1. 计数器表
案例:网站访问数记录
正常一张表一个字段就可以解决这个问题。
create table tcount (cnt int) ;
通过左边语句更新:
update tcount set cnt = cnt+1 ;
当大型网站并发量很大的时候,这个更新是低效的。因为update操作需要获取写锁。
优化如下:
创建一张表:
create table tcount (cnt int,id int primary key) ;
先写入100条数据, id 从1-100. cnt 都为零。
然后随机更新:
update tcount set cnt = cnt+1 where id = ROUND(rand()*100) ;
最后统计:
select count(cnt) from tcount;
这样做,很好的避免了每次更新都需要拿行锁的问题(效率自然就高了)。
2. 伪哈希索引
create table turl(url varchar(100), url_crc varchar(32));
为了测试插入数据:
insert into turl(url,url_crc) values('https://www.cnblogs.com/jssj/',CRC32('https://www.cnblogs.com/jssj/')); insert into turl(url,url_crc) values('https://spring.io/',CRC32('https://spring.io/')); insert into turl(url,url_crc) values('http://www.sikiedu.com/',CRC32('http://www.sikiedu.com/')); insert into turl(url,url_crc) values('http://seventhicecastle.com/',CRC32('http://seventhicecastle.com/'));
索引改成建立在url_crc字段上:
查询SQL:
select * from turl where url_crc = CRC32('https://www.cnblogs.com/jssj/') and url = 'https://www.cnblogs.com/jssj/';
因为CRC32 属于摘要信息,存在url不同却crc32后的摘要相同的情况,所以还需要加上url的条件。因为索引在url_crc上,执行效率非常高的。
摘要信息详情参考:https://www.cnblogs.com/jssj/p/12001431.html
3. 前缀索引
创建前缀索引:
alter table turl add key(url(7));
列值比较长的时候,因为整列作为索引太浪费索引空间。
4. 重新整理数据空间。
optimize table cop_ttransferflow;
查询表的索引信息
show index from XXXX; -- XXXX 表名
5. like SQL优化,准备一张百万数据量的表(ic_website)
select t.* from ic_website t where t.url like '%72511%' ;
第一次执行花费9S.
select * from ic_website t1 INNER JOIN (select t.id,t.url from ic_website t where t.url like '%72511%' ) t2 on t1.id = t2.id ;
改写之后:第一次执行时间花费0.9S
6. 创建索引技巧
alter table t add index index2(sex,username); -- 创建这样一个索引,大家都会觉得使用username的时候无法走索引,但是,其实可以有一个小技巧
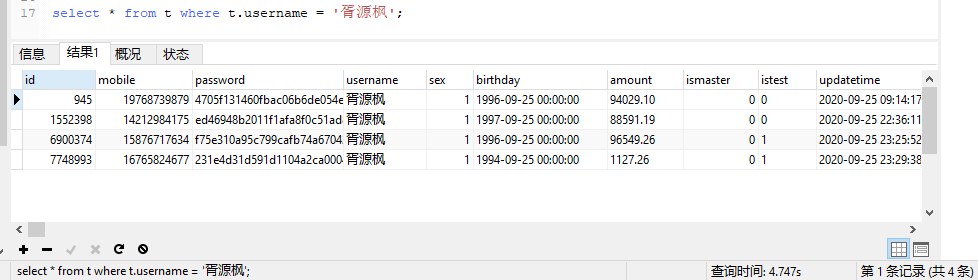
可以使用一个小技巧。
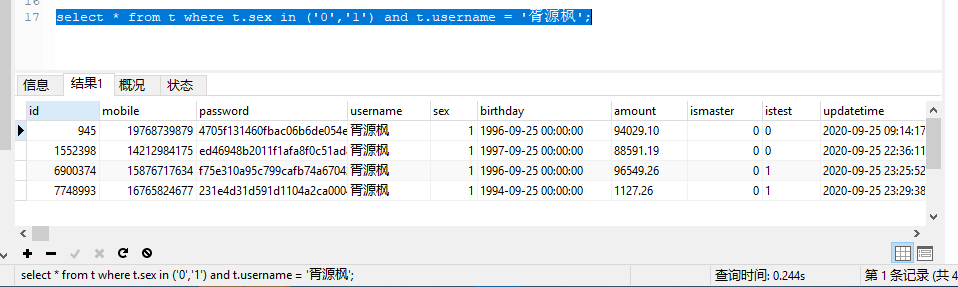
运行效率提高20倍。
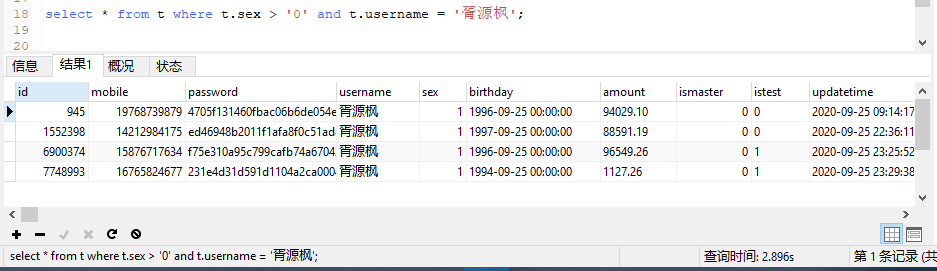
范围查询到导致,后面字段都无法使用索引,范围查询字段需要放索引最后面,例如日期。
7. order by 字段如果不在索引里面也会很慢,可以加索引看结果。
8. limit分页优化
select * from t where t.sex = '0' order by t.username LIMIT 10 ;
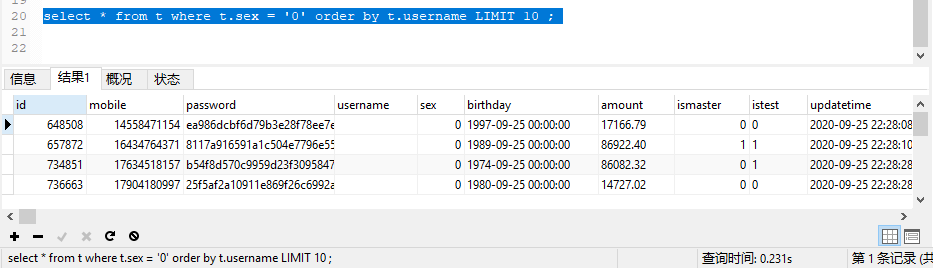
select * from t where t.sex = '0' order by t.username LIMIT 1000000, 10 ;
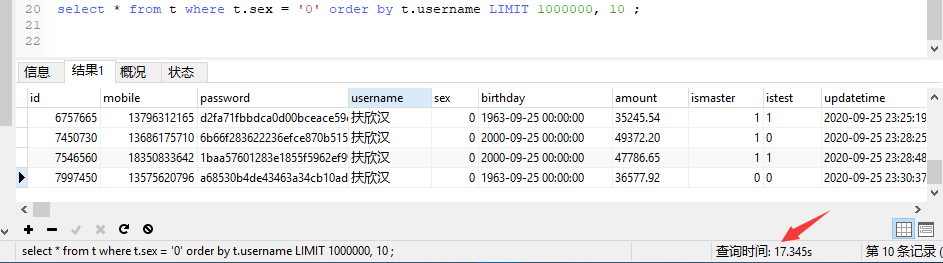
分页取越后面会越慢。
limit优化前:
select * from t where t.sex = '0' order by t.id LIMIT 1000000, 10 ;
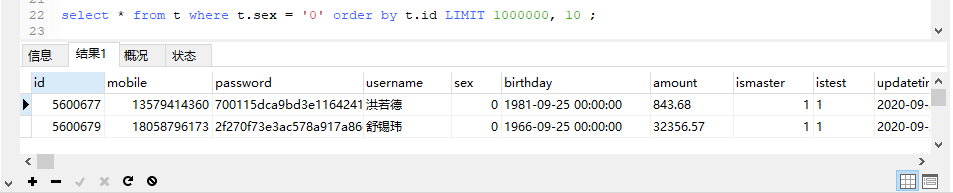
优化后:
select * from t where t.sex = '0' and t.id > 5600677 order by t.id LIMIT 10 ;

9. 分解关联查询
优化前:
SELECT * FROM tuser t, trole t1, tcompany t2 WHERE t.role_id = t1.role_id AND t1.company_id = t2.company_id and t.user_age = 33;
优化后:
SELECT * FROM tuser t where t.user_age = 33; SELECT * FROM trole t where t.role_id = 9; select * from tcompany t where t.company_id in (1,2);
优化的好处有:
1. 让MYSQL缓存可以更好的利用。
2. 减少锁表的情况。
3. 查询简化,减少笛卡尔积。