google最近新开放出word2vec项目,该项目使用deep-learning技术将term表示为向量,由此计算term之间的相似度,对term聚类等,该项目也支持phrase的自动识别,以及与term等同的计算。
word2vec(word to vector)顾名思义,这是一个将单词转换成向量形式的工具。通过转换,可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。
具体的原理还没有去了解,在这里谈一下怎么个应用法
- 分词
1) 本人下载的是搜狗实验室的互联网媒体新闻语料,先从语料中提取出每篇文章的正文,在提取的过程中进行过滤操作,因为同一篇文章可能被多个媒体报道,如果不对文章进行排重的话,会对最终的结果有一些影响,从过滤的结果上看,100篇文章中大概有35篇是出现不止一次的,所以这一步还是挺必要的。
2) 提取出正文后进行分词,且在分词过程中统计词频,因为Word2Vec在运行过程中,占用内存的大小是由独立词的个数决定的,所以统计完词频后将分词后的结果中的低频词去掉,在不去掉的情况下,大概要用到20G的内存空间,而只取前10万个高频词的时候只需要1G的空间就可以了。本人用的是FudanNLP的开源分词软件,分词速度还可以,大概300k/s,在i5-3470,8G内存的平台上进行。不过美中不足的是分词的正确率感觉不大高,很多长词被拆分成短词了,估计是词库的问题。
具体的代码如下:
新闻结构存储
1 package cn.com.juefan.word2vec; 2 3 import java.util.regex.Matcher; 4 import java.util.regex.Pattern; 5 6 public class Word2VecData { 7 8 public String TEXT = new String(); 9 public String urlString = new String(); 10 public String titleString = new String(); 11 public String contentString = new String(); 12 13 public Word2VecData(String string){ 14 TEXT = string; 15 urlString = match("url" ); 16 titleString = match("contenttitle"); 17 contentString = match("content"); 18 19 } 20 21 /** 22 * 匹配提取出内容 23 * @param string 搜狗数据集(一行) 24 * @return 提取的有效内容 25 */ 26 public String match(String string){ 27 String regex = "<" + string + ">" + ".*?" + "</" + string + ">"; 28 Pattern p = Pattern.compile(regex, Pattern.CANON_EQ); 29 Matcher matcher = p.matcher(TEXT); 30 while(matcher.find()){ 31 return matcher.group().replace("<" + string + ">" , "").replace("</" + string + ">", ""); 32 } 33 return null; 34 }45 } 46 47 }
正文提取与存储
1 package cn.com.juefan.word2vec; 2 3 import java.io.BufferedReader; 4 import java.io.File; 5 import java.io.FileInputStream; 6 import java.io.FileReader; 7 import java.io.FileWriter; 8 import java.io.InputStreamReader; 9 import java.util.HashSet; 10 import java.util.Map; 11 import java.util.Scanner; 12 import java.util.Set; 13 14 import edu.fudan.juefan.personer.StopWord; 15 import edu.fudan.ml.types.Dictionary; 16 import edu.fudan.nlp.cn.tag.CWSTagger; 17 import edu.fudan.nlp.cn.tag.POSTagger; 18 19 public class SplitContent { 20 21 /** 22 * 将指定内容写入指定文件中 23 * 以追加的方式写入 24 * @param fileWriter 文件路径 25 * @param context 存储内容 26 * @param bool 是否覆盖写入 27 */ 28 public static void FileWrite(String fileName, String context, boolean bool){ 29 try{ 30 @SuppressWarnings("resource") 31 FileWriter fileWriter = new FileWriter(fileName, bool); 32 fileWriter.write(context); 33 fileWriter.flush(); 34 }catch (Exception e) { 35 } 36 } 37 38 public static void main(String[] args) throws Exception { 39 Set<String> set = new HashSet<String>(); 40 /**加载分词器*/ 41 CWSTagger tag2 = new CWSTagger("./models/seg.m"); 42 String fileNameString = "\output\sogou\SplitContent_"; 43 44 /**加载停用词 45 * 该类是自己写的,个人可以自己写一个,主要是对分词后的结果进行过滤操作 46 */ 47 StopWord stopWord = new StopWord(); 48 int TRAC = 0; 49 int NUM = 0; 50 StringBuilder builder = new StringBuilder(); 51 BufferedReader reader = null; 52 try{ 53 /**读取搜狗语料*/ 54 File fileScanner = new File(System.getProperty("user.dir") + "\input\news_tensite_xml.txt"); 55 56 if(new File(System.getProperty("user.dir") + "\input\news_tensite_xml.txt").exists()){ 57 System.out.println("正在读取文件......"); 58 InputStreamReader isr = new InputStreamReader(new FileInputStream(fileScanner), "GBK"); 59 reader = new BufferedReader(isr); 60 String tmString = null; 61 while((tmString = reader.readLine()) != null){ 62 builder = builder.append(tmString); 63 64 /**搜狗语料的结构为每6行构成一篇报道*/ 65 if(++TRAC % 6 == 0){ 66 Word2VecData data = new Word2VecData(builder.toString()); 67 if(!set.contains(data.contentString)){ 68 /**上面是判断该新闻是否与出现过,下面是将分词后的结果进行停用词过滤操作,且每50000篇文章为一个小文件*/ 69 stopWord.Filtration(tag2.tag(data.contentString)); 70 FileWrite(System.getProperty("user.dir") + fileNameString + Integer.toString(NUM++ / 50000), stopWord.builder.toString() + " ", true); 71 set.add(data.contentString); 72 if(NUM % 10000 == 0) 73 System.out.println(NUM); 74 } 75 builder.delete(0, builder.length()); 76 } 77 } 78 System.out.println("读取文件成功!"); 79 } 80 }catch (Exception e) { 81 System.out.println("文件不存在!"); 82 } 83 } 84 85 }
==================久违了,写一下Word2Vec的操作====================
上面的是语料的分词,接下来就利用分词后的语料进行Word2Vec的训练了
步骤1:
首先要做的肯定是从官网上下载word2vec的源码:http://word2vec.googlecode.com/svn/trunk/ ,然后把其中makefile文件的.txt后缀去掉,在终端下执行make操作,这时能发现word2vec文件夹下多了好几个东西。
如果make不成功的话,需要修改makefile的内容,把第四行修改为
CFLAGS = -lm -pthread -O2 -Wall -funroll-loops
然后再进行make编译,这回估计就能成功了!
