前置知识:
分段的概念(当然手写过肯定是坠吼的
为什么要分页
当我们写程序的时候,总是倾向于把一个完整的程序分成最基本的数据段,代码段,栈段。并且普通的分段机制就是在进程所属的LDT中把每一个段给标识出来。但是在实际运用中,大多数进程不会无限地运行下去。当进程结束之后它占有的内存空间也会被释放。但是这样就会出现一个问题:内存碎片导致的内存使用效率低下
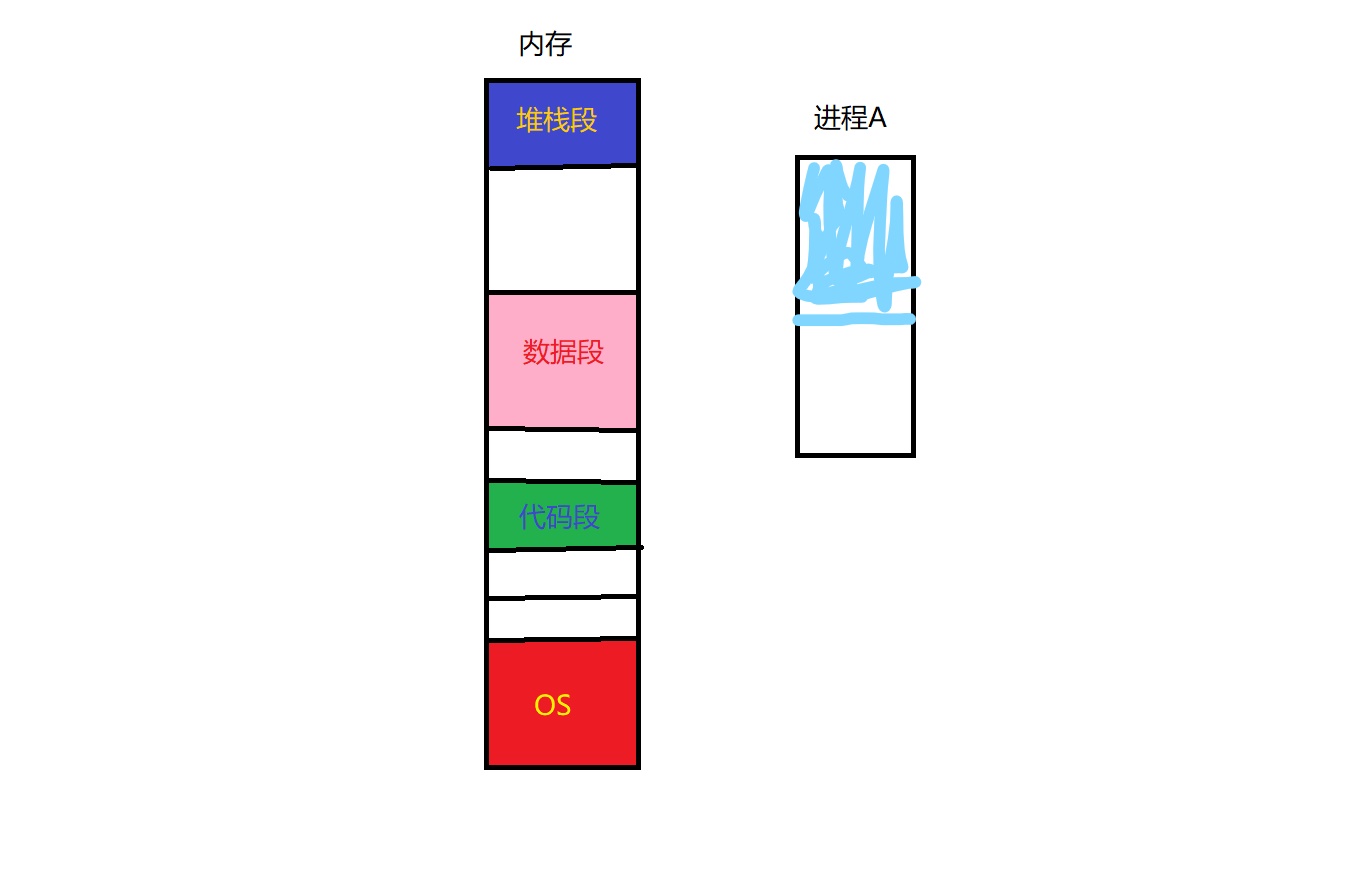
当进程A准备载入内存的时候,实际上内存的总剩余空间是足够放下的。但是进程A中的蓝色段无法直接放入内存中(假设这一段是代码段)。也就是说我们必须等待内存中的进程被释放的时候才能载入进程A。很明显,等待的工作是非常令人厌烦的,所以我们必须得想出一种办法可以避免这种等待。
分页基本思想
其实我们可以类比分段的思想——分段其实是站在程序员的角度来解读程序:代码段,数据段,堆栈段等等等等,每一个段都不定长,但是都有着很明显的用途。分段其实是站在操作系统的角度来看程序:我们直接把程序分成一个个固定长度的页,同时也把物理内存也分成同等大小的页,然后通过一个进程内部的表来把页和页映射起来。这种映射并不保证在物理内存上,页和页是连续的。但是会保证在程序的角度的内存,也就是虚拟内存上是连续的。通过一个表把连续的虚拟内存映射到不连续的物理内存上去来解决上面的问题。就像这样:
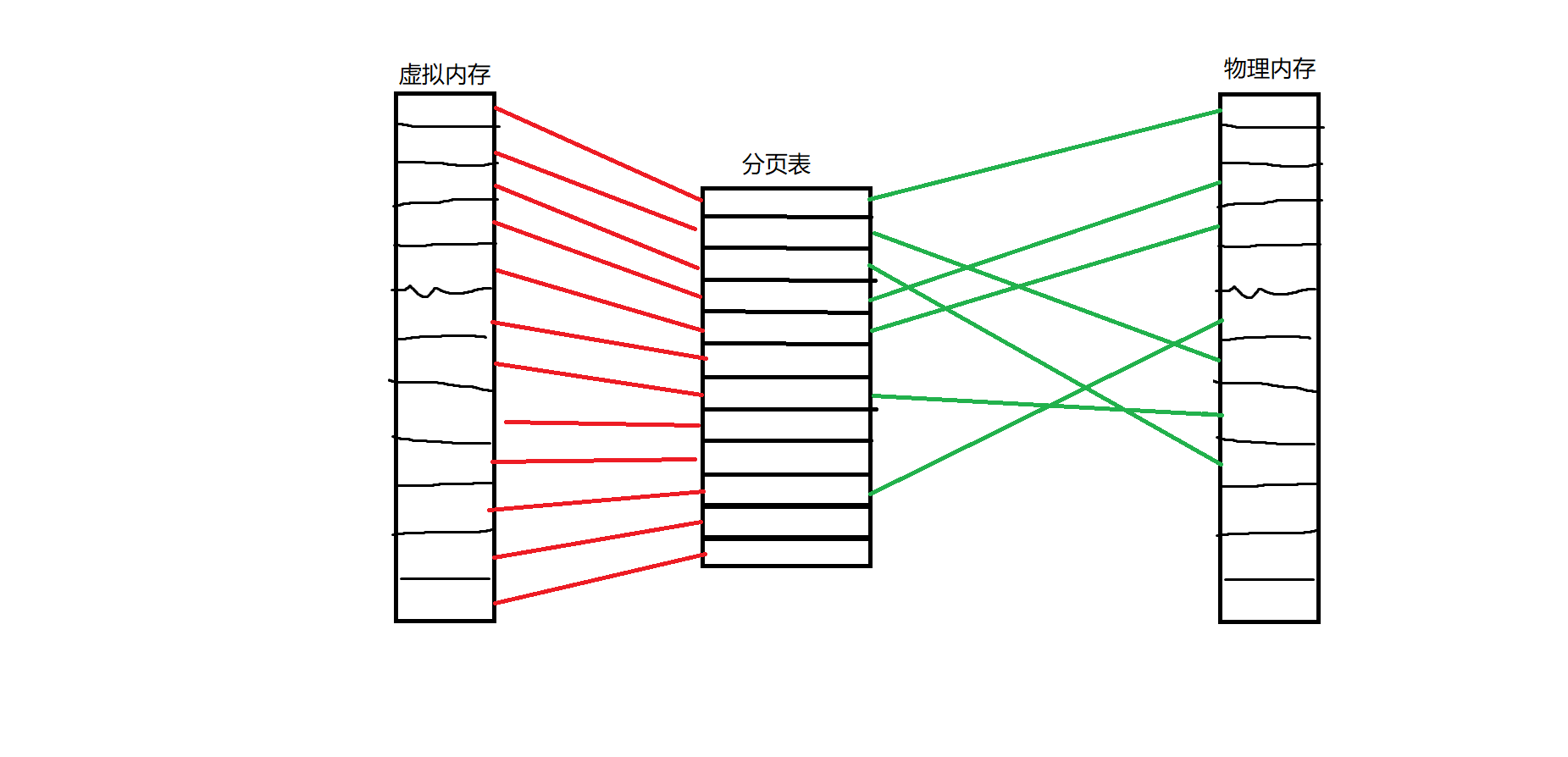
特别地,我们称在虚拟内存页面中每一个页叫做“页面”,物理内存中每一个也叫做“页框”。程序在执行的时候通常只会提供虚拟内存地址,然后cpu通过MMU(内存管理单元)来实现从虚拟地址到物理地址的映射查询。程序对这个过程完全不知道,程序只知道自己给出了一个地址,cpu返回了地址上的值。
