第一天机器学习100天|Day1数据预处理,我们学习了数据预处理。知道了,数据预处理是机器学习中最基础和最麻烦,未来占用时间最长的一步操作。数据预处理一般有六个步骤,导入库、导入数据集、处理缺失值、分类数据转化、分出训练集和测试集、特征缩放等。在处理数据过程中,必须得两个库是numpy和pandas,也用到sklearn.preprocessing中的Imputer,LabelEncoder, OneHotEncoder,StandardScaler。
算法本身很简单,之前也有文章做过算法的解读,有兴趣的同学请移步:
机器学习算法Python实现--线性回归分析
很早之前还用R做过一个R语言教程之-线性回归
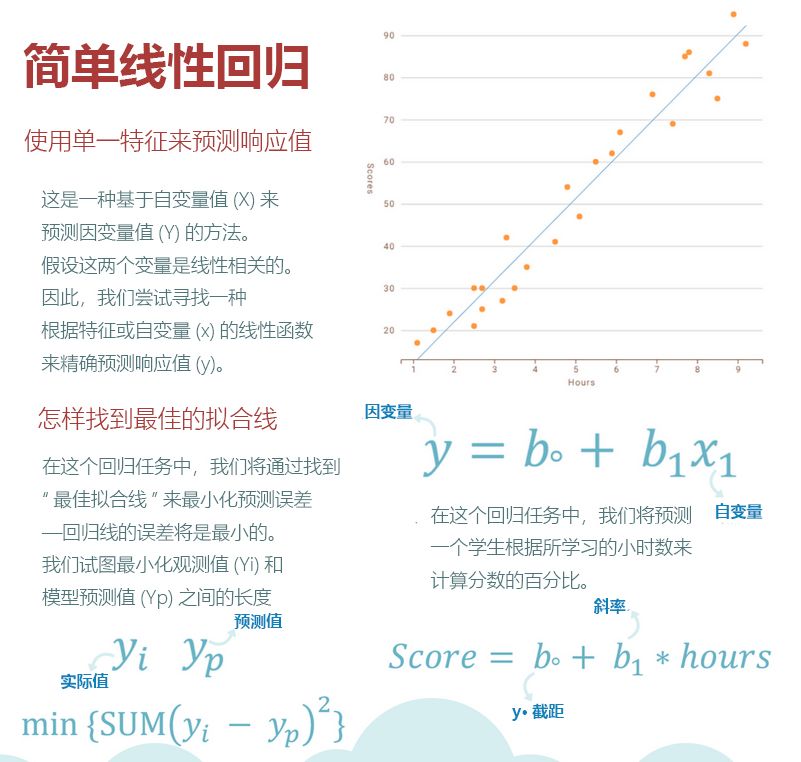
下面开始,四步搞定简单线性回归分析
第一步:数据预处理

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[ : , : 1 ].values
Y = dataset.iloc[ : , 1 ].values
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4, random_state = 0)
第二步:训练集使用简单线性回归模型来训练

from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train)
sklearn是机器学习的神器,之前有过介绍
Sklearn包含的常用算法
LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)
fit_intercept:是否计算截距。
normalize: 当fit_intercept设置为False时,该参数将被忽略。 如果为真,则回归前的回归系数X将通过减去平均值并除以l2-范数而归一化。
copy_X:布尔数,可选,默认为真,如果为真,X会被拷贝,反之,会被覆盖。
n_jobs:指定线程数
第三步:预测结果

