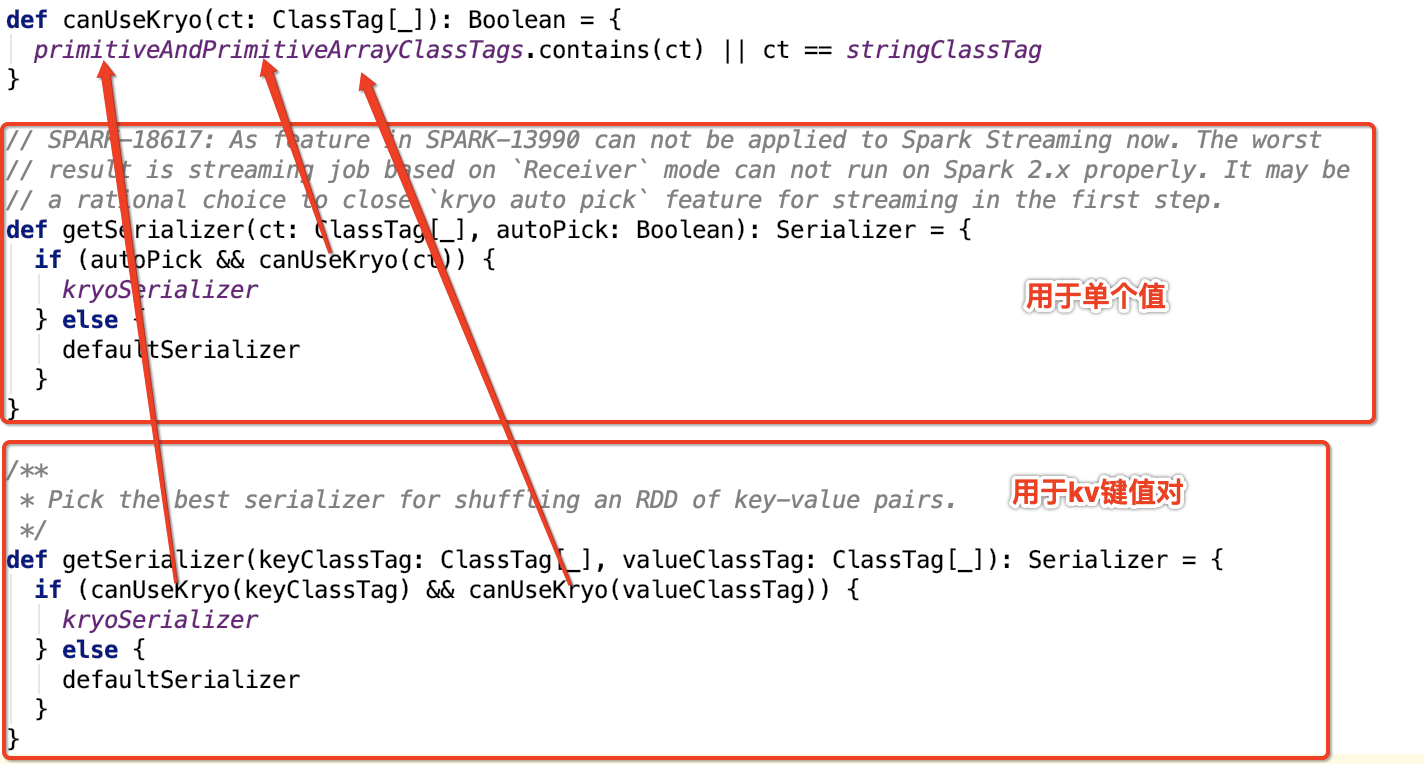
即值的类型是八种基本类型中一种或null或String,都会使用kryo,否则使用默认序列化方式,即java序列化方式。
它还负责读写Block流是否使用压缩:

数据流是否支持压缩
默认情况下:


其中,如果使用压缩,默认的压缩是 lz4, 可以通过参数 spark.io.compression.codec 来配置。它支持的所有压缩类型如下:

读写数据流如何支持压缩
其中,支持压缩的InputStream和OutputStream是对原来的InputStream和OutputStream做了包装。我们以LZ4BlockOutputStream为例说明。