步骤2:
对语料进行训练,在Word2Vec文件夹下会有一个word2vec程序,执行
./word2vec sougo.txt vertors.bin
./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1
此时将会训练生成词向量文件vertors.bin
步骤3:
调用vertors.bin文件输出词的相似词结果,执行
[juefan@xxx Word2Vec]$ ./distance vectors.bin
Enter word or sentence (EXIT to break):
此时只要输入一个词,就能够输出对应的相关词了
参数说明:
参数解释:
-train 训练数据
-output 结果输入文件,即每个词的向量
-cbow 是否使用cbow模型,0表示使用skip-gram模型,1表示使用cbow模型,默认情况下是skip-gram模型,cbow模型快一些,skip-gram模型效果好一些
-size 表示输出的词向量维数
-window 为训练的窗口大小,8表示每个词考虑前8个词与后8个词(实际代码中还有一个随机选窗口的过程,窗口大小<=5)
-negative 表示是否使用NEG方,0表示不使用,其它的值目前还不是很清楚
-hs 是否使用HS方法,0表示不使用,1表示使用
-sample 表示 采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样
-binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型

除了上面所讲的参数,还有:
-alpha 表示 学习速率
-min-count 表示设置最低频率,默认为5,如果一个词语在文档中出现的次数小于该阈值,那么该词就会被舍弃
-classes 表示词聚类簇的个数,从相关源码中可以得出该聚类是采用k-means
晒一下结果出来给大家看下。。。
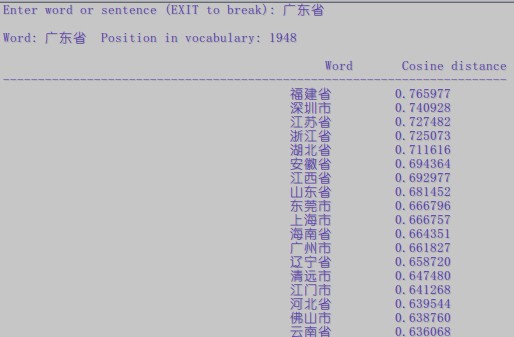
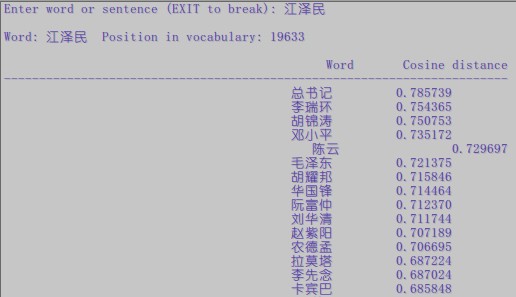
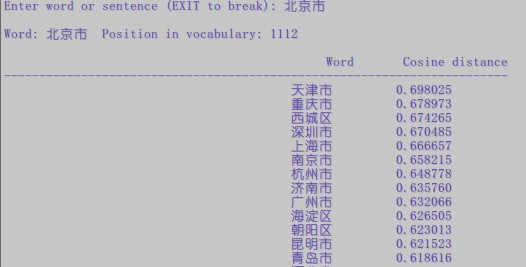
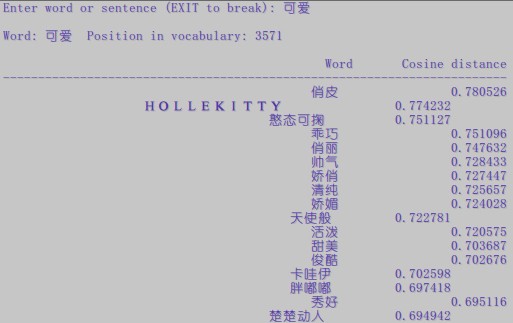
没有做过对比,不过个人感觉这个效果是挺不错的了。。。。点赞!
http://blog.csdn.net/baidu_26550817/article/details/48653889