打个比方
程序需要访问8745的虚拟内存地址,8745=2 * 4096+553,假设分页表里面2号页面对应着13号页框。cpu会访问13号页框下的553偏移处的数据,也就是13 * 4096+553=53801处的内存。每一个进程都会保留一个分页表,也就是说对于一开始的例子,我们只用把这些零散的内存映射到连续的虚拟内存中去就好了。
页的大小通常为4k,也就是4096个字节。
但是此时又会有一个问题,就是我们存储页表本身所占据的空间会被拉大。假设每一个进程所附带的页表中页的数量为1M,并且每一页的大小为4k,也就是说一个进程会使用大概4M的空间用来寻址。一半类似于windows的大型操作系统在初始化的时候会同时加载50多个进程,也就是说光用来寻址的内存占用就有大概200M。这个开销还是比较大的,所以我们通过使用二级页表来缩小这种内存上的开销。
层次化的分页结构
这里我需要把上面所说到了"页表"的概念拆开成两个东西——"页目录表"和"页表"。32位操作系统可以访问的内存有4GB,也就是1024 * 1024 * 4k,也就是说对应着1024 * 1024个页表。我们还是每1024页分一个页表,然后通过一个新的特殊页表(叫做页目录)来存放这些页表的基址(页目录的基址存放在cr3寄存器中,并且每一个进程都有一个自己的页目录)。
表面上来看这样并不会节省空间,但是实际上每一个进程只用保证页目录表在物理内存中就好了,页表可以在后续操作中分配,也就是说不用一次性存储所有的页表。
可以把页目录表看成页表的索引,或者类似于二级指针的东西。
对于一个32位地址,如果我们采取二级页表的方式寻址,则其寻址规则是这样的:
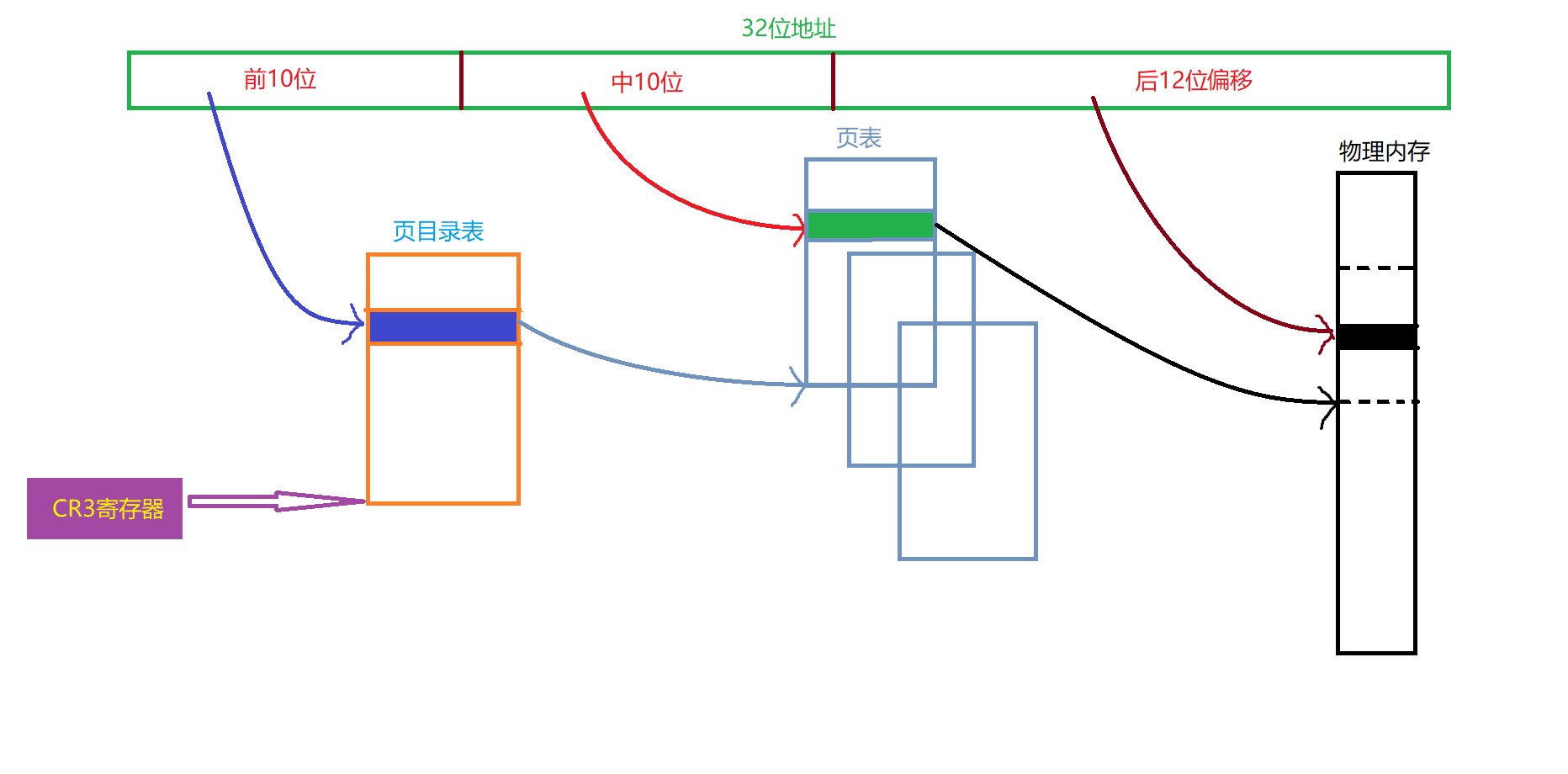
CR3存储的是页目录表的基地址,地址前10位存储的是页目录表内的偏移(具体指向了某一个页表的基地址),中10位存储的是页表内的偏移,通过访问具体的页表项得到物理内存中某一个页框的基地址,然后最后12位用来存储基址向上的偏移。这个过程相信通过图片已经可以很清晰地看出来了,这里就不再多说了。
页表项的构成
其实页表中的页表项并不是完全只存储页框基地址的,在里面还会存储页框的属性。
保护位
顾名思义,保护位就是代表着某个表项允许什么类型的访问,最简单的就是读或者写(0是只读,1是读写),再就是是否可执行。一个保护位一般有2bit。
修改位 & 访问位
这一位在计算机对某一个页面进行访问/修改的时候会发生变化,它们主要被用来为内存换入/换出算法提供一个参考。
禁止高速缓存位
当内存中的某些页面被映射到IO设备,并且系统正在等待着IO设备响应时,这些页面不能被加载到高速缓存中去,否则系统访问的就是一个旧的,在高速缓存中的副本而不是源源不断地从设备处获取数据。
开启分页功能(代码来自《Orange's 一个操作系统的实现》):
PageDirBase equ 200000h ; 页目录开始地址: 2M
PageTblBase equ 201000h ; 页表开始地址: 2M+4K
LABEL_DESC_PAGE_DIR: Descriptor PageDirBase, 4095, DA_DRW;Page Directory
LABEL_DESC_PAGE_TBL: Descriptor PageTblBase, 1023, DA_DRW|DA_LIMIT_4K;Page Tables
SelectorPageDir equ LABEL_DESC_PAGE_DIR - LABEL_GDT