调用如下函数返回支持压缩的OutputStream:

首先,LZ4BlockOutputStream的继承关系如下:
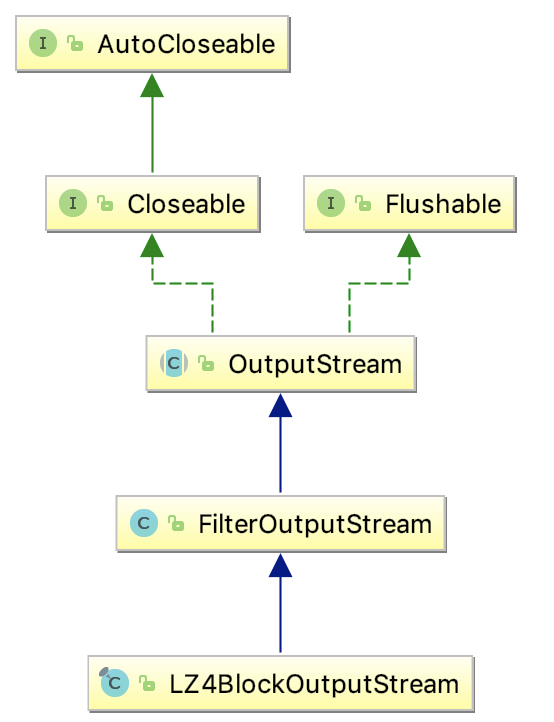
被包装的类被放到了FilterOutputStream类的out 字段中,如下:
![]()
outputStream核心方法就是write。直接来看LZ4BlockOutputStream的write方法:
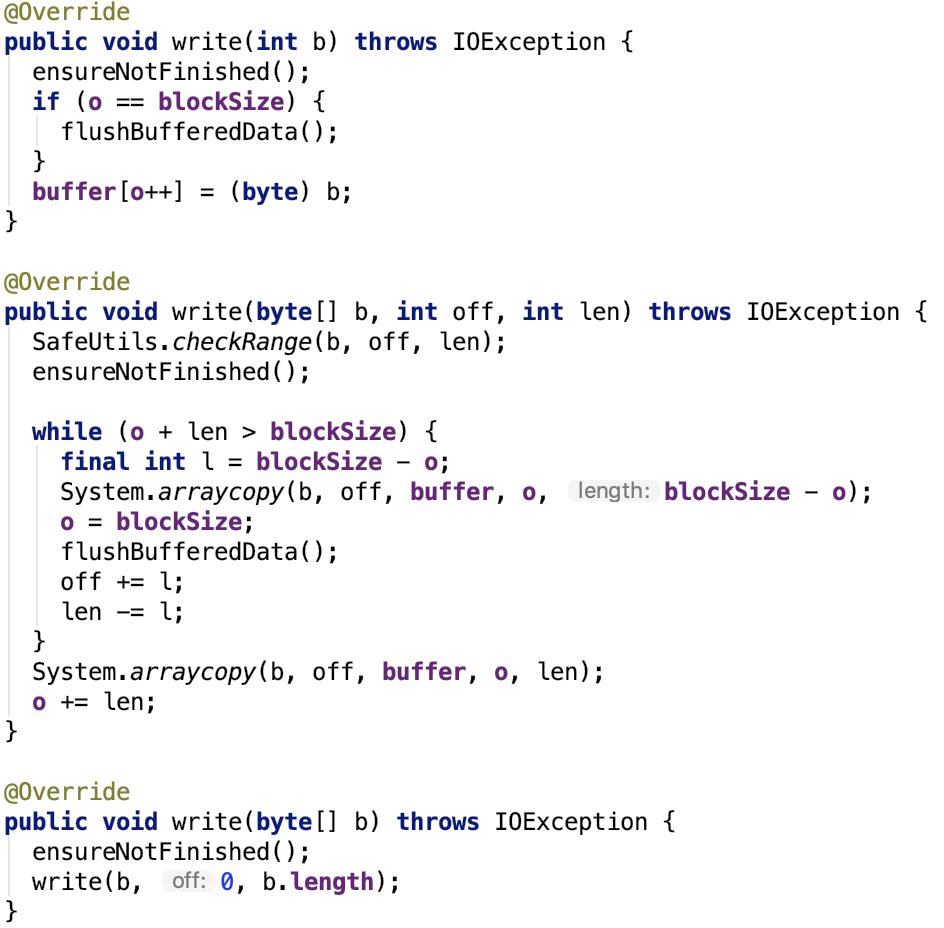
