今天和郑晓龙沟通Redis使用的过程中,吐槽现在隆众平台很多地方出现了数据更新后,Redis和数据库中的数据不一致的问题。
然后就诱发了这个问题的讨论,我的观点是对数据进行修改后,也要同步更新Redis中的数据,即重新set一个value进去。晓龙的意见是数据更新后,对redis中对应的key执行删除操作,redis中值根据后续请求再自动生成。
后面我查阅了部分文章,发现都是推荐使用晓龙的这种方案。
首先简单说说为什么现在数据库和Redis的查询逻辑关系:
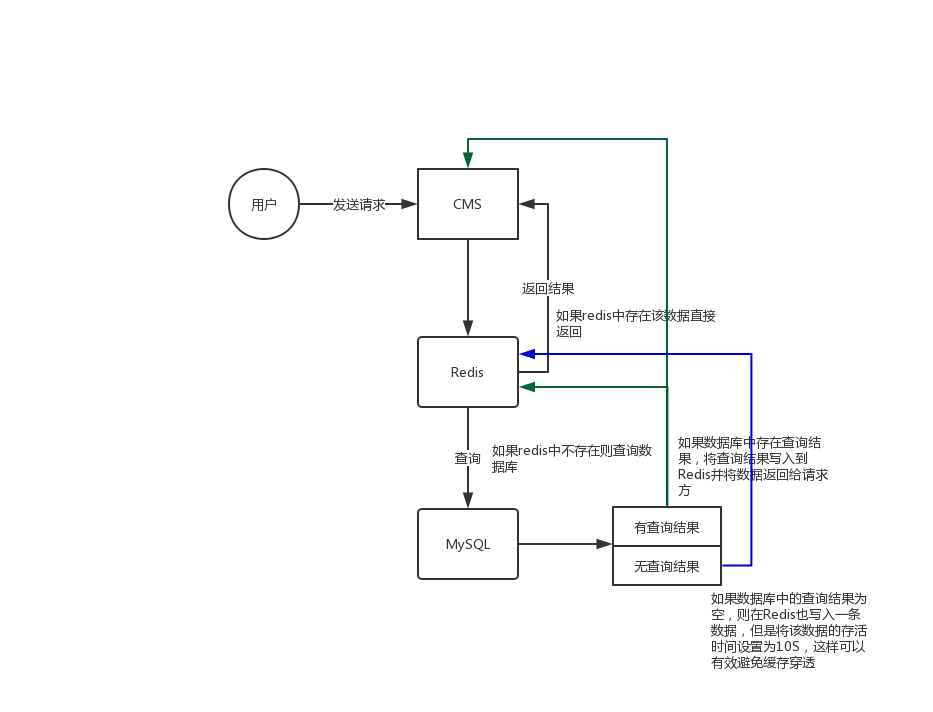
这里简单的说一下目前主流的几种保证Redis和数据库双写一致性的方案以及优缺点:
- 先更新数据库,再更新Redis
- 先删除Redis,再更新数据库
- 先更新数据库,再删除Redis
博主在文档中也说了,应该没有人会问为什么不能先更新Redis,再更新数据库。我对这句话的理解是数据库的更新可能会出现失败的情况,如果你先更新了Redis再更新数据库的话,也会导致Redis双写不一致的情况出现。这样从本质上就是不可行的。而且部分复杂点的缓存场景,缓存的数据不是不是直接从数据库中获取的到的数据放入缓存中的,缓存中的结果是多个表的查询结果,然后关联在一起,经过一系列复杂的运算,才能最终计算出想要的结果,然后再放在缓存中。如果对其中一个表的数据进行修改之前对Redis进行更新,开销较大。
下面再分别说说上面三种情况的问题:
先更新数据库,再更新Redis
先更新数据库,再更新Redis这种方案本身是没有什么问题的,但是问题出现在多线程情况下,现在我们假设有两个请求都会对数据库进行修改,线程分别叫A和B,且执行顺序如下:
- A修改数据库
- B修改数据库
- B更新Redis
- B结束
- A更新Redis
- A结束
那么这个时候,程序再从Redis中获取的值是A修改得结果,但是按照执行顺序来看,理想结果是获取到B的修改结果,所以这种方案可能会使Redis中存储到脏数据。
其次如果场景是写数据比较多,读数据比较少的业务需求,如果使用这种方案就会导致数据还没有被读取的时候,缓存就频繁的更新,浪费性能。其次如果写入数据库中的值并不是直接写入缓存的,也就是说缓存中存在值是经过计算之后的结果,这种方案就会导致查询的时候再次重新计算浪费性能。
到现在来看这种方案是存在问题的,那么此时我们再看看第二种方案是否可行。
先删除Redis,再更新数据库
这种情况会出现什么问题呢,再举一个例子,如果同时出现了对同一条数据的修改和查询操作,线程A负责对数据进行修改,线程B对数据进行查询。且执行顺序如下:
- A删除Redis
- B发送查询请求
- B新生成一个Redis
- B结束
- A修改数据库
- A结束
这个时候,B返回的结果其实是修改之前的结果,因为B在生成结果并存入Redis的时候,数据库中的数据还没有被修改,所以会导致Redis中出现脏数据。
这种情况下,给出一种方案:延时双删除策略
// 伪代码
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}
先更新数据库 ,再删除Redis
最后在看一下先更新数据库,后删除Redis是不是就没问题了,不是的,在及其特殊的情况下也会出现问题。还是AB两个线程一个读取一个修改。
- A开始进行数据查询
- 此时Redis中的对应的key的过期时间刚好到了,也就是A从Redis中获取不到数据
- A从数据库读取到数据
- B开始更新数据
- B删除缓存
- A将第三部读取到的数据写入Redis
这种情况下Redis中值还是错的,但是这种情况难以发生,因为要满足的这个要求前提条件是需要数据库的写入速度快于读取速度,因此这一情况很难出现。
还有一种出现脏数据的情况,即修改完成数据后由于各种原因Redis key删除失败了。
面对这种情况我们就要考虑重试机制了。
目前有两种处理模式:
方案一:

流程如下所示
(1)更新数据库数据;
(2)缓存因为种种问题删除失败
(3)将需要删除的key发送至消息队列
(4)自己消费消息,获得需要删除的key
(5)继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案二:
流程如下所示:
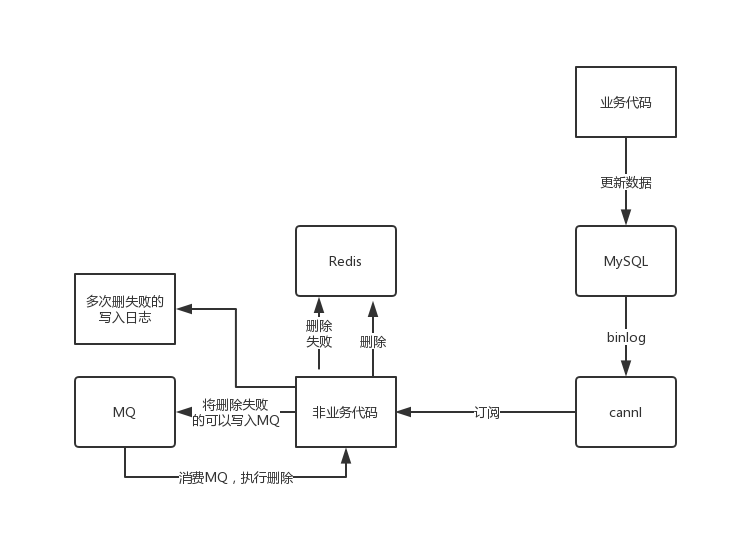
(1)更新数据库数据
(2)MySQL会将操作日志写入binlog中,然后通过cannl模拟从数据库同步到命令
(3)利用一段非业务代码获取订阅的数据
(4)执行删除key操作,如果成功,则结束;如果失败,则将删除的key记录一下并放入MQ中
(5)消费MQ中key重新执行删除操作,如果多次删除失败 如5次,则计入日志,人工介入研判为什么失败。
当然MQ也会有丢数据的可能,这就得看MQ的设置了。这里就不再过多的赘述。
现在我们看到的情况其实本质上还是会出现双写不一致的情况的,如果要强制要求必须一直的话,需要在程序中通过一系列算法,将相同的key对应在相同的内存队列中。也就是说你的读取操作就一定会放在修改操作之后进行,这样才能从本质上避免双写不一致的情况出现。具体可以参考石杉大佬的笔记: