Elasticsearch中数据都存储在分片中,当执行搜索时每个分片独立搜索后,数据再经过整合返回。那么,如果要实现分页查询该怎么办呢?
更多内容参考Elasticsearch资料汇总
按照一般的查询流程来说,如果我想查询前10条数据:
- 1 客户端请求发给某个节点
- 2 节点转发给个个分片,查询每个分片上的前10条
- 3 结果返回给节点,整合数据,提取前10条
- 4 返回给请求客户端
那么当我想要查询第10条到第20条的数据该怎么办呢?这个时候就用到分页查询了。
from-size"浅"分页
"浅"分页的概念是小博主自己定义的,可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。
查询的方法如:
{
"from" : 0, "size" : 10,
"query" : {
"term" : { "user" : "kimchy" }
}
}其中,from定义了目标数据的偏移值,size定义当前返回的事件数目。
默认from为0,size为10,即所有的查询默认仅仅返回前10条数据。
做过测试,越往后的分页,执行的效率越低。
通过下图可以看出,刨去一些异常的数据,总体上还是会随着from的增加,消耗时间也会增加。而且数据量越大,效果越明显!
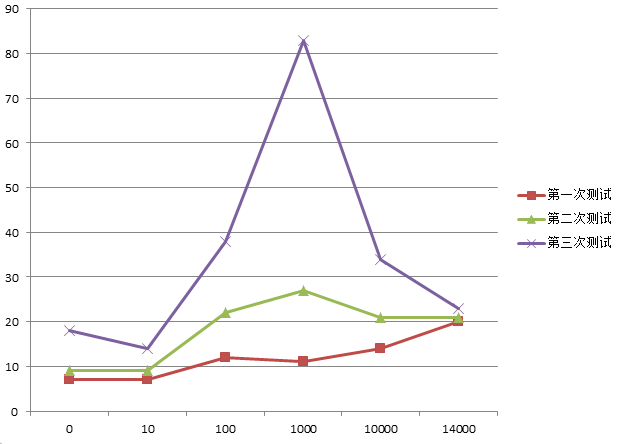
也就是说,分页的偏移值越大,执行分页查询时间就会越长!
scroll“深”分页
相对于from和size的分页来说,使用scroll可以模拟一个传统数据的游标,记录当前读取的文档信息位置。这个分页的用法,不是为了实时查询数据,而是为了一次性查询大量的数据(甚至是全部的数据)。
因为这个scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个scroll查询时的快照。在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。但是它相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
API使用方法如:
curl -XGET 'localhost:9200/twitter/tweet/_search?scroll=1m' -d '
{
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
'会自动返回一个_scroll_id,通过这个id可以继续查询(实际上这个ID会很长哦!):
curl -XGET 'localhost:9200/_search/scroll?scroll=1m&scroll_id=c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1'注意,我在使用1.4版本的ES时,只支持把参数放在URL路径里面,不支持在JSON body中使用。
有个很有意思的事情,细心的会发现,这个ID其实是通过base64编码的:
cXVlcnlUaGVuRmV0Y2g7MTY7MjI3NTp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyNzQ6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjgwOnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI4MTp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyODM6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjgyOnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI4Njp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyODc6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjg5OnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI4NDp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyODU6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjg4OnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI3Njp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyNzc6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjc4OnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI3OTp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzA7如果使用解码工具可以看到:
queryThenFetch;16;2275:vtXKJ8lnQImdiwcDtPT-kA;2274:vtXKJ8lnQImdiwcDtPT-kA;2280:vtXKJ8lnQImdiwcDtPT-kA;2281:vtXKJ8lnQImdiwcDtPT-kA;2283:vtXKJ8lnQImdiwcDtPT-kA;2282:vtXKJ8lnQImdiwcDtPT-kA;2286:vtXKJ8lnQImdiwcDtPT-kA;2287:vtXKJ8lnQImdiwcDtPT-kA;2289:vtXKJ8lnQImdiwcDtPT-kA;2284:vtXKJ8lnQImdiwcDtPT-kA;2285:vtXKJ8lnQImdiwcDtPT-kA;2288:vtXKJ8lnQImdiwcDtPT-kA;2276:vtXKJ8lnQImdiwcDtPT-kA;2277:vtXKJ8lnQImdiwcDtPT-kA;2278:vtXKJ8lnQImdiwcDtPT-kA;2279:vtXKJ8lnQImdiwcDtPT-kA;0;虽然搞不清楚里面是什么内容,但是看到了一堆规则的键值对,总是让人兴奋一下!