其中buffer是一个byte 数组,默认是 32k,可以通过spark.io.compression.lz4.blockSize 参数来指定,在LZ4BlockOutputStream类中用blockSize保存。
重点看flushBufferedData方法:
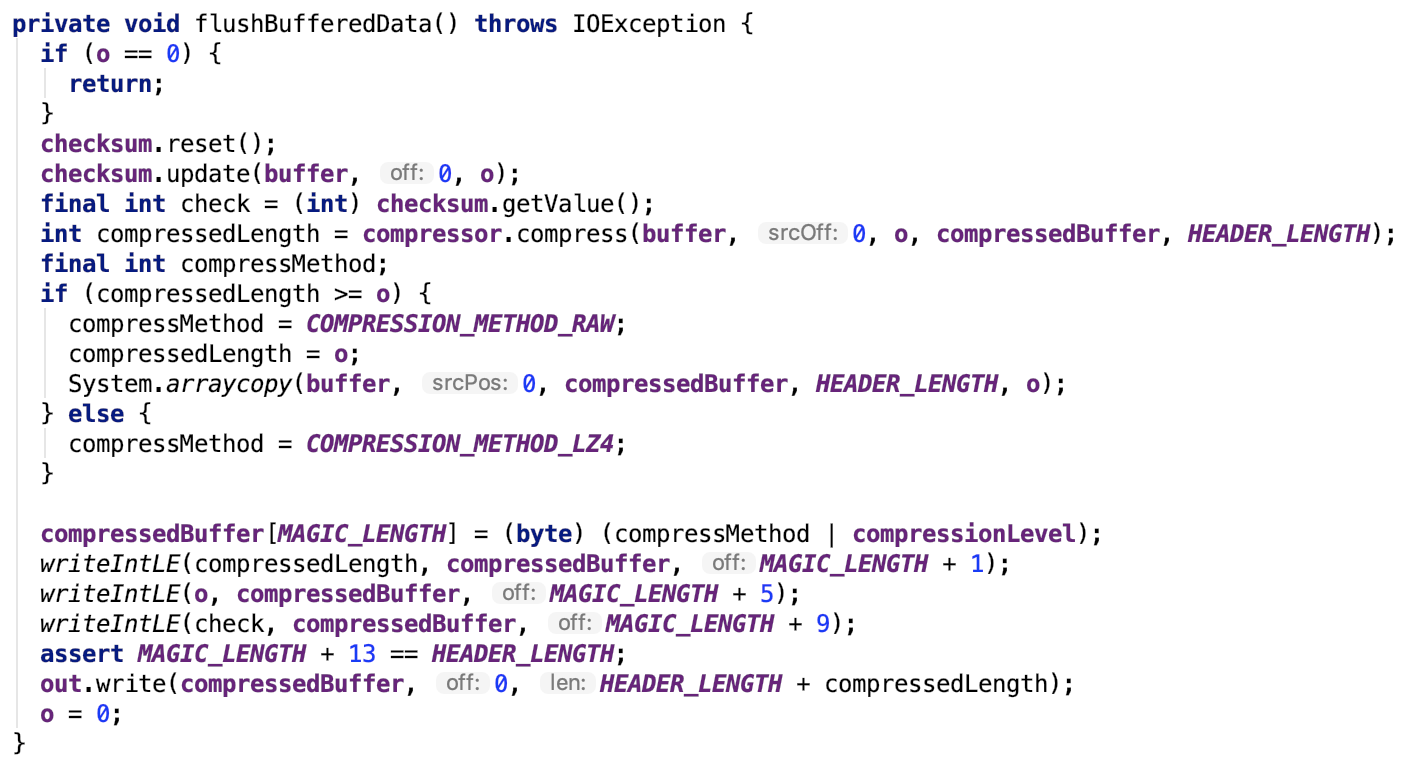
方法内部实现思路如下:
外部写入到buffer中的数据经过compressor压缩到compressorBuffer中,然后再写入一些magic,最终将压缩的buffer写入到out中,write操作结束。
可见,数据的压缩是由 LZ4BlockOutputStream 负责的,压缩之后的数据被写入到目标outputStream中。