LinearRegression官网有具体用法,比较简单,不想移步的同学只需知道下面几个用法即可
fit(X,y,sample_weight=None):X,y以矩阵的方式传入,而sample_weight则是每条测试数据的权重,同样以array格式传入。
predict(X):预测方法,将返回预测值y_pred
score(X,y,sample_weight=None):评分函数,将返回一个小于1的得分,可能会小于0
Y_pred = regressor.predict(X_test)
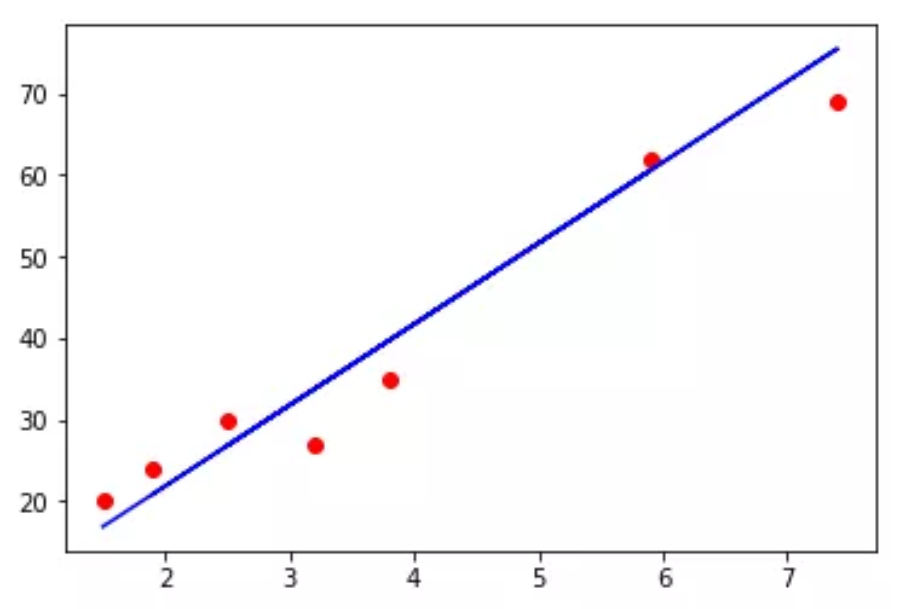
第四步:可视化

训练集结果可视化
plt.scatter(X_train , Y_train, color = 'red')
plt.plot(X_train , regressor.predict(X_train), color ='blue')
plt.show()
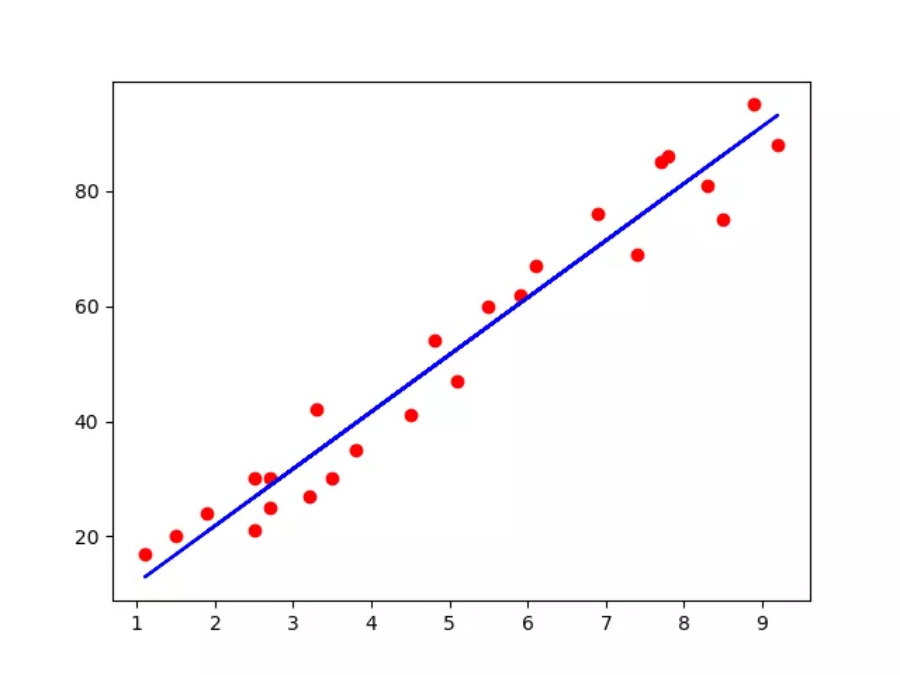
测试集结果可视化
plt.scatter(X_test , Y_test, color = 'red')
plt.plot(X_test , regressor.predict(X_test), color ='blue')
plt.show()