Java 基础 基础数据类型与包装器类型
基础数据类型
java 中包含哪些基础数据类型,默认值分别是多少?
| 基础数据类型 | byte | short | int | long | double | float | char | boolean |
|---|---|---|---|---|---|---|---|---|
| 默认值 | 0 | 0 | 0 | 0l | 0.0 | 0.0f | null | false |
基础数据在 JVM 中的存储模型
Java 中的基础模型因为其长度可知、生命周期(存活时间)可知,为了追求速度,基础数据都是存放在栈中的。另外栈有一个特点,就是栈中的数据可以共享。
例如:
// int a = 3;
// int b = 3;
经过查证,上面的说法是不准确的。
基本数据类型的存储分为三种情况:
- 基本数据类型的局部变量
- 基本数据类型的成员变量
- 基本数据类型的常量
基本数据类型的局部变量
定义基本数据类型的局部变量以及数据都是直接存储在内存中的栈上,也就“虚拟机栈”,数据本身的值就是存储在栈空间里面。
这么说好像有点模糊,举个例子吧。
public class baseDemo {
public static void main(String[] args) {
int weight = 50;
int hight = 50;
int age = 18;
Person per = new Person();
}
}
这段代码中所有的基本类型都是局部变量,我们从第一个开始看
int weight = 50;
// 这段代码可以分解为
int weight; // 定义局部变量
weight = 50; // 为局部变量赋值
首先在栈帧的局部变量中创建一个局部变量 weight,然后在栈中寻找有没有字面量为 50 的,如果有就直接指向,就当前代码来看,显然是没有,那么 JVM 会在栈中创建一个字面量为 50 的空间,并将 weight 变量指向这个地址。因此我们可以得知:
我们创建的基本数据类型的局部变量,变量名以及字面值都是存放在栈中的。而且是真实的内容。
然后我们接着往下看:
int hight = 50;
// 这段代码可以分解为
int hight; // 定义局部变量
hight = 50; // 为局部变量赋值
这里也是一样的,创建局部变量 hight,从栈中寻找有没有字面量为 50 的内容,刚好我们之前创建 weight 的时候已经创建过字面量为 50 的内容,所以hight直接指向这个地址。由此可见:
栈中的数据在当前线程下是共享的
基本数据类型的数据本身是不会改变的,当局部变量重新赋值时,并不是在内存中改变字面量内容,而是重新在栈中寻找已存在的相同的数据,若栈中不存在,则重新开辟内存存新数据,并且把要重新赋值的局部变量的引用指向新数据所在地址。
基本数据类型的成员变量
成员变量,也就是在类中声明的变量。例如:
public class Person {
private int age;
private String name;
private int sex;
private long idCard;
}
// 通用方法
Person per = new Person();
age、name、sex、idCard被存储到了堆中为per对象开辟的一块空间中。因此可知:基本数据类型的成员变量名和值都存储于堆中,其生命周期和对象的是一致的。
基本数据类型的常量
JVM 中方法区用来存储一些共享数据,因此基本数据类型的静态变量名以及值存储于方法区的运行时常量池中,静态变量随类加载而加载,随类消失而消失
基础数据类型的自动转换
基础类型的自动转换规则包括自动、强制、提升三种
自动类型转换是指:数字范围小的数据类型可以自动转换成数据范围大的类型
int a = 100;
long b = a;
具体可以残照下面这张图:
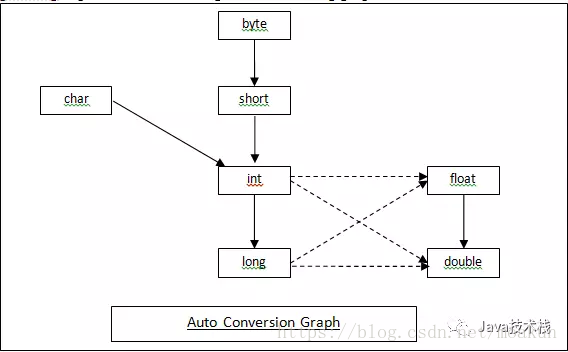
实线表示自动转换时不会造成数据丢失,虚线则可能会出现数据丢失问题。
在自动转换的过程中也需要考虑溢出问题,例如:
int a = Integer.MAX_VALUE;
int b = 2;
long c = a + b;
System.out.println(c);
// out -2147483647
在这种情况下编译器不会报错,但是打印出来的结果是负数(溢出)。因为jvm 中对其进行计算的时候,是先计算两个 int 的和,再将其自动转换为 long,但是在计算过程中,a和 b的和已经大于 int 的最大值,也就是说在自动转换之前结果已经是负数了,所以转换成 long 之后依然是负数。
另外,向下转换的时候可以直接将 int 的常量直接赋予给char、short、byte,只要常量的数字小于这些基础类型的最大上限,所以可以自动转换
short d = 3;
char e = 4;
byte f = 1;
下图中的 g 报错了,是因为int 的常量超过了 byte 的最大限度。
short d = 3;
char e = 4;
byte f = 1;
byte g = 128;
包装器类型
包装器类型与基础数据类型对应关系
| 包装器类型 | byte | char | short | int | long | double | float | boolean |
|---|---|---|---|---|---|---|---|---|
| 基础数据类型 | Byte | Character | Short | Integer | Long | Double | Float | Boolean |
自动装/拆箱何时触发
这里情况比较多,所以我们直接在代码中体现吧
// 自动装箱
Integer num1 = 1;
Integer num2 = 2;
Integer num3 = 3;
// num1 + num2 触发自动拆箱,然后因为要和 Integer 类型的num3 进行 equals 比较,所以又触发自动装箱
// Integer.equals 返回的是 boolean,但是我们是使用 Boolean 类型接收的,这里又触发了自动装箱
Boolean flag = num3.equals(num1 + num2);
Integer 的 equals源码
/**
* Compares this object to the specified object. The result is
* {@code true} if and only if the argument is not
* {@code null} and is an {@code Integer} object that
* contains the same {@code int} value as this object.
*
* @param obj the object to compare with.
* @return {@code true} if the objects are the same;
* {@code false} otherwise.
*/
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
包装器类型在 JVM 内存中的存储模型
包装器类型的对象存储在堆中,引用存储在栈中,通过栈来操作对象。但是部分是直接从存放在常量池中的比如 Integer 的 -128 ~ 127
基础数据类型和包装器类型的适用场景
- 基础数据类型适合用于方法内部的局部变量,随着方法的调用创建在栈中,随着方法一起被回收销毁。
- 包装器有一个基础数据类型没有的优点,就是默认值是 null,可以通过是否为 null 直观的判断这个数据是不是被赋值过。比如:使用 Mybatis 从数据库中获取数据的时候,如果这个是 int类型,但是其实这条数据这个字段是空,就会出问题。
- 基本类型与对象类型最大的不同点在于,基本类型基于数值,对象类型基于引用。