import sqlite3
import pandas as pd
conn=sqlite3.connect(r'demo.db')
c=conn.cursor()
创建新表
c.execute("""
CREATE TABLE equipments (
ID integer primary key autoincrement,
设备状态 text,
设备编码 text,
设备名称 text,
资产编码 text,
所属科目 text,
科目名称 text,
规格型号 text,
出厂日期 text,
出厂编号 text,
验收日期 text,
初次调用 text,
设备原值 text,
借用人 text,
借用办公室 text,
借用科组 text,
借用日期 text,
借用凭证 text)
""")
现在有海量数据存储在csv上,如果我们选择也用python脚本将它批量写入db文件:
s=pd.read_csv('file/demo.csv',encoding='gbk') # 有中文的要解码
dataN,paraN=s.shape
ques='('+'?,'*(paraN-1)+'?)' #cursor.execute中的动态参数表示
for i in range(dataN):
a=s.iloc[i].values
b=a[1:]
t=[int(a[0])]+a[1:]# a的第一个是ID,必须是integer类型,而pd读取的都是string,所以要进行转换
c.execute('insert into equipments values '+ques,t)
最后用HeidiSql查询,导入ok
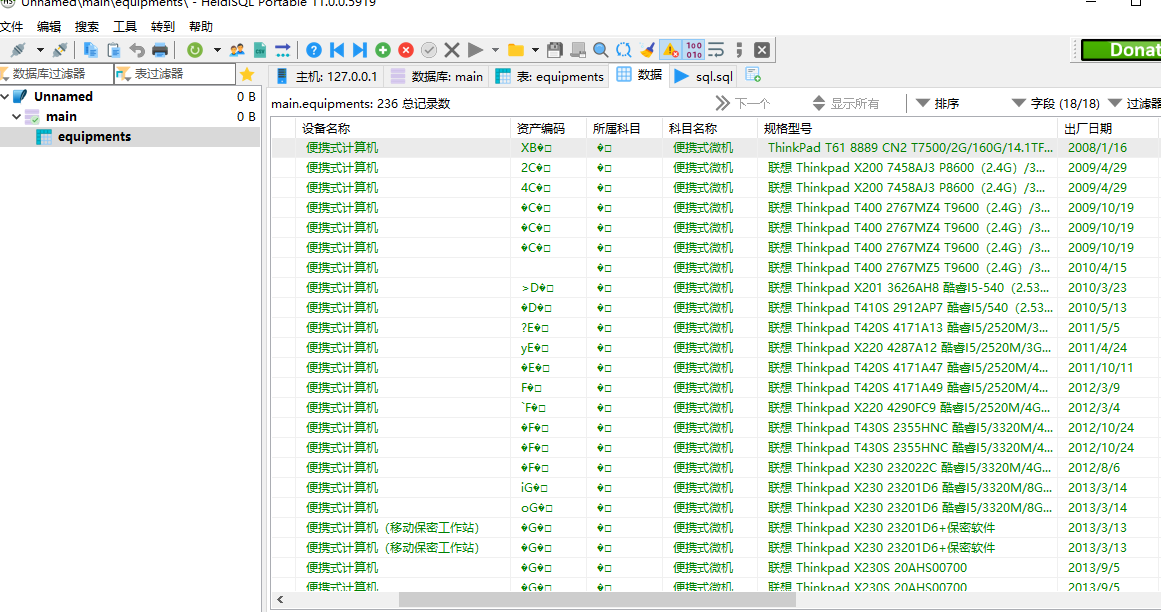
****附:
python sqlite3查看所有表名和表结构:
select name from sqlite_master where type='table' order by name;