http://www.cnblogs.com/luxiaoxun/archive/2012/09/12/2681268.html
http://blog.csdn.net/wangkechuang/article/details/7906540
一、归并
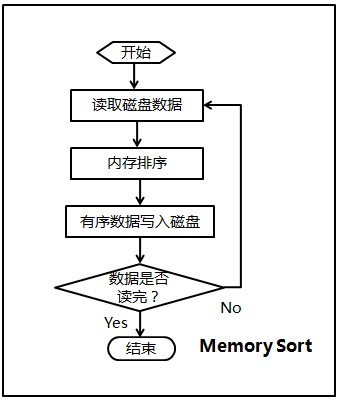
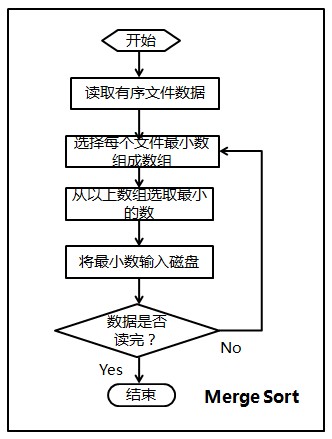
1、内排序
由于要求的可用内存为1MB,那么每次可以在内存中对250K的数据进行排序,然后将有序的数写入硬盘。
那么10M的数据需要循环40次,最终产生40个有序的文件。
2、多路归并排序
(1)将每个文件最开始的数读入(由于有序,所以为该文件最小数),存放在一个大小为40的first_data数组中;
(2)选择first_data数组中最小的数min_data,及其对应的文件索引index;
(3)将first_data数组中最小的数写入文件result,然后更新数组first_data(根据index读取该文件下一个数代替min_data);
(4)判断是否所有数据都读取完毕,否则返回(2)。
二、位图
位图方案。例如正如《编程珠玑》一书上所述,用一个20位长的位字符串来表示一个所有元素都小于20的简单的非负整数集合,边框用如下字符串来表示集合{1,2,3,5,8,13}:
0 1 1 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0
上述集合中各数对应的位置则置1,没有对应的数的位置则置0。
参考《编程珠玑》一书上的位图方案,针对10^7个数据量的磁盘文件排序问题,可以这么考虑,由于每个7位十进制整数表示一个小于1000万的整数。可以使用一个具有1000万个位的字符串来表示这个文件,其中,当且仅当整数i在文件中存在时,第i位为1。采取这个位图的方案是因为我们面对的这个问题的特殊性:1、输入数据限制在相对较小的范围内,2、数据没有重复,3、其中的每条记录都是单一的正整数,没有任何其它与之关联的数据。
所以,此问题用位图的方案分为以下三步进行解决:
第一步,将所有的位都置为0,从而将集合初始化为空。
第二步,通过读入文件中的每个整数来建立集合,将每个对应的位都置为1。
第三步,检验每一位,如果该位为1,就输出对应的整数。