测试from&size VS scroll的性能
首先呢,需要在java中引入elasticsearch-jar,比如使用maven:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>1.4.4</version>
</dependency>然后初始化一个client对象:
private static TransportClient client;
private static String INDEX = "index_name";
private static String TYPE = "type_name";
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> TransportClient <span class="hljs-title">init</span><span class="hljs-params">()</span></span>{
Settings settings = ImmutableSettings.settingsBuilder()
.put(<span class="hljs-string">"client.transport.sniff"</span>, <span class="hljs-keyword">true</span>)
.put(<span class="hljs-string">"cluster.name"</span>, <span class="hljs-string">"cluster_name"</span>)
.build();
client = <span class="hljs-keyword">new</span> TransportClient(settings).addTransportAddress(<span class="hljs-keyword">new</span> InetSocketTransportAddress(<span class="hljs-string">"localhost"</span>,<span class="hljs-number">9300</span>));
<span class="hljs-keyword">return</span> client;
}
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-keyword">void</span> <span class="hljs-title">main</span><span class="hljs-params">(String[] args)</span> </span>{
TransportClient client = init();
<span class="hljs-comment">//这样就可以使用client执行查询了</span>
}</code></pre>
然后就是创建两个查询过程了 ,下面是from-size分页的执行代码:
System.out.println("from size 模式启动!");
Date begin = new Date();
long count = client.prepareCount(INDEX).setTypes(TYPE).execute().actionGet().getCount();
SearchRequestBuilder requestBuilder = client.prepareSearch(INDEX).setTypes(TYPE).setQuery(QueryBuilders.matchAllQuery());
for(int i=0,sum=0; sum<count; i++){
SearchResponse response = requestBuilder.setFrom(i).setSize(50000).execute().actionGet();
sum += response.getHits().hits().length;
System.out.println("总量"+count+" 已经查到"+sum);
}
Date end = new Date();
System.out.println("耗时: "+(end.getTime()-begin.getTime()));
下面是scroll分页的执行代码,注意啊!scroll里面的size是相对于每个分片来说的,所以实际返回的数量是:分片的数量*size
System.out.println("scroll 模式启动!");
begin = new Date();
SearchResponse scrollResponse = client.prepareSearch(INDEX)
.setSearchType(SearchType.SCAN).setSize(10000).setScroll(TimeValue.timeValueMinutes(1))
.execute().actionGet();
count = scrollResponse.getHits().getTotalHits();//第一次不返回数据
for(int i=0,sum=0; sum<count; i++){
scrollResponse = client.prepareSearchScroll(scrollResponse.getScrollId())
.setScroll(TimeValue.timeValueMinutes(8))
.execute().actionGet();
sum += scrollResponse.getHits().hits().length;
System.out.println("总量"+count+" 已经查到"+sum);
}
end = new Date();
System.out.println("耗时: "+(end.getTime()-begin.getTime()));
我这里总的数据有33万多,分别以每页5000,10000,50000的数据量请求,得到如下的执行时间:
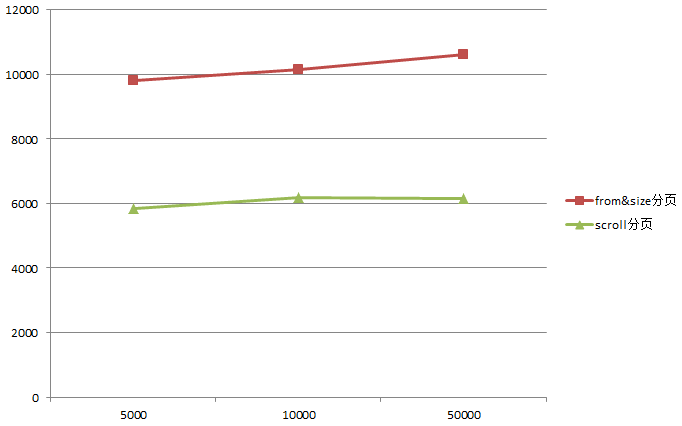
可以看到仅仅30万,就相差接近一倍的性能,更何况是如今的大数据环境...因此,如果想要对全量数据进行操作,快换掉fromsize,使用scroll吧!
参考
1 简书:elasticsearch 的滚动(scroll)
2 16php:Elasticsearch Scroll API详解
3 elastic:from-size查询
4 elastic:scroll query