引言
在上两篇文章 spark 源码分析之十九 -- DAG的生成和Stage的划分 和 spark 源码分析之二十 -- Stage的提交 中剖析了Spark的DAG的生成,Stage的划分以及Stage转换为TaskSet后的提交。
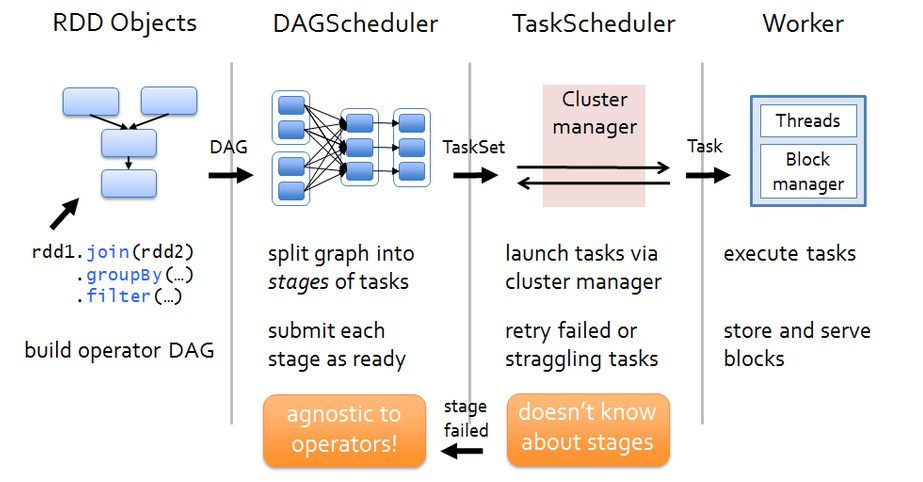
如下图,我们在前两篇文章中剖析了DAG的构建,Stage的划分以及Stage转换为TaskSet后的提交,本篇文章主要剖析TaskSet被TaskScheduler提交之后的Task的整个执行流程,关于具体Task是如何执行的两种stage对应的Task的执行有本质的区别,我们将在下一篇文章剖析。
我们先来剖析一下SchdulerBackend的子类实现。在yarn 模式下,它有两个实现yarn-client 模式下的 org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend实现 和 yarn-cluster 模式下的 org.apache.spark.scheduler.cluster.YarnClusterSchedulerBackend 实现,如下图。
这两个类在spark 项目的 resource-managers 目录下的 yarn 目录下定义实现。

下面简单看一下这几个类的定义和实现。
ExecutorAllocationClient
简单说明一下,这个类主要是负责想Cluster Master请求或杀掉executor。核心方法如下,不做过多解释,可以看源码做进一步了解。

SchedulerBackend
接口定义
A backend interface for scheduling systems that allows plugging in different ones under TaskSchedulerImpl. We assume a Mesos-like model where the application gets resource offers as machines become available and can launch tasks on them.
主要方法
其定义的方法如下:

killTask:请求 executor 杀掉正在运行的task
applicationId:获取job的applicationId
applicationAttemptId:获取task的 attemptId
getDriverLogUrls:获取驱动程序日志的URL。这些URL用于显示驱动程序的UI Executors选项卡中的链接。
maxNumConcurrentTasks:当前task的最大并发数
下面我们来看一下它的子类。
CoarseGrainedSchedulerBackend
类声明
A scheduler backend that waits for coarse-grained executors to connect. This backend holds onto each executor for the duration of the Spark job rather than relinquishing executors whenever a task is done and asking the scheduler to launch a new executor for each new task. Executors may be launched in a variety of ways, such as Mesos tasks for the coarse-grained Mesos mode or standalone processes for Spark's standalone deploy mode (spark.deploy.*).
调度程序后端,等待粗粒度执行程序进行连接。 此后端在Spark作业期间保留每个执行程序,而不是在任务完成时放弃执行程序并要求调度程序为每个新任务启动新的执行程序。 执行程序可以以多种方式启动,例如用于粗粒度Mesos模式的Mesos任务或用于Spark的独立部署模式(spark.deploy。*)的独立进程。
内部类DriverEndpoint
类说明
它是线程安全的。代表的是Driver的endpoint
类结构
如下,是它的类结构:
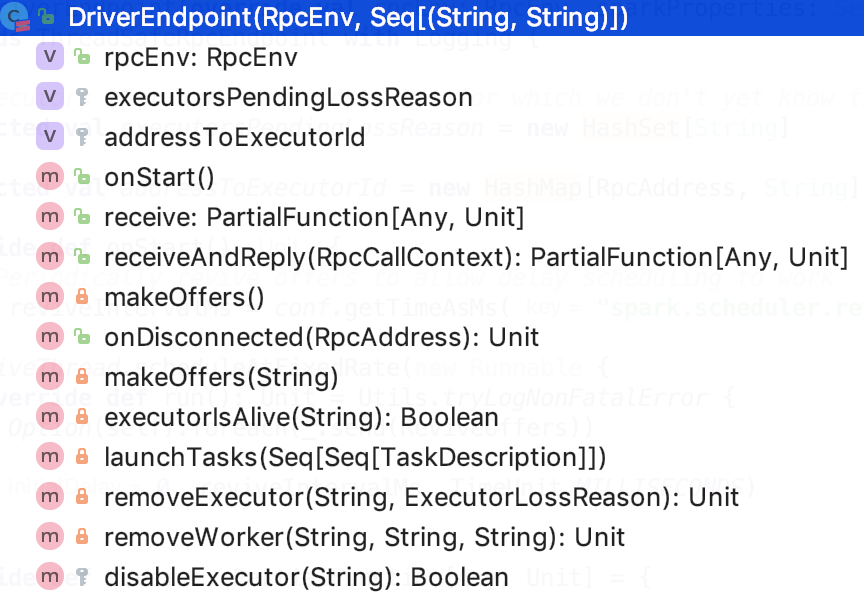
rpcEnv 是指的每个节点上的NettyRpcEnv
executorsPendingLossReason:记录了已经丢失的并且不知道原因的executor
addressToExecutorId:记录了每一个executor的id和executor地址的映射关系
下面我们看一下Task以及其继承关系。
Task
类说明
它是Task的基本单元。
类结构
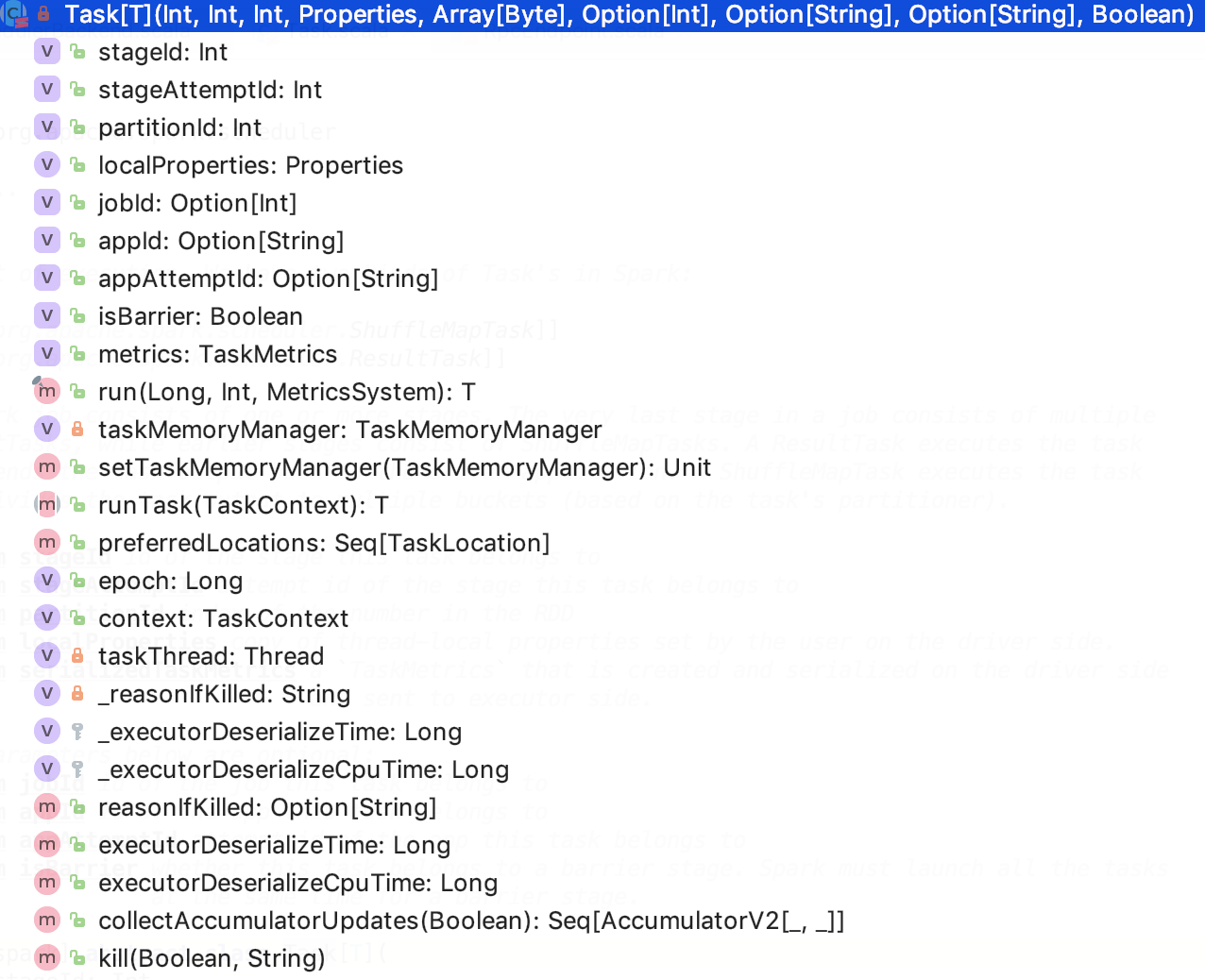
run:运行Task,被executor调用,源码如下:

runTask 运行Task,被run方法调用,它是一个抽象方法,由子类来实现。
kill:杀死Task。源码如下:

下面看一下其继承关系。
继承关系
Task的继承关系如下:
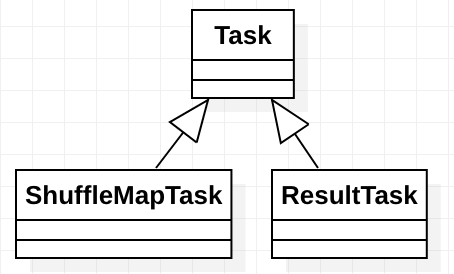
A unit of execution. We have two kinds of Task's in Spark:
- org.apache.spark.scheduler.ShuffleMapTask
- org.apache.spark.scheduler.ResultTask
A Spark job consists of one or more stages.
The very last stage in a job consists of multiple ResultTasks, while earlier stages consist of ShuffleMapTasks. A ResultTask executes the task and sends the task output back to the driver application. A ShuffleMapTask executes the task and divides the task output to multiple buckets (based on the task's partitioner).
下面分别看一下两个Task的实现,是如何定义 runTask 方法的?
ResultTask
类名:org.apache.spark.scheduler.ResultTask
其runTask方法如下:

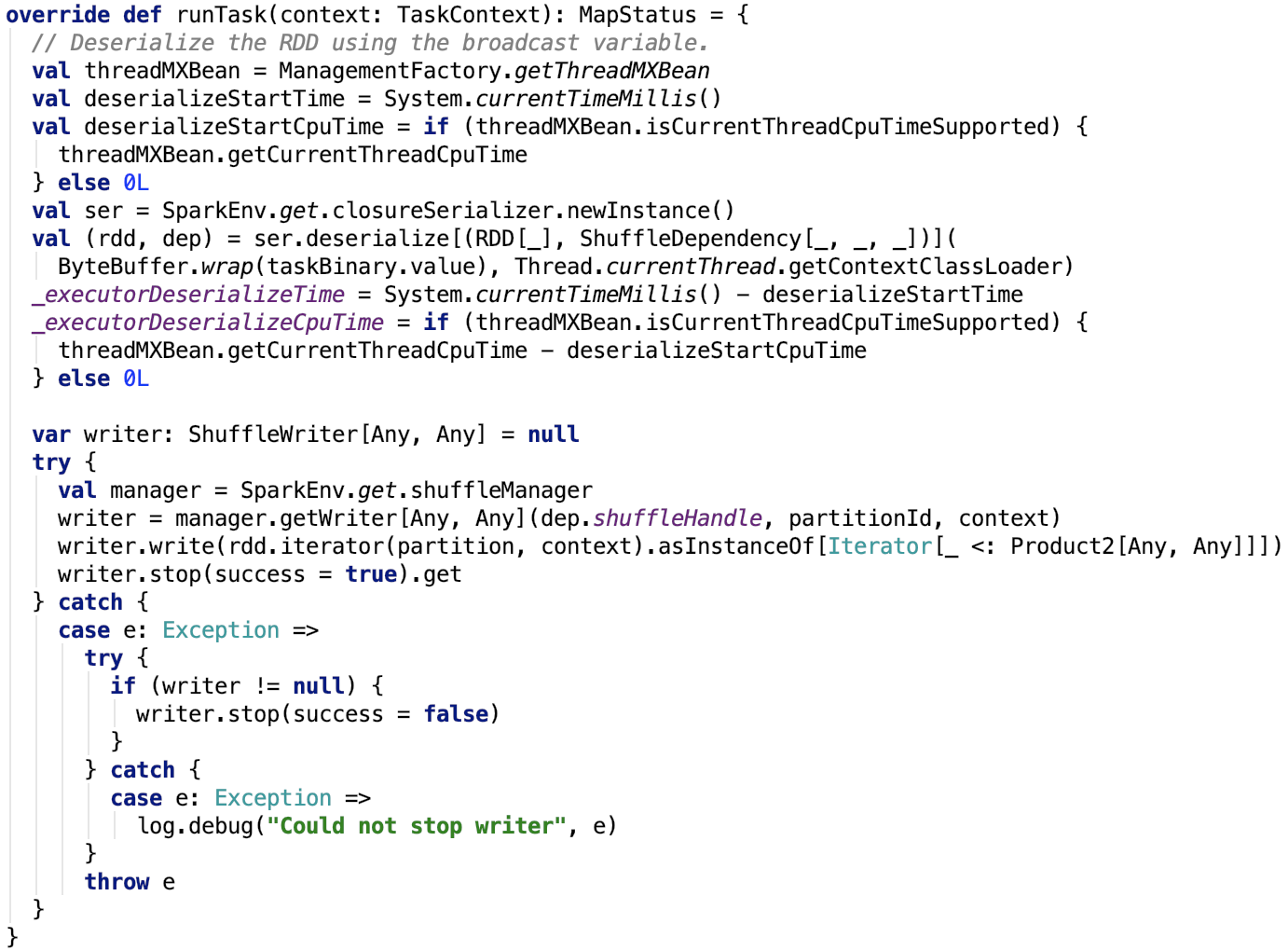
ShuffleMapTask
类名:org.apache.spark.scheduler.ShuffleMapTask
其runTask方法如下:
Executor
全称:org.apache.spark.executor.Executor
类说明
Executor对象是Spark Executor的抽象,它背后有一个线程池用来执行任务。其实从源码可以看出,Spark的Executor这个术语,其实来自于Java线程池部分的Executors。
下面主要分析一下其内部的结构。
执行Task的线程池
线程池定义如下:

心跳机制
Executor会不断地向driver发送心跳来汇报其健康状况,如下:
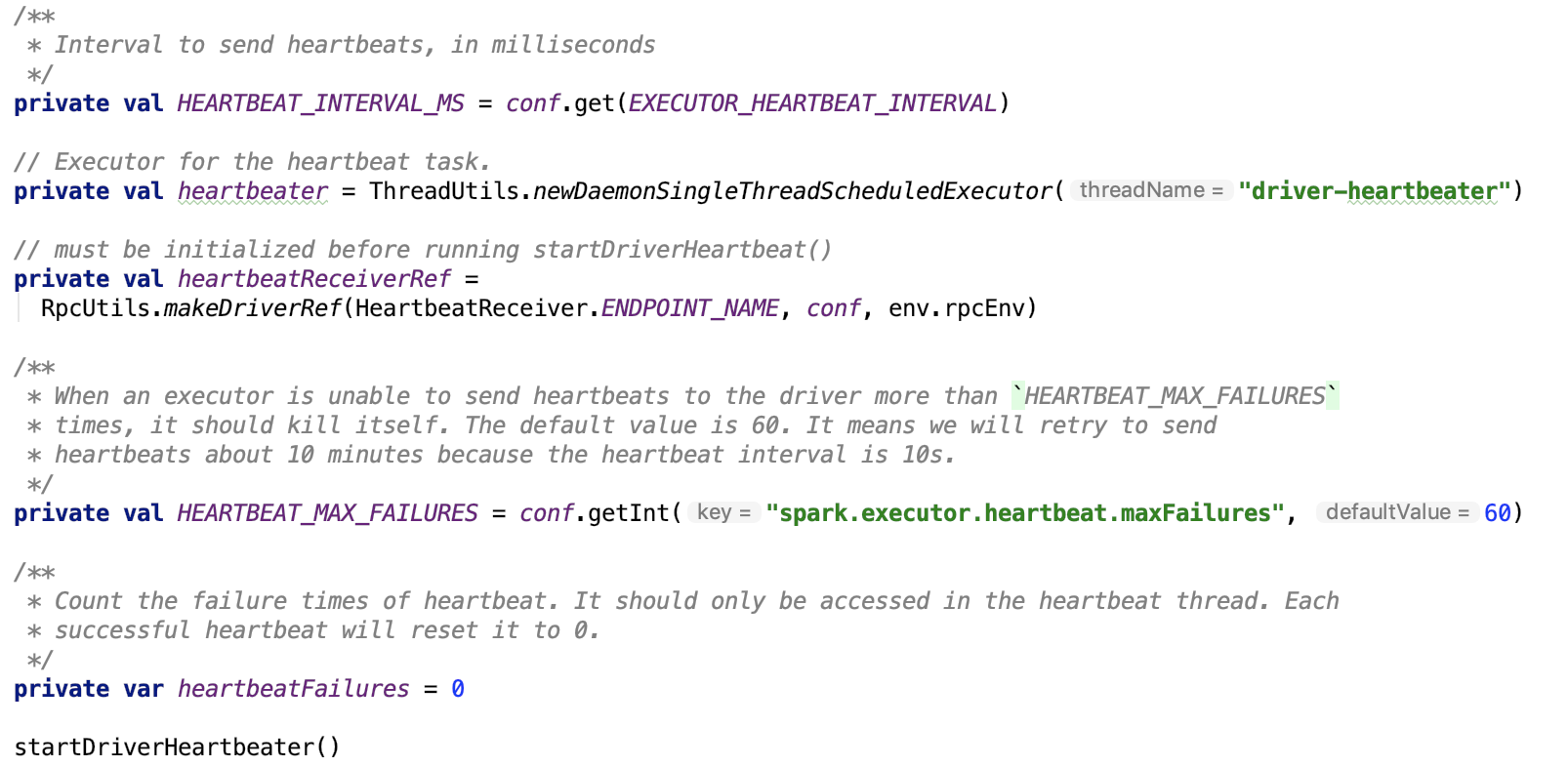
EXECUTOR_HEARTBEAT_INTERVAL 值默认为 10s, 可以通过参数 spark.executor.heartbeatInterval 来进行调整。
startDriverHeartBeater方法如下:

其依赖方法 reportHeartBeat 方法源码如下:

杀死任务机制--reaper机制
首先先来了解一下 TaskReaper。
TaskReaper
类说明:
Supervises the killing / cancellation of a task by sending the interrupted flag, optionally sending a Thread.interrupt(), and monitoring the task until it finishes. Spark's current task cancellation / task killing mechanism is "best effort" because some tasks may not be interruptable or may not respond to their "killed" flags being set. If a significant fraction of a cluster's task slots are occupied by tasks that have been marked as killed but remain running then this can lead to a situation where new jobs and tasks are starved of resources that are being used by these zombie tasks. The TaskReaper was introduced in SPARK-18761 as a mechanism to monitor and clean up zombie tasks. For backwards-compatibility / backportability this component is disabled by default and must be explicitly enabled by setting spark.task.reaper.enabled=true. A TaskReaper is created for a particular task when that task is killed / cancelled. Typically a task will have only one TaskReaper, but it's possible for a task to have up to two reapers in case kill is called twice with different values for the interrupt parameter. Once created, a TaskReaper will run until its supervised task has finished running. If the TaskReaper has not been configured to kill the JVM after a timeout (i.e. if spark.task.reaper.killTimeout < 0) then this implies that the TaskReaper may run indefinitely if the supervised task never exits.
其源码如下:

思路:发送kill信号,等待一定时间后,如果任务停止,则返回,否则yarn模式下抛出一场,对local模式没有影响。
是否启用reaper机制
reaper机制默认是不启用的,可以通过参数 spark.task.reaper.enabled 来启用。
taskReapter线程池
![]()
它也是一个daemon的支持多个worker同时工作的线程池,也就是说可以同时停止多个任务。
kill任务
当kill任务的时候,会调用kill Task方法,源码如下:

driver端SchedulerBackend接受task请求
在上一篇文章spark 源码分析之二十 -- Stage的提交中,提到SchedulerBackend接收到task请求后调用了 makeOffsers 方法,如下:

先调用TaskScheduler分配资源,并返回TaskDescription对象,然后拿着该对象去执行任务。
分配资源
过滤掉即将被回收的executor
executorDataMap的定义如下:

其中ExecutorData 是记录着executor的信息。包括 executor的address,port,可用cpu核数,总cpu核数等信息。
executorIsAlive方法定义如下:

即该executor既不在即将被回收的集合中也不在丢失的executor集合中。
构造WorkOffer集合
WorkOffer对象代表着一个executor上的可用资源,类定义如下:

分配资源
org.apache.spark.scheduler.TaskSchedulerImpl#resourceOffers 方法如下:

思路:先过滤掉不可用的WorkOffser对象,然后给每一个TaskSet分配资源。如果taskSet是barrier的,需要初始化barrierCoordinator的rpc endpoint。
记录映射关系
记录hostname和executorId的映射关系,记录executorId和taskId的映射关系,源码如下:
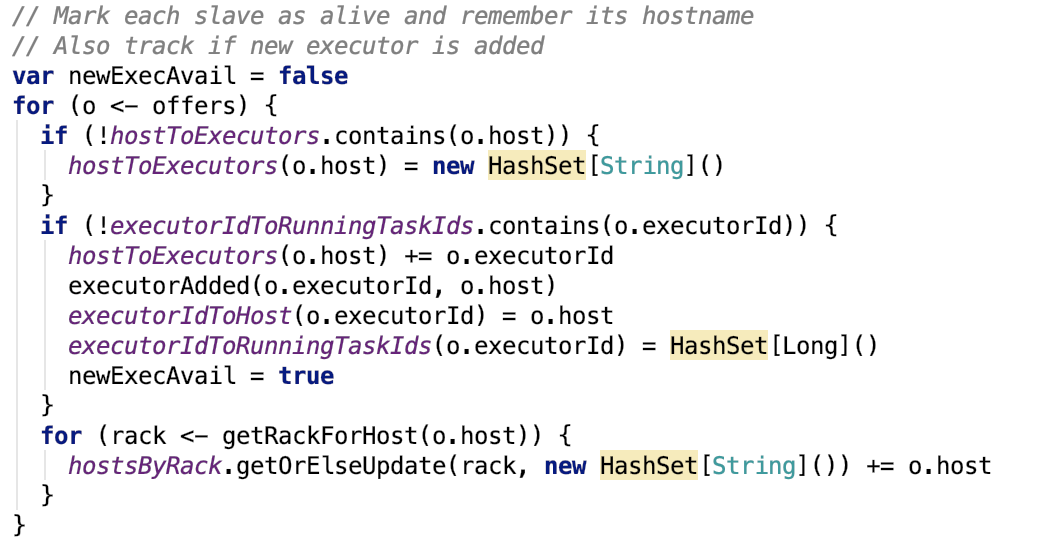
1. 其中 executorAdded的源码如下:

org.apache.spark.scheduler.DAGScheduler#executorAdded的映射关系如下:

经过eventProcessLoop异步消息队列后,最终被如下分支处理:
![]()
最终处理逻辑如下,即把状态健康的executor从失败的epoch集合中移除。

2. 其中,获取host的rack信息的方法没有实现,返回None。

更新不可用executor集合

blacklistTrackerOpt 定义如下:


org.apache.spark.scheduler.BlacklistTracker#isBlacklistEnabled 方法如下:
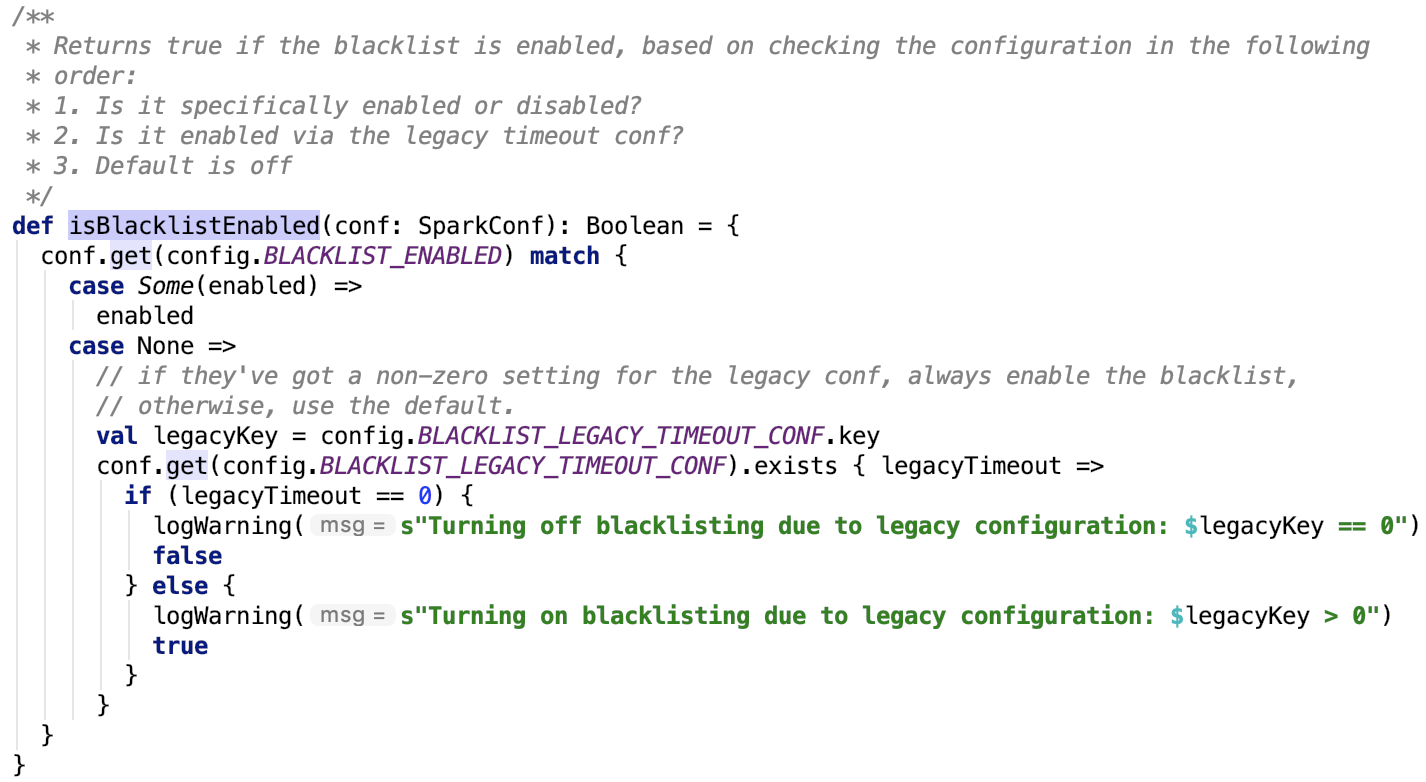
即 BLACKLIST_ENABLED 可以通过设置参数 spark.blacklist.enabled 来设定是否使用blacklist,默认没有设置。如果设定了spark.scheduler.executorTaskBlacklistTime参数值大于 0 ,也启用 blacklist。
BlacklistTracker 主要就是用来追踪有问题的executor和host信息的,其类说明如下:
BlacklistTracker is designed to track problematic executors and nodes. It supports blacklisting executors and nodes across an entire application (with a periodic expiry). TaskSetManagers add additional blacklisting of executors and nodes for individual tasks and stages which works in concert with the blacklisting here. The tracker needs to deal with a variety of workloads, eg.:
bad user code -- this may lead to many task failures, but that should not count against individual executors
many small stages -- this may prevent a bad executor for having many failures within one stage, but still many failures over the entire application
"flaky" executors -- they don't fail every task, but are still faulty enough to merit blacklisting See the design doc on SPARK-8425 for a more in-depth discussion.
过滤不可用WorkOffer
过滤掉host或executor在黑名单中的WorkOffer,对应源码如下:

对TaskSetManager排序
对应源码如下:

首先对WorkOffer集合随机打乱顺序,然后获取其可用core,可用slot的信息,然后获取排序后的TaskSetManager队列。rootPool是Pool对象,源码在 TaskScheduler提交TaskSet 中有描述,不再赘述。
CPUS_PER_TASK的核数默认是1,即一个task使用一个core,所以在spark算子中,尽量不要使用多线程,因为就一个core,提高不了多少的性能。可以通过spark.task.cpus参数进行调节。
org.apache.spark.scheduler.Pool#getSortedTaskSetQueue 源码如下:
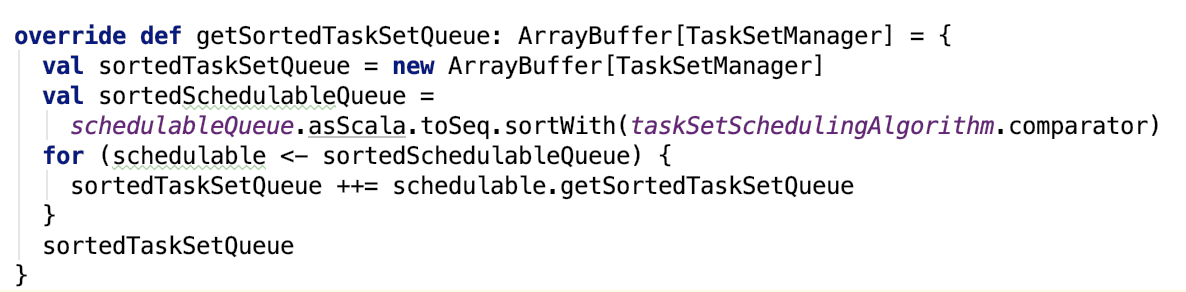
其中TaskSetManager的 getSortedTaskSetManager的源码如下:

重新计算本地性:
org.apache.spark.scheduler.TaskSetManager#executorAdded 的源码如下:

org.apache.spark.scheduler.TaskSetManager#computeValidLocalityLevels 源码如下:

在这里,可以很好的理解五种数据本地性级别。先加入数据本地性数组的优先考虑使用。
为每一个TaskSet分配资源
对应源码如下:

如果slot资源够用或者TaskSet不是barrier的,开始为TaskSet分配资源。
org.apache.spark.scheduler.TaskSchedulerImpl#resourceOfferSingleTaskSet 源码如下:

思路:遍历每一个shuffledOffers,如果其可用cpu核数不小于一个slot所用的核数,则分配资源,分配资源完毕后,记录taskId和taskSetManager的映射关系、taskId和executorId的映射关系、executorId和task的映射关系。最后可用核数减一个slot所以的cpu核数。
其依赖方法 org.apache.spark.scheduler.TaskSetManager#resourceOffer 源码如下,思路:先检查该executor和该executor所在的host都不在黑名单中,若在则返回None,否则开始分配资源。
分配资源步骤:
1. 计算数据本地性。
2. 每一个task出队并构建 TaskDescription 对象。

其依赖方法 org.apache.spark.scheduler.TaskSetManager#getAllowedLocalityLevel 源码如下,目的就是计算该task 的允许的最大数据本地性。

初始化BarrierCoordinator
如果任务资源分配成功并且TaskSet是barrier的,则初始化BarrierCoordinator,源码如下:
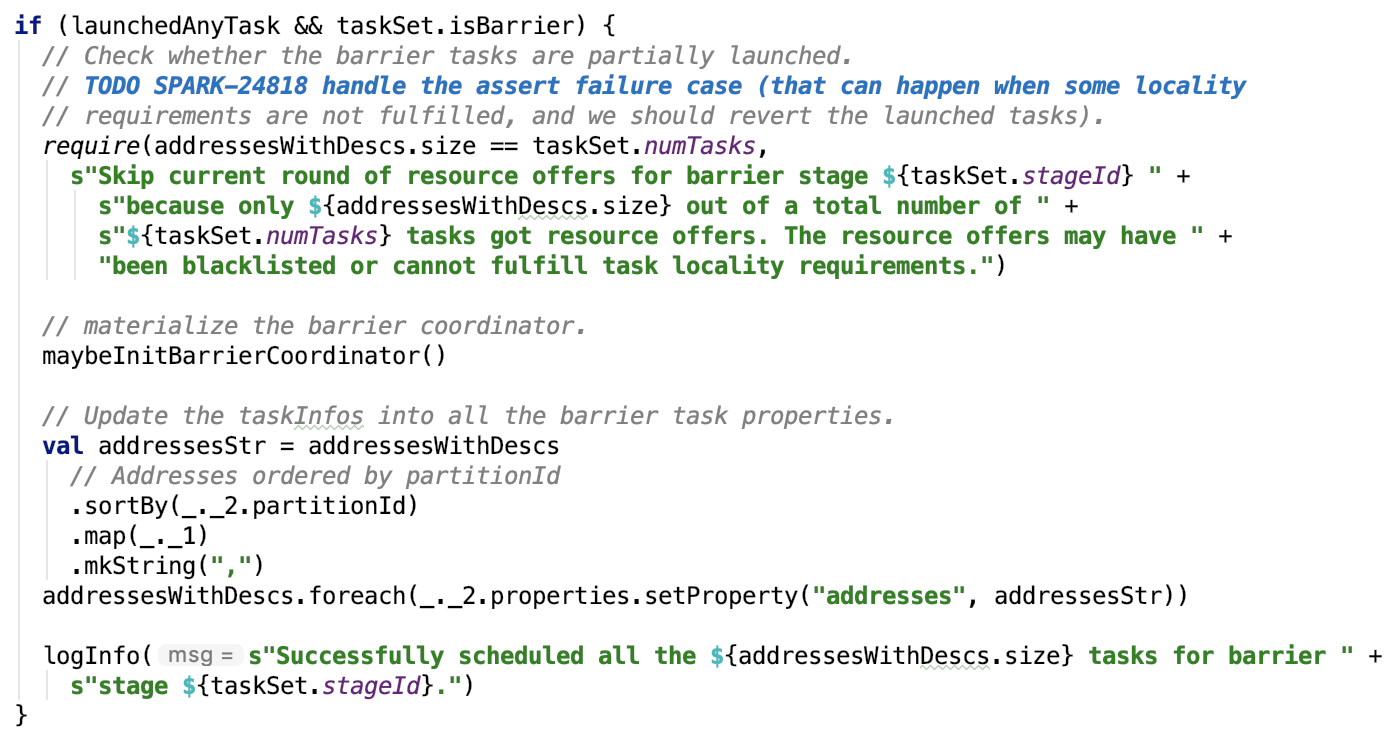
依赖方法 org.apache.spark.scheduler.TaskSchedulerImpl#maybeInitBarrierCoordinator 如下:

运行Task
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverEndpoint#makeOffers中,分配资源结束后,就可以运行task了,源码如下:

序列化TaskDescription
其依赖方法 lauchTasks 源码如下:
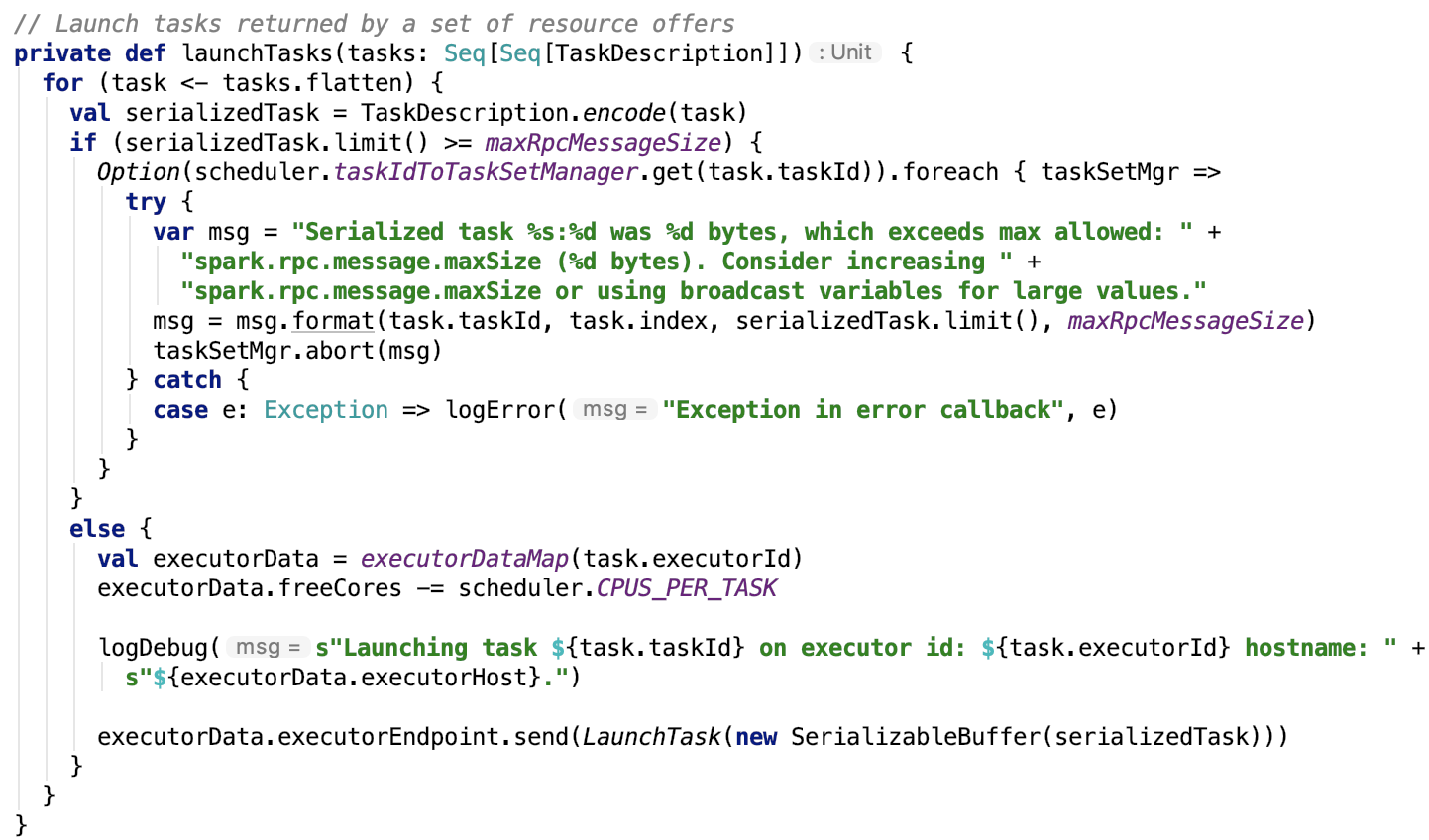
org.apache.spark.scheduler.TaskDescription#encode 方法是一个序列化的操作,将内存中的Java Function对象序列化为字节数组。源码如下:
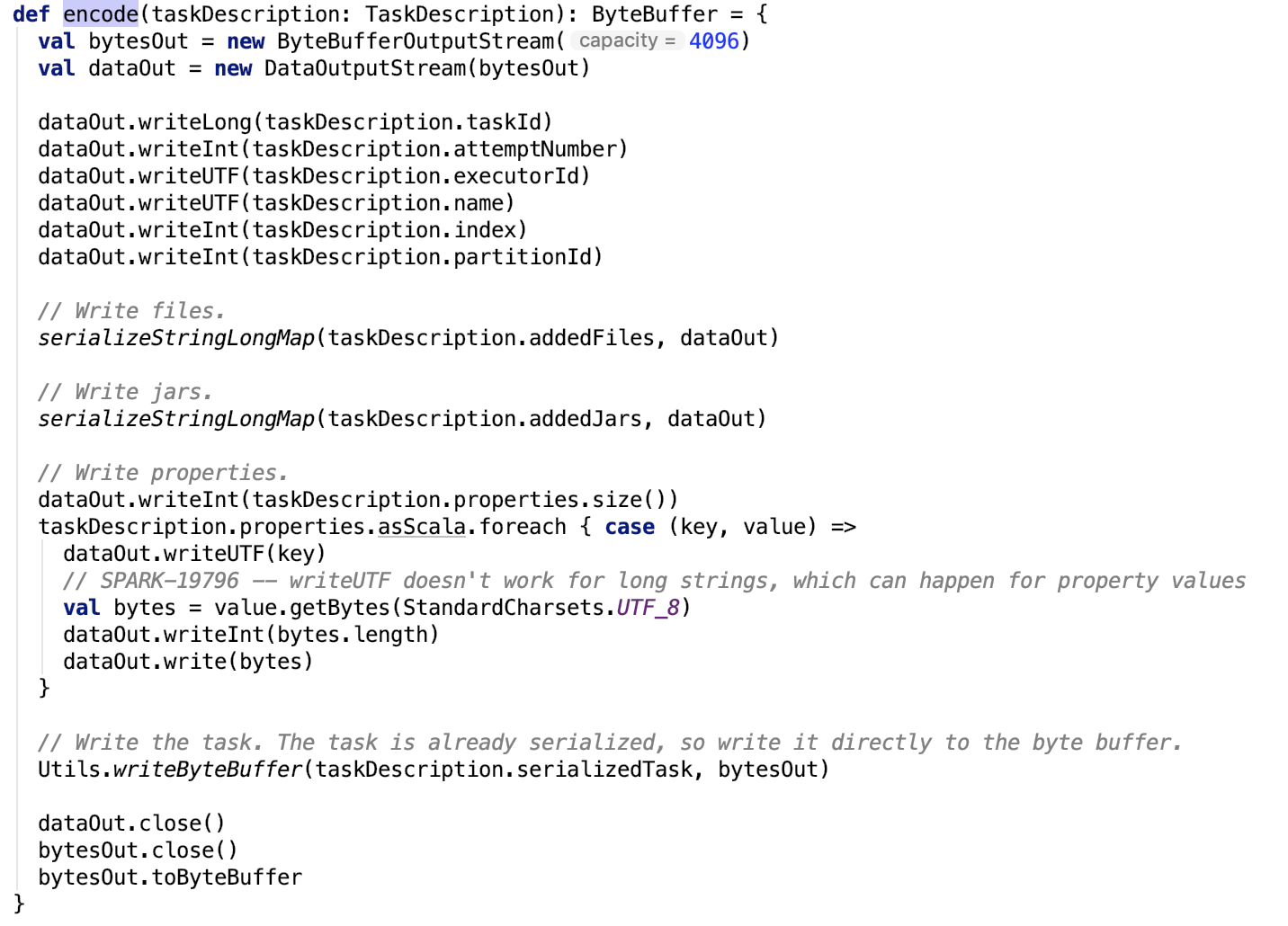
maxRpcMessageSize定义如下:
![]()
org.apache.spark.util.RpcUtils#maxMessageSizeBytes 源码如下:
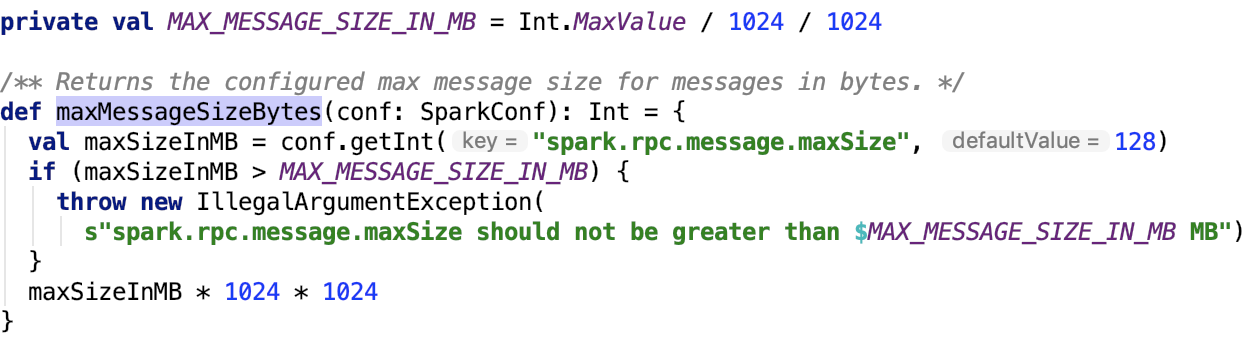
默认为128MB,可以通过参数 spark.rpc.message.maxSize 来调整。
executorData可用核数减去一个Slot所需的核数后,去调用executor运行task。
发送RPC请求executor运行任务
对应 lauchTasks 源码如下:
![]()
经过底层RPC的传输,executorEndpoint的处理代码receive方法处理分支为:

其主要有两步,反序列化TaskDescription字节数据为Java对象。
调用executor来运行task。
下面详细来看每一步。
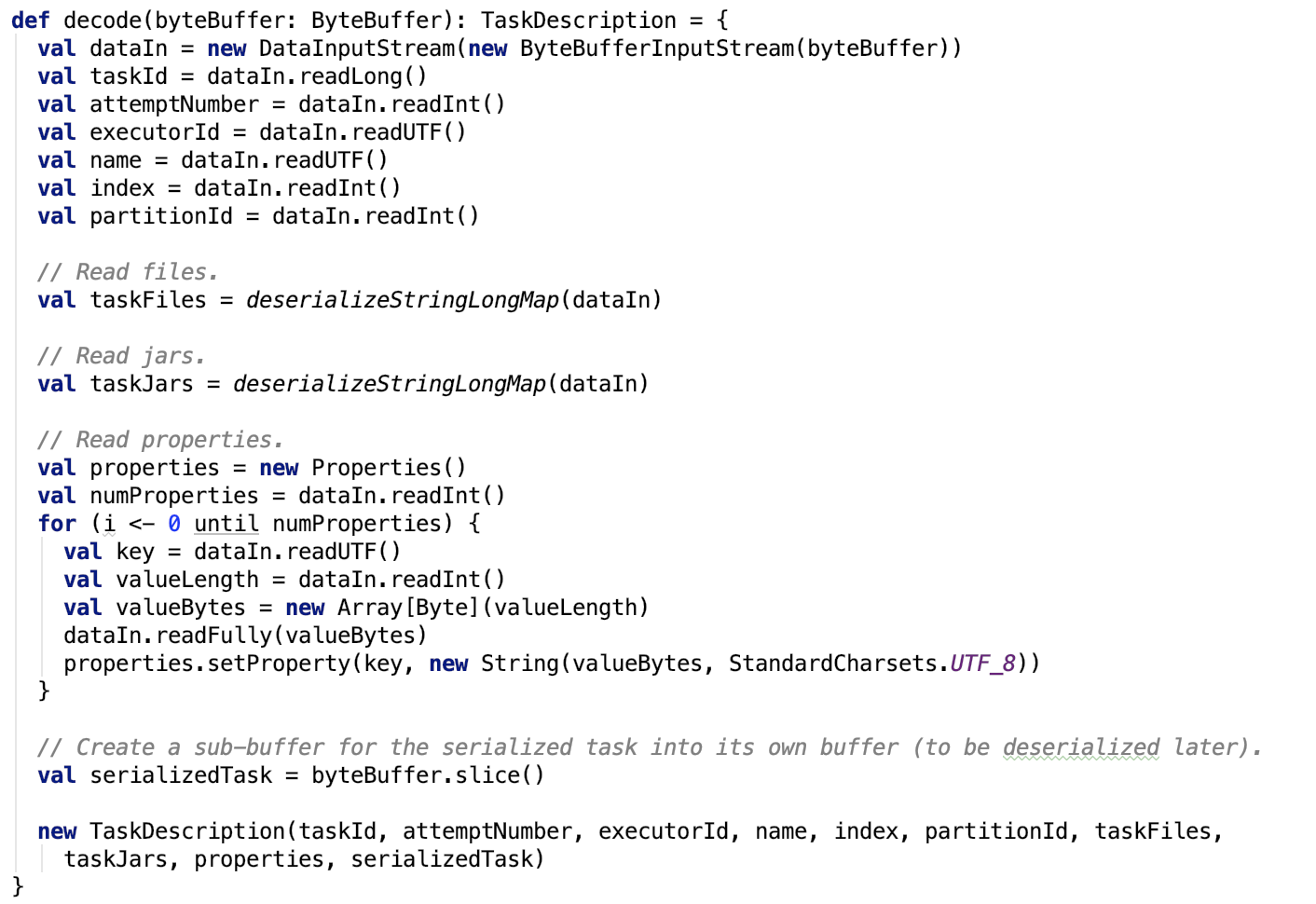
executor反序列化TaskDescription
思路:将通过RPC传输过来的ByteBuffer对象中的字节数据内容反序列化为在内存中的Java对象,即TaskDescription对象。
executor运行task
Executor对象是Spark Executor的抽象,它背后有一个线程池用来执行任务。其实从源码可以看出,Spark的Executor这个术语,其实来自于Java线程池部分的Executors。
launchTasks方法源码如下:

TaskRunner是一个Runnable的实现,worker线程池中的worker会去执行其run方法。
下面来看一下TaskRunner类。
TaskRunner
类说明
它继承了Runnable接口,worker线程池中的worker会去执行其run方法来执行任务,其主要方法如下:
kill任务

运行任务
run方法比较长,划分为四部分来说明。
准备环境
对应源码如下:
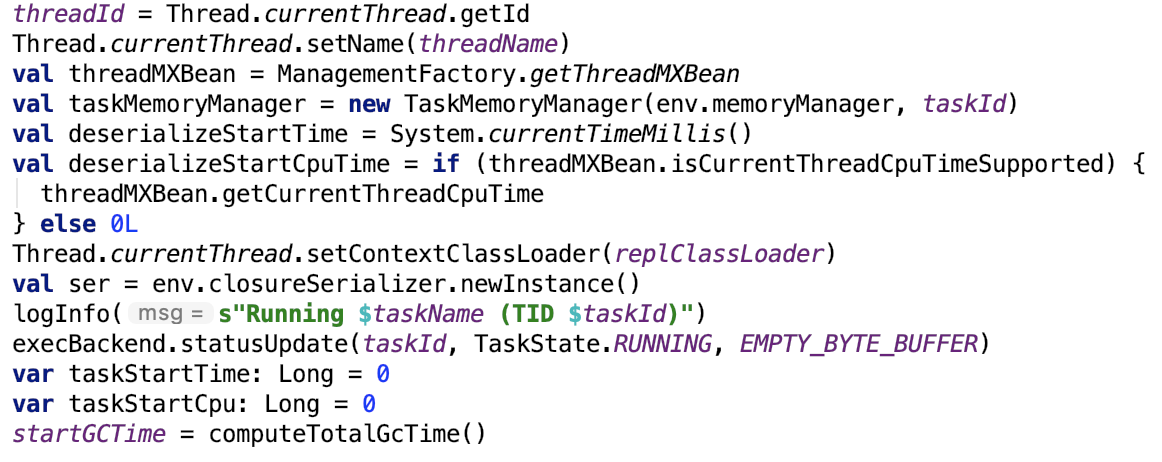
初始化环境,修改task的运行状态为RUNNING,初始化gc时间。
准备task配置
其源码如下:
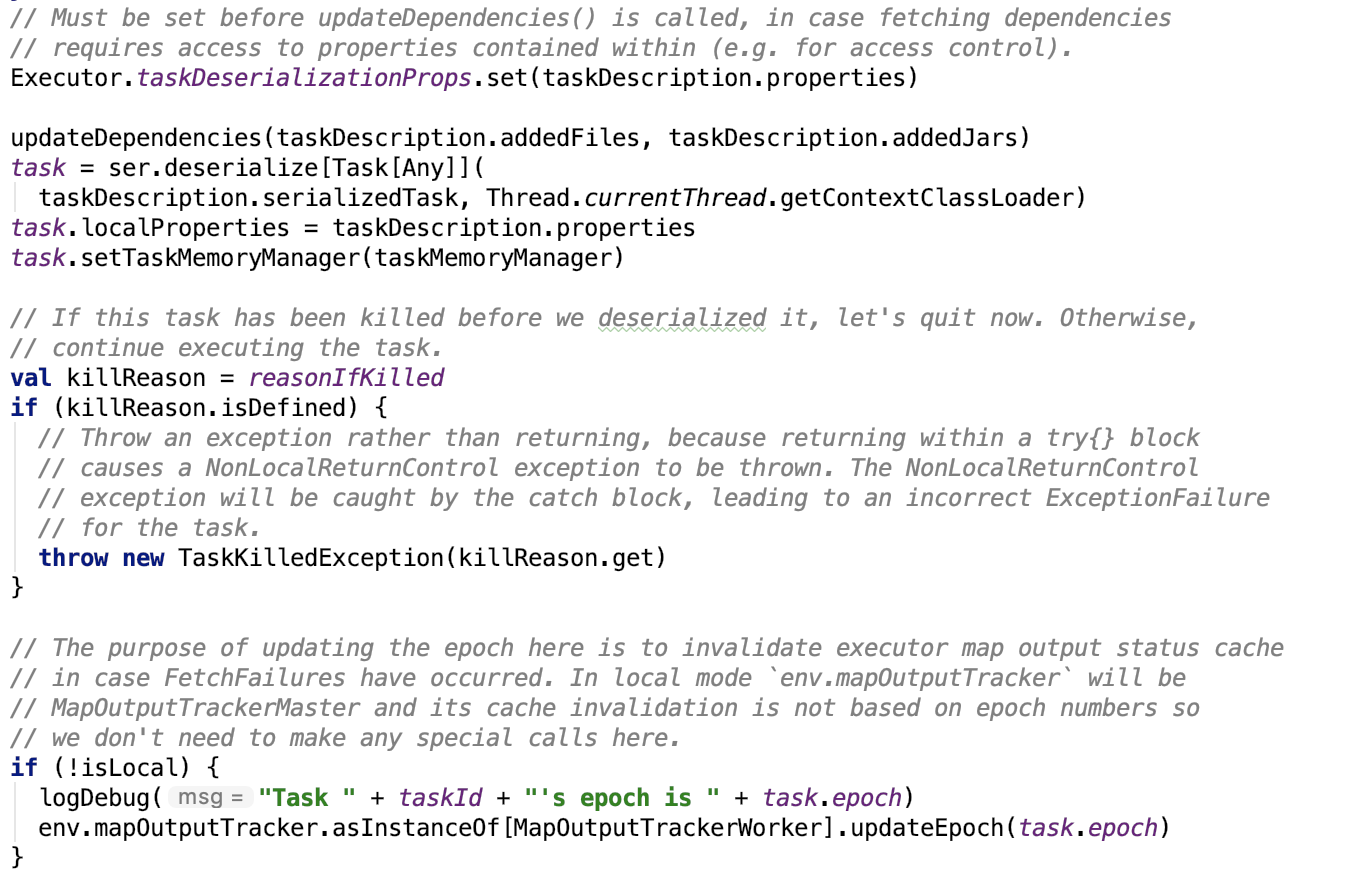
反序列化Task对象,并且设置Task的依赖。

运行task
记录任务开始时间,开始使用cpu时间,运行task,最后释放内存。
其依赖方法 org.apache.spark.util.Utils#tryWithSafeFinally 源码如下:

从源码可以看出,第一个方法是执行的方法,第二个方法是finally方法体中需要执行的方法。即释放内存。
处理失败任务
源码如下:

更新metrics信息
关于metrics的相关内容,不做过多介绍。源码如下:

序列化Task执行结果
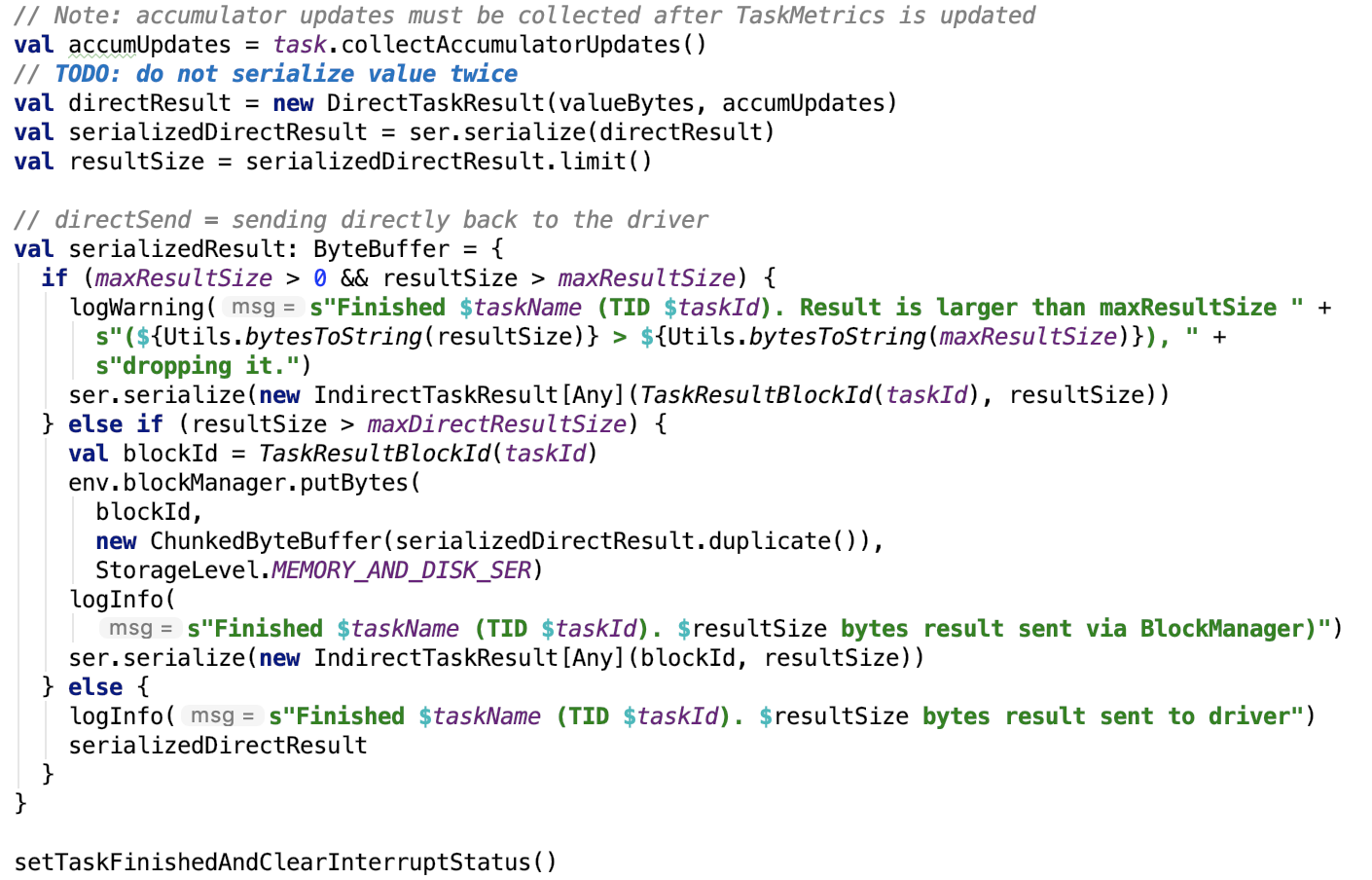
思路:将返回值序列化为ByteBuffer对象。
将结果返回给driver
![]()
org.apache.spark.executor.CoarseGrainedExecutorBackend#statusUpdate 方法如下:

经过rpc后,driver端org.apache.spark.executor.CoarseGrainedExecutorBackend 的 receive 方法如下:
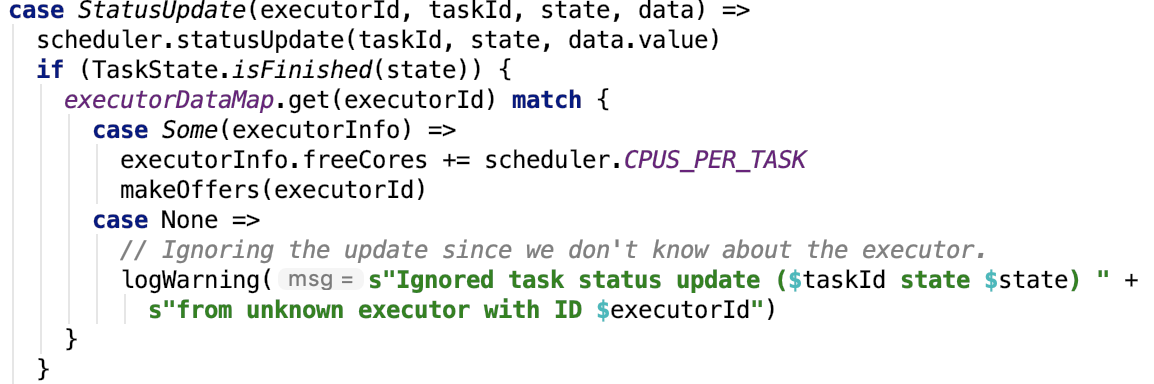
思路:更新task的状态,接着在同一个executor上分配资源,执行任务。
更新task状态
org.apache.spark.scheduler.TaskSchedulerImpl#statusUpdate 方法如下:

处理失败任务
源码如下,不做再深入的剖析:
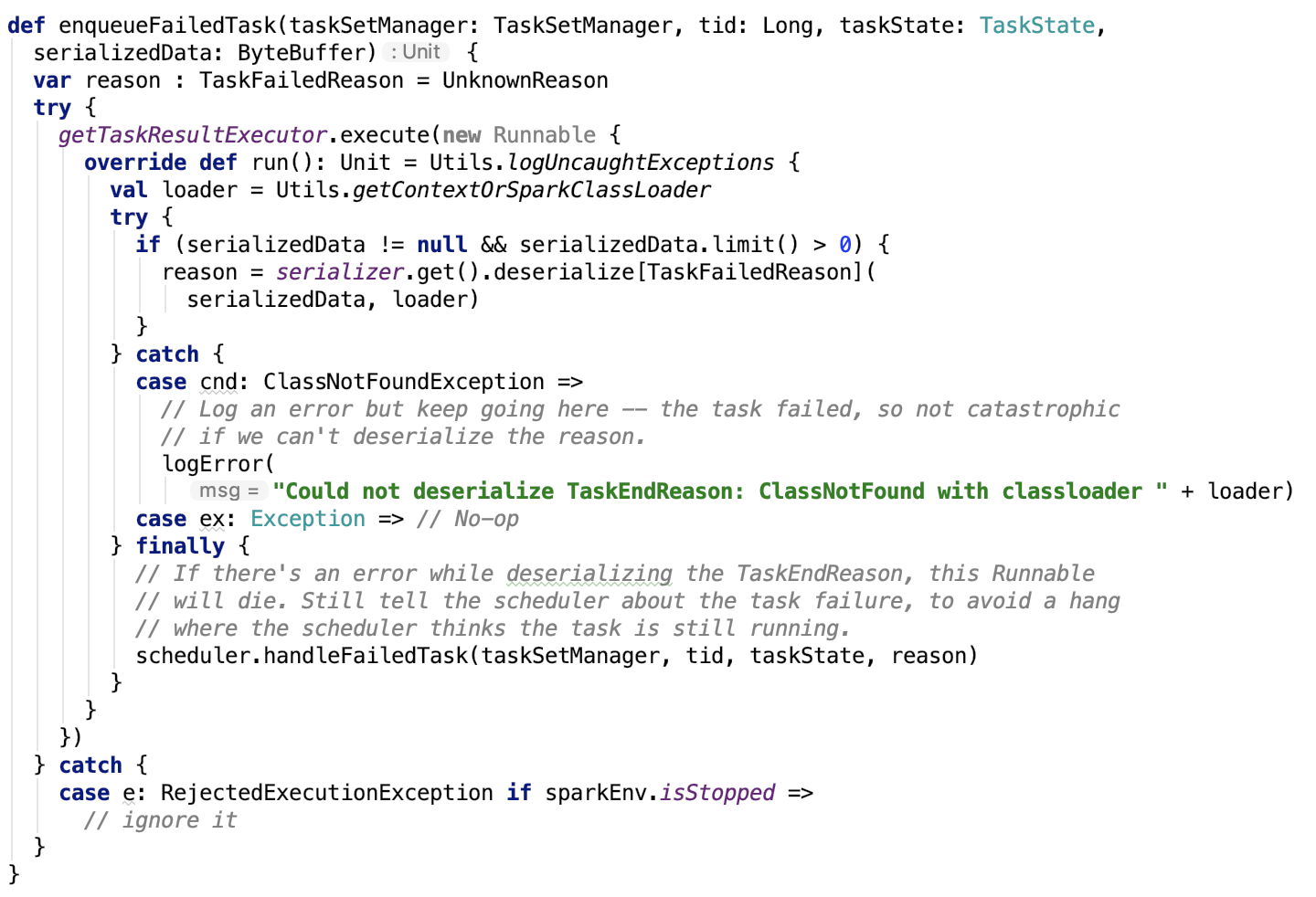
处理成功任务
源码如下:

其依赖方法 org.apache.spark.scheduler.TaskSchedulerImpl#handleSuccessfulTask 源码如下:

org.apache.spark.scheduler.TaskSetManager#handleSuccessfulTask 源码如下:

org.apache.spark.scheduler.TaskSchedulerImpl#markPartitionCompletedInAllTaskSets 源码如下:
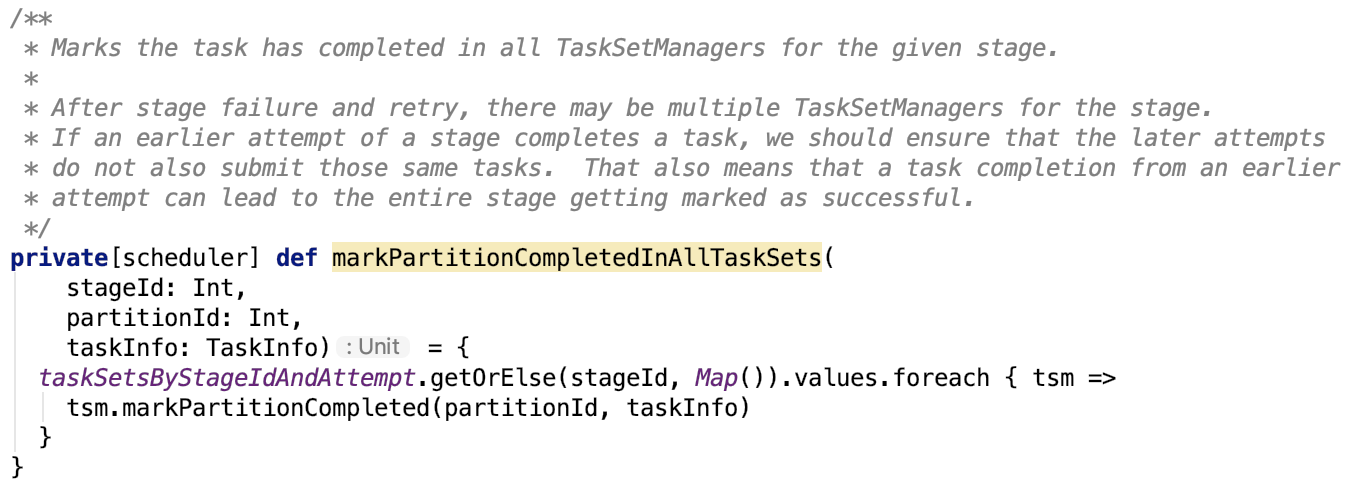
org.apache.spark.scheduler.TaskSetManager#markPartitionCompleted 的源码如下:
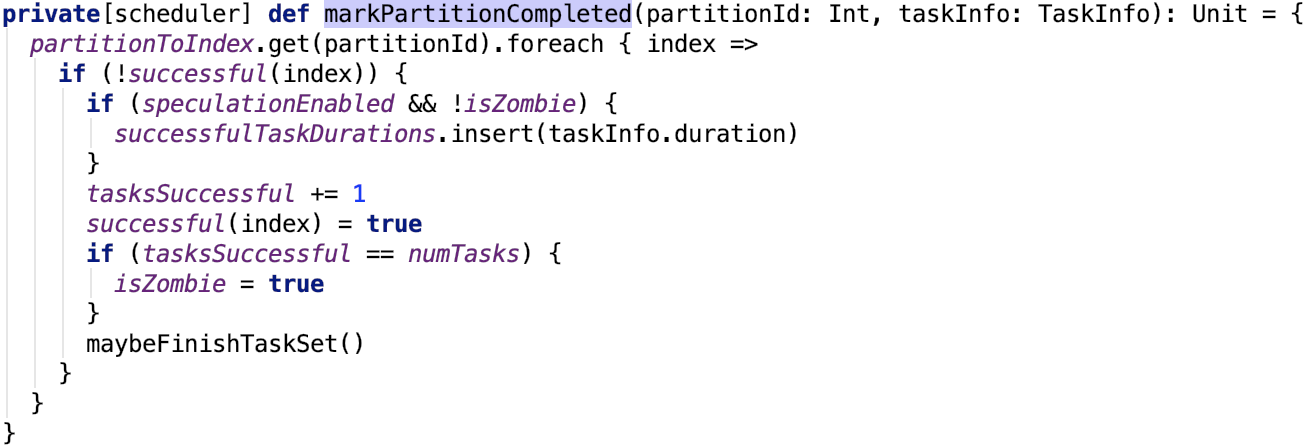
org.apache.spark.scheduler.TaskSetManager#maybeFinishTaskSet 源码如下:

通知DAGScheduler任务已完成
在org.apache.spark.scheduler.TaskSetManager#handleSuccessfulTask 源码中,最后调用了dagScheduler的taskEnded 方法,源码如下:
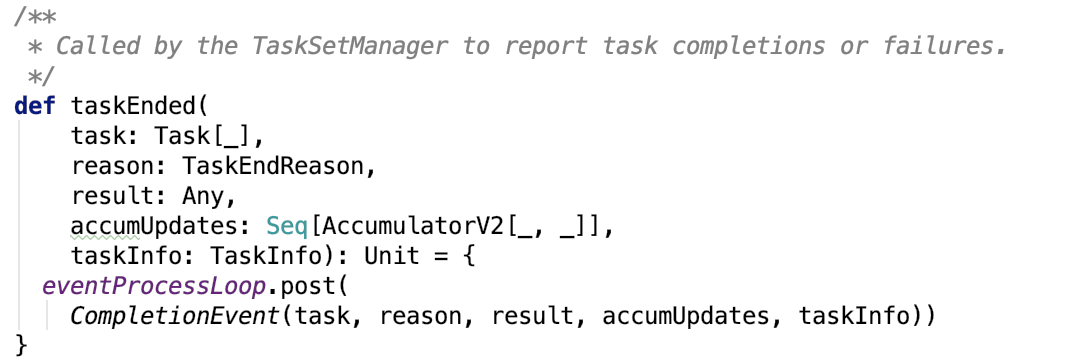
即发送事件消息给eventProcessLoop队列做异步处理:
在 org.apache.spark.scheduler.DAGSchedulerEventProcessLoop#doOnReceive 源码中,处理该事件的分支为:
![]()
即会调用 org.apache.spark.scheduler.DAGScheduler#handleTaskCompletion,源码中处理成功的返回值的代码如下:

我们重点关注其返回值的处理,如果执行的是一个Action操作,则会进入第一个分支。如果执行的是shuffle操作,则会进入第二个分支。
Action作业的返回值处理
先来看第一个分支:
跟返回值有关的代码如下:
![]()
org.apache.spark.scheduler.JobWaiter#taskSucceeded源码如下:

思路:调用RDD定义的resultHandler方法,取出返回值,如果该 task执行完毕之后,所有task都已经执行完毕了,那么jobPromise可以标志为成功,driver就可以拿着action操作返回的值做进一步操作。
假设是collect方法,可以根据 org.apache.spark.SparkContext#submitJob 依赖方法推出resultHandler的定义,如下:

可以知道,resultHandler是在调用方法之前传递过来的方法参数。
我们从collect 方法正向推:

其调用的SparkContext的几个重载的runJob方法如下:
![]()


即,上图中标红的就是resultHandler方法,collect方法是应用于整个RDD的分区的。
也就是说,org.apache.spark.scheduler.JobWaiter#taskSucceeded的第一个参数其实就是partition,第二个参数就是该action在RDD的该partition上计算后的返回值。
该resultHandler方法将返回值,直接赋值给result的特定分区。最终,将所有分区的数据都返回给driver。注意,现在的返回值是数组套数组的形式,即二维数组。
最终collect方法中也定义了二维数组flatten为一维数组的方法,如下:
![]()
这个方法内部是会生成一个ArrayBuilder对象的用来添加数组元素,最终构造新数组返回。这个方法是会内存溢出的,所以不建议使用这个方法获取大量结果数据。
下面,我们来看第二个分支。
Shuffle作业的返回值处理
shuffle作业的返回值是 MapStatus 类型。
先来聊一下MapStatus类。
MapStatus
主要方法如下:
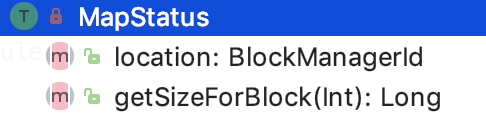
location表示 shuffle的output数据由哪个BlockManager管理着。
getSizeForBlock:获取指定block的大小。
其继承关系如下:
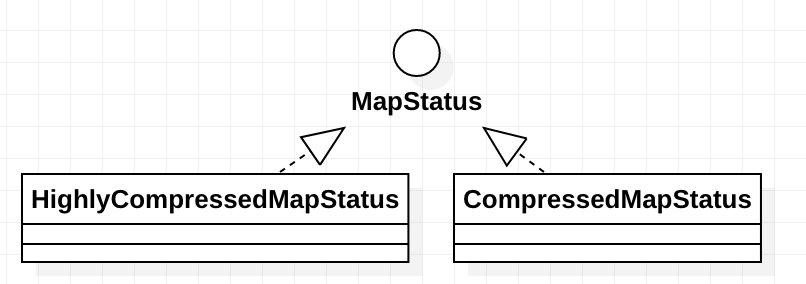
CompressedMapStatus 主要是实现了压缩的MapStatus,即在网络传输进行序列化的时候,可以对MapStatus进行压缩。
HighlyCompressedMapStatus 主要实现了大block的存储,以及保存了block的平均大小以及block是否为空的信息。
处理shuffle 作业返回值
我们只关注返回值的处理,org.apache.spark.scheduler.DAGScheduler#handleTaskCompletion方法中涉及值处理的源码如下:
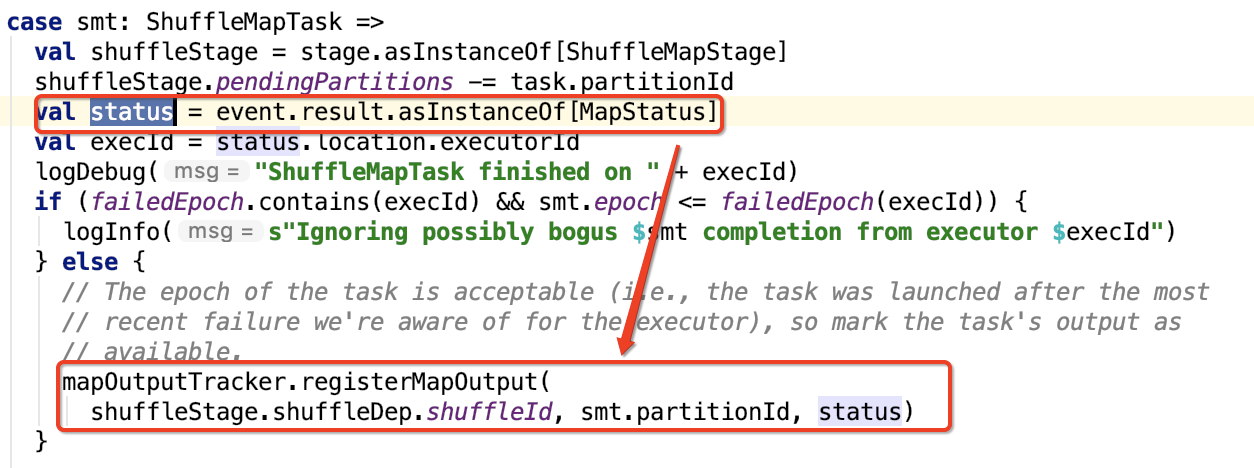
org.apache.spark.MapOutputTrackerMaster#registerMapOutput 的源码如下,mapId就是partition的id:

其中,成员变量 shuffleStatuses 定义如下:

即shuffleStatuses在driver端保存了shuffleId和shuffleStatus的信息。便于后续stage可以调用 MapOutputTrackerMasterEndpoint ref 来获取该stage返回的MapStatus信息。具体内容,我们将在下一节分析。
总结
本篇文章主要介绍了跟Spark内部Task运行的细节流程,关于Task的运行部分没有具体涉及,Task按照ResultStage和ShuffleStage划分为两种Task,ResultStage任务和ShuffleStage分别对应的Task的执行流程有本质的区别,将在下一篇文章进行更加详细的剖析。