SelectorPageTbl equ LABEL_DESC_PAGE_TBL - LABEL_GDT
SetupPaging:
; 为简化处理, 所有线性地址对应相等的物理地址.
; 首先初始化页目录
mov ax, SelectorPageDir ; 此段首地址为 PageDirBase
mov es, ax
mov ecx, 1024 ; 共 1K 个表项
xor edi, edi
xor eax, eax
mov eax, PageTblBase | PG_P | PG_USU | PG_RWW
.1:
stosd
add eax, 4096 ; 为了简化, 所有页表在内存中是连续的.
loop .1
; 再初始化所有页表 (1K 个, 4M 内存空间)
mov ax, SelectorPageTbl ; 此段首地址为 PageTblBase
mov es, ax
mov ecx, 1024 * 1024 ; 共 1M 个页表项, 也即有 1M 个页
xor edi, edi
xor eax, eax
mov eax, PG_P | PG_USU | PG_RWW
.2:
stosd
add eax, 4096 ; 每一页指向 4K 的空间
loop .2
mov eax, PageDirBase
mov cr3, eax
mov eax, cr0
or eax, 80000000h
mov cr0, eax
jmp short .3
.3:
nop
ret
除了一开始初始化了段和段选择子(用作正常的内存访问),其实就是初始化了页目录表和页表,同时用页目录表基址填充cr3寄存器。这里为了方便起见,页目录表和页表的位置都是连续的(毕竟只是一个demo)。