进程的切换和系统
《庖丁解牛》第八章书本知识总结
- 进程调度的时机都与中断相关,中断是程序执行过程中的强制性转移,转移到操作系统内核相应的处理程序。
- 软中断也叫异常,分为故障、退出和陷阱(自陷)。
- 进程调度时机
进程调度时机就是内核调用schedule函数的时机。在内核即将返回用户空间时,内核会检查
need_resched标记是否设置,如果设置,则调用schedule函数,此时是从中断处理程序返回用户空间的时间点作为一个固定的调度时机点。
1、中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule,或者返回用户态时根据need_resched标记调用schedule,总的来说是中断处理程序主动调用schedule函数让出CPU。
2、内核线程主动调用schedule函数让出CPU,进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度。
3、用户态进程只能被动调度,无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。已经包含在1中。
- 调度策略与算法
Linux系统的进程是根据优先级来排序的,而优先级是动态变化的。
内核中根据进程的优先级来区分普通进程与实时进程,Linux内核进程优先级为0~139,数值越高,优先级越低,0为最高优先级。
实时进程的优先级取值为0~99。
普通进程只有nice值,nice值映射到优先级为100~139。
子进程会继承父进程的优先级。
实时进程的优先级是静态设定的,而且始终大于普通进程的优先级,因此只有当就绪队列中没有实时进程的情况下,普通进程才能够获得调度。
同一个进程在本身优先级不变的情况下分到的CPU时间占比会根据系统负载变化而发生变化,即与时间片没有一个固定的对应关系。
- 实时进程的优先级基本的调度策略如下:
#define SCHED_NORMAL 0 //普通进程 #define SCHED_FIFO 1 //实时进程的先进先出 #define SCHED_RR 2 //实时进程的时间片轮转 #define SCHED_BATCH 3 //保留,未实现 #define SCHED_IDLE 5 //idle进程
- 为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换、任务切换或上下文切换。
在实际代码中,每个进程切换基本由两个步骤组成:切换页全局目录(CR3)以安装一个新的地址空间,切换内核态对战和硬件上下文。 - 进程上下文包含了进程执行需要的所有信息,包括:
- 用户地址空间:包括程序代码、数据、用户堆栈等。
- 控制信息:进程描述符,内核堆栈等。
- 硬件上下文,相关寄存器的值。
- 挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是用户态和内核态的相互转换,而切换进程需要在不同的进程之间切换。
- Linux系统的一般执行过程(正在运行的用户态进程X切换到运行用户态进程Y的过程)
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成:①save cs:eip/ss:esp/eflag:当前CPU上下文压入用户态进程X的内核堆栈。②load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack):加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
- SAVE_ALL,保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态。
- 中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
- 标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过,因此可以从标号1继续执行)
- restore_all ,恢复现场
- iret - pop cs:eip/ss:esp/eflags,从Y进程的内核堆栈中弹出第2步中硬件完成的压栈内容,此时完成了中断上下文的切换,即从进程Y的内核态返回到进程Y的用户态。
- 继续运行用户态进程Y
- 几种特殊情况
- 通过中断处理过程中的调度时机,内核线程之间互相切换,与最一般的情况非常类似,只是内核线程在运行过程中发生中断,没有进程用户态和内核态的转换。
- 用户进程向内核线程的切换,省略了恢复现场和iret恢复CPU上下文。
- 内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略。
- 创建子进程的系统调用在子进程中的执行起点及返回用户态的过程,如fork。
- 加载一个新的可执行程序后返回到用户态的情况,如execve。
- Linux操作系统的整体构架示意图

实验:使用cgdb跟踪分析进程调度相关源代码
- 按照课本配置运行MenuOS系统,跟上次一样修改Makefile以在自己机器上自动运行

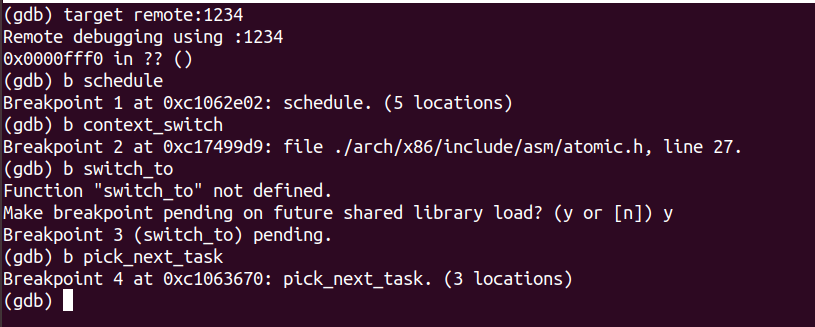
- 设置断点,其中
switch_to是宏定义,无法添加
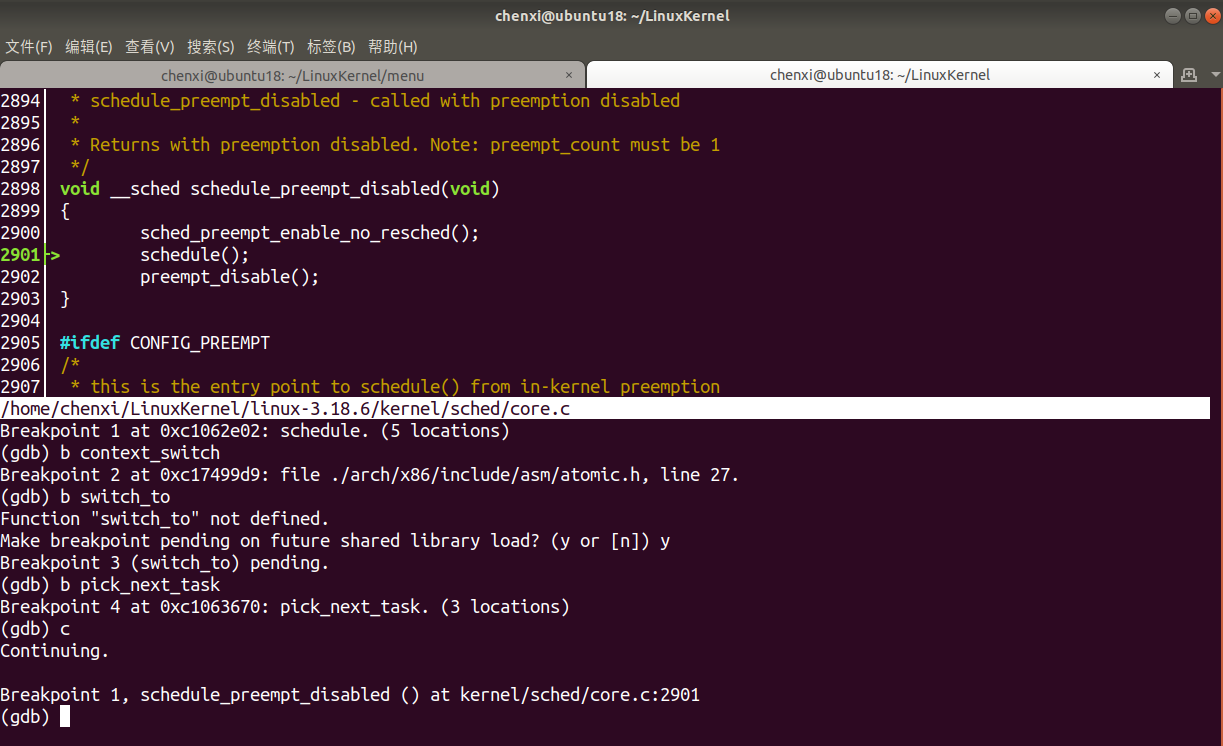
- 运行到
schedule函数断点,调用了schedule,说明进行了进程调度
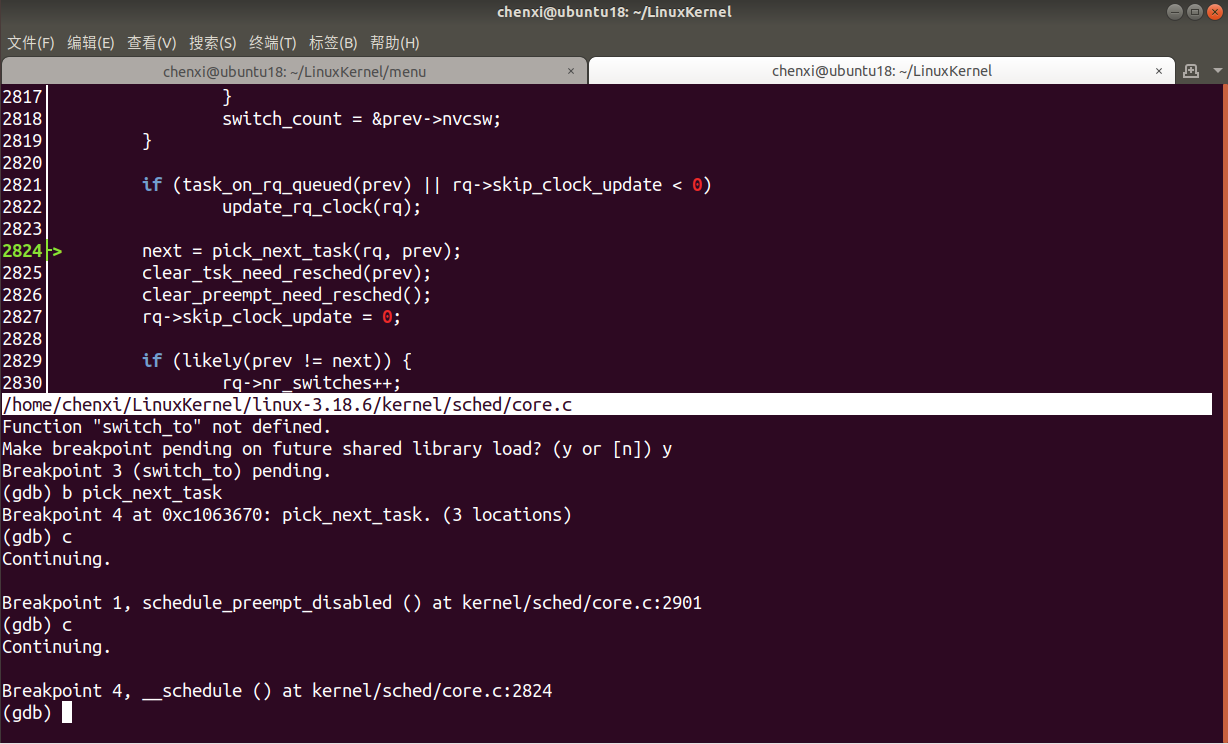
- 继续运行到
pick_next_task
- 继续运行到
context_switch

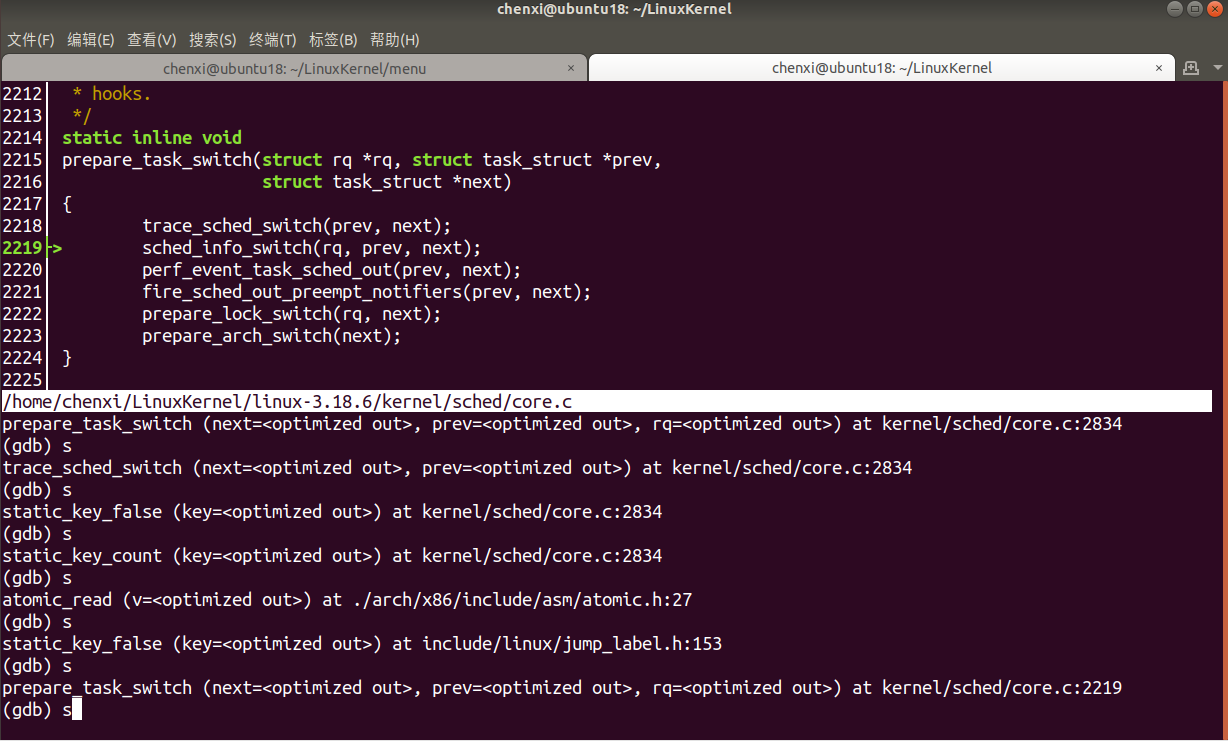
- 单步走并进入
context_switch函数,执行到task_switch函数中调用的prepare_task_switch函数
- 继续单步,
switch_mm
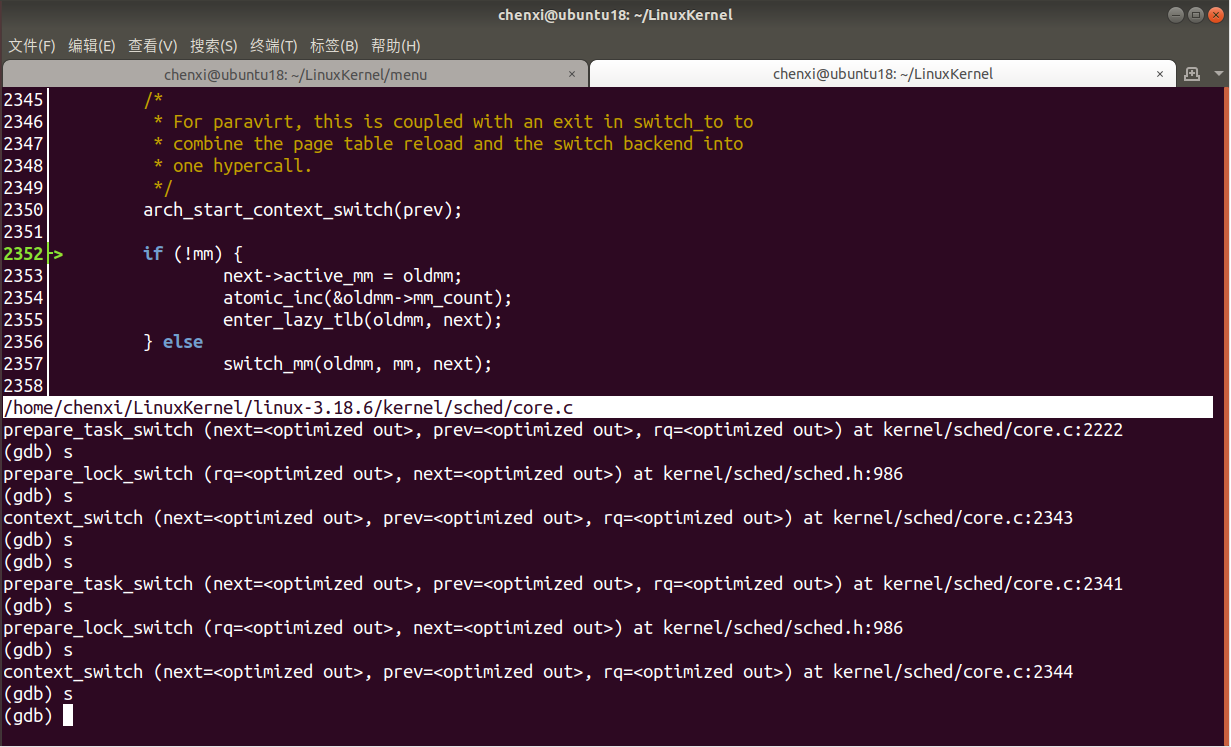
- 继续单步,开始调用
switch_to
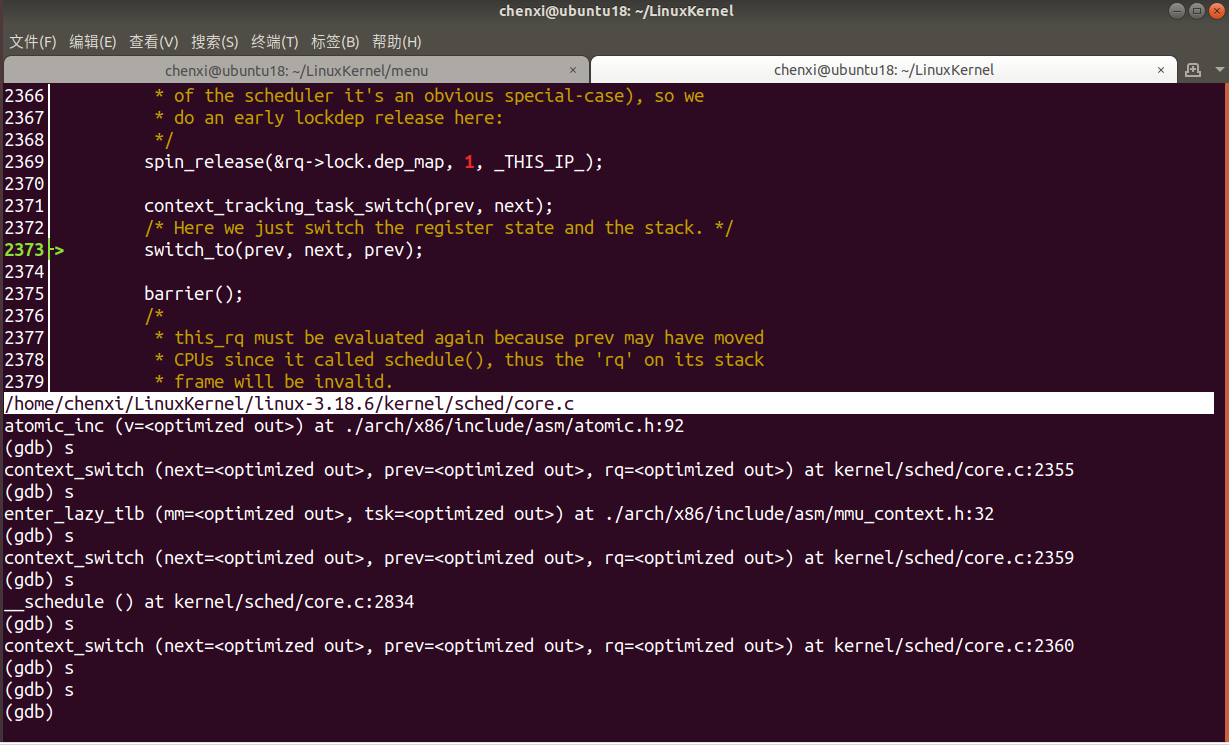
- 进入
switch_to函数内部
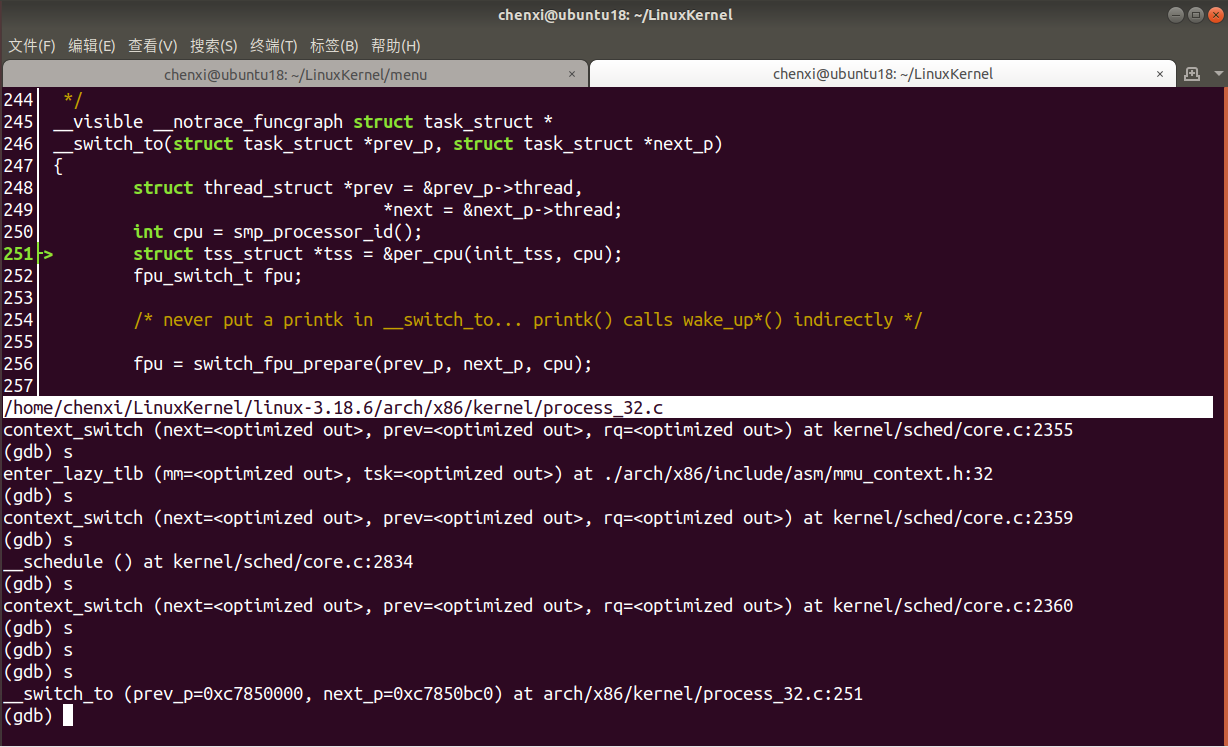
- 结束切换

- 中断结束,根据
need_resched判断是否需要调度
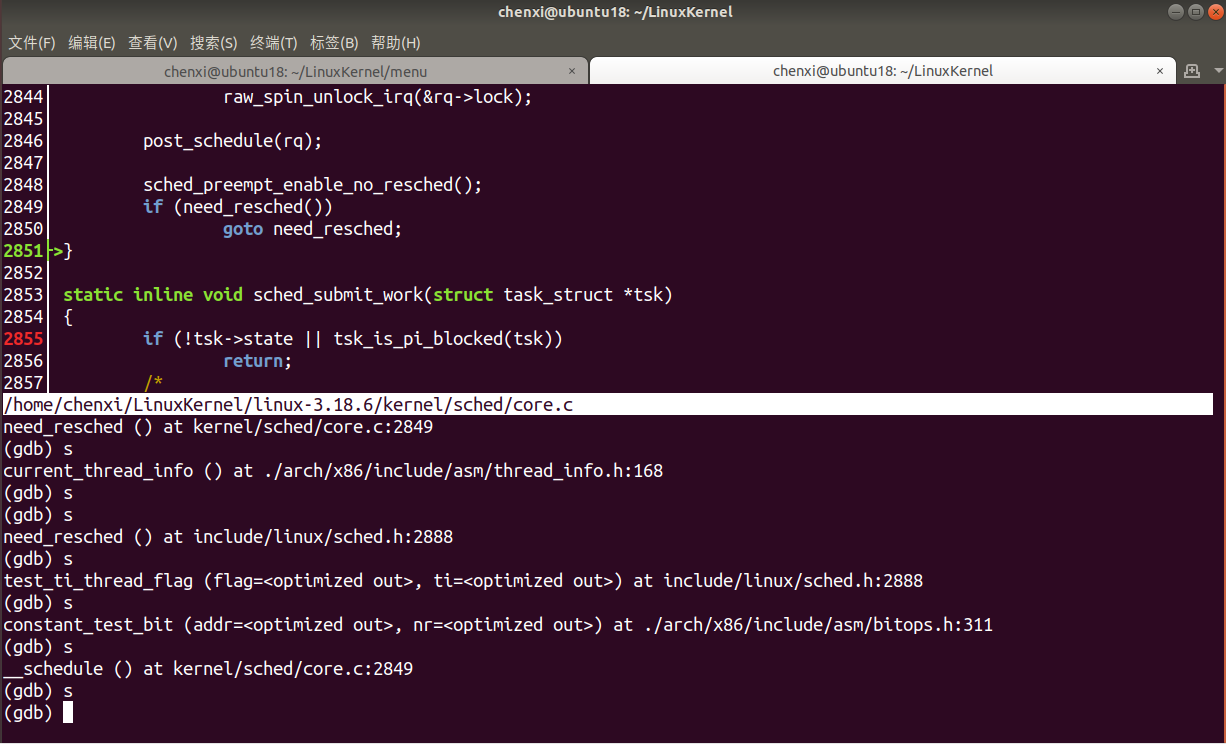
代码分析
context_switch代码
schedule函数选择一个新的进程来运行,并调用context_switch函数进行上下文的切换。
static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) { //如果被切换进来的进程的mm为空切换,内核线程mm为空
next->active_mm = oldmm; //将共享切换出去的进程的active_mm
atomic_inc(&oldmm->mm_count); //有一个进程共享,所有引用计数加一
enter_lazy_tlb(oldmm, next); //普通mm不为空,则调用switch_mm切换地址空间
} else
switch_mm(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
context_tracking_task_switch(prev, next);
// Here we just switch the register state and the stack.切换寄存器状态和栈
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}
switch_to代码
context_switch函数调用switch_to函数进行硬件上下文的切换,该函数为内联汇编代码
#define switch_to(prev, next, last)
do {
/*
* Context-switching clobbers all registers, so we clobber
* them explicitly, via unused output variables.
* (EAX and EBP is not listed because EBP is saved/restored
* explicitly for wchan access and EAX is the return value of
* __switch_to())
*/
unsigned long ebx, ecx, edx, esi, edi;
asm volatile(
"pushfl
" // 保存当前进程flags
"pushl %%ebp
" // 当前进程堆栈基址压栈
"movl %%esp,%[prev_sp]
" // 保存ESP,将当前堆栈栈顶保存起来
"movl %[next_sp],%%esp
" // 更新ESP,将下一栈顶保存到ESP中
// 完成内核堆栈的切换
"movl $1f,%[prev_ip]
" // 保存当前进程的EIP
"pushl %[next_ip]
" // 将next进程起点压入堆栈,即next进程的栈顶为起点,next_ip一般为$1f,对于新创建的子进程是ret_from_fork
__switch_canary
"jmp __switch_to
" // prve进程中,设置next进程堆栈,jmp与call不同,是通过寄存器传递参数(call通过堆栈),所以ret时弹出的是之前压入栈顶的next进程起点
// 完成EIP的切换
"1: " // next进程开始执行
"popl %%ebp
" // restore EBP
"popfl
" // restore flags
// 输出量
: [prev_sp] "=m" (prev->thread.sp), // 保存当前进程的esp
[prev_ip] "=m" (prev->thread.ip), // 保存当前进仓的eip
"=a" (last),
// 要破坏的寄存器
"=b" (ebx), "=c" (ecx), "=d" (edx),
"=S" (esi), "=D" (edi)
__switch_canary_oparam
// 输入量
: [next_sp] "m" (next->thread.sp), // next进程的内核堆栈栈顶地址,即esp
[next_ip] "m" (next->thread.ip), // next进程的eip
// regparm parameters for __switch_to():
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: // 重新加载段寄存器
"memory");
} while (0)
问题
- 书中所列
context_switch代码中,为if (unlikely(!mm)),但是网上的代码中并没有unlikely。
likely和unlikely都是宏定义:
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)
简单从表面上看if(likely(value)) == if(value),if(unlikely(value)) == if(value)。 也就是likely和unlikely是一样的,但是实际上执行是不同的,加likely的意思是value的值为真的可能性更大一些,那么执行if的机会大,而unlikely表示value的值为假的可能性大一些,执行else机会大一些。 加上这种修饰,编译成二进制代码时likely使得if后面的执行语句紧跟着前面的程序,unlikely使得else后面的语句紧跟着前面的程序,这样就会被cache预读取,增加程序的执行速度。
而使用!!的原因是计算机中bool逻辑只有0和1,非0即是1,当likely(x)中参数不是逻辑值时,就可以使用!!符号转化为逻辑值1或0 。比如:!!(3)=!(!(3))=!0=1,这样就把参数3转化为逻辑1了。 也不难理解为何要使用if (!mm),也是为了将判断值转换为逻辑0或1。 - 使用
jmp __switch_to的原因。
使用jmp是使用寄存器传递参数的,所以不会将下一条指令push到堆栈中,ret返回时会弹出之前压入栈顶的next进程的起点,即nexp_ip。 如果用call,就会将下一条指令1: 压栈,返回时会弹出标号1的位置。如果新的进程是刚创建的,则next_ip不是1:,而是ret_from_fork,就会出现问题。
总结
本章学习了Linux进程的切换和系统的一般执行过程,通过对代码过程的分析,理解了Linux系统中进行系统切换的步骤,区分了中断和进程切换,也了解到了Linux所支持的调度策略,与之前学习的操作系统课程的进程调度相结合,加深了理解。也观察了Linux系统的运行过程,明白了一般地执行过程和一些特殊情况,对前几章的知识也有一定的巩固深化作用。