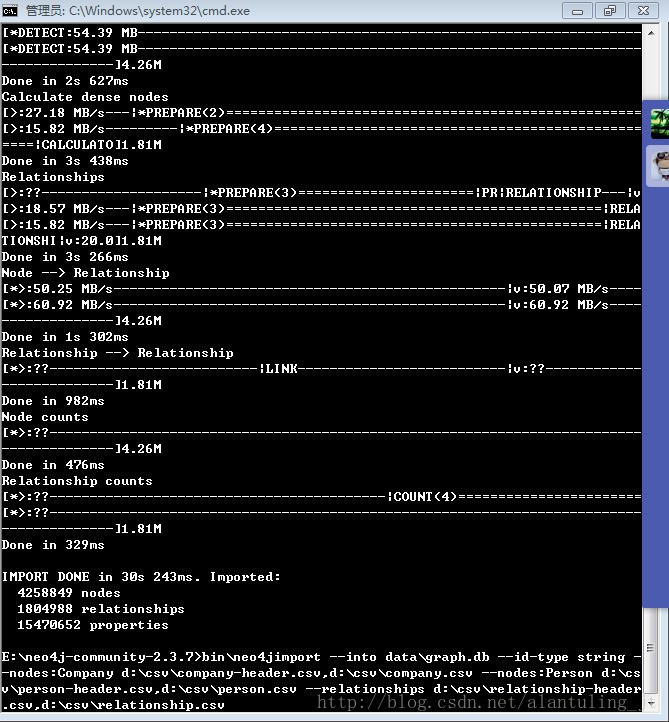
先上图:425万nodes、180万relationships只用了30s 243ms
项目需要生成关系图,开始考虑的是用Neo4j官网提供的REST API,从solr中查出2组数据先创建节点再创建关系,过程相当痛苦,速度非常慢,一天都处理不完;
后来改用cypher语句,通过load csv方法,先将数据生成cvs节点文件和关系文件,再通过load csv file create 语法创建,但文件超过30万条时,服务就出错了,遂放弃;
以上2种方法适合小数据量的图库操作,和局部插入更新,不适合大量数据的导入,生成关系图;
后来通过使用官方提供的Neo4jImport 命令行导入数据成功。命令格式在上图中最下面部分有。
首先是要通过查库生成一定格式的csv数据,按node,relationship分别生成,这个可以通过java写代码生成,格式如下:
例子:
节点文件:
文件名:person.csv
文件内容:
id:ID,name,sex,age
p123,jobs,male,28
文件名:company-header.csv
文件内容:
id:ID,entName
文件名:company.csv
文件内容:
c111,Apple
关系文件:
文件名:relationship-header.csv
文件内容:
:START_ID,:END_ID,:TYPE
文件名:relationship.csv
文件内容:
p123,c111,founder
说明:其中一个文件可以分两部分写,一部分写文件头部信息,这些可能需要人为更改,较方便;内容部分一般是代码生成,数据量大,打开修改很费事,一般不动,所以建议分开写,如例子中company-header.csv和company.csv文件就分属于头部文件和内容文件。
:ID表示此列的值作为接连值,并会创建索引,所以如果这列的值有重复,在创建的时候会报错;
:START_ID表示起始节点的ID值;
:END_ID表示结束节点的ID值;
:TYPE表示关系值;
例子中表示的是jobs是Apple公司的创始人;
当然还有其他一些格式,比如:
:LABEL 给列设置标签,可以设置多个标签,用分号分隔;
:IGNORE该列不创建properties
:START_ID(Company)指定该列只能是company中ID的值,前提是company中id:ID(Company)也这样写。
另外,有问题可以留言探讨,我也是刚研究了一周。
原文地址:https://www.jianshu.com/p/0aff60f766f3