/*先把标题给写了,这样就能经常提醒自己*/
决策树是一种容易理解的分类算法,它可以认为是if-then规则的一个集合。主要的优点是模型具有可读性,且分类速度较快,不用进行过多的迭代训练之类。决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。比较常用到的算法有ID3、C4.5和CART。
1. 决策树模型
决策树是一种树形结构的分类模型,它由结点和有向边组成,结点分为内部结点和叶结点,内部结点表示一个特征或属性,叶结点表示一个类。
决策树的分类即是从树的根节点开始对实例的某一个特征进行判断,通过内部结点逐步下潜到叶结点的过程。
2. 特征选择
特征选择在于选取对训练数据具有分类能力的特征,通常的选择准则是信息增益或信息增益率。为了便于说明,书中给出了一个例子
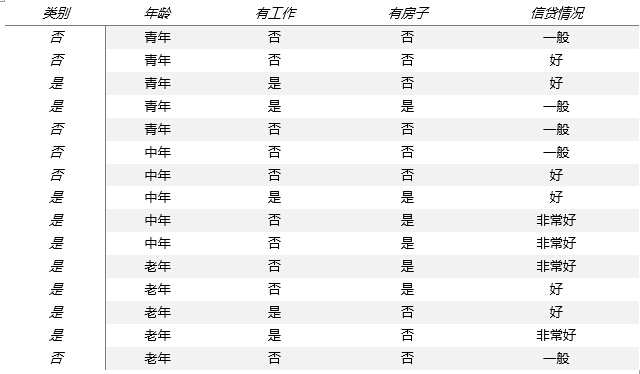
希望通过所给的训练数据学习一个贷款申请的决策树,当新客户提出贷款申请时,根据申请人的特征决定是否可贷。
从认知上个人觉得特征的选择就是找出一些具有代表性,对于分类辨识度高的特征,如此能够快速准确的为实例分类,从数学的角度上来讲,就要涉及到信息论与概率统计中的熵了。在此不赘述太多,直接给出特征选择的算法(信息增益)。
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益![]() 和增益率
和增益率![]()
(1) 计算数据集D的经验熵![]()
![]()
(2) 计算特征A的经验条件熵![]()
![]()
(3) 计算信息增益
![]()
(4) 信息增益率
![]()
对于书中的例子,首先计算经验熵
![]()
然后计算各特征的信息增益,分别以![]() 表示年龄、有工作、有房子和信贷情况4个特征,则
表示年龄、有工作、有房子和信贷情况4个特征,则
![]()
分别计算![]() 的信息增益,由于
的信息增益,由于![]() 的信息增益值最大,则选择其为最优特征,当然也可以计算出信息增益率的结果作为选择的依据。
的信息增益值最大,则选择其为最优特征,当然也可以计算出信息增益率的结果作为选择的依据。
3. 决策树的生成
ID3和C4.5算法基本上一样,只是在特征选择的依据上C4.5采用了改进后的信息增益率。因为本文只介绍其中的ID3算法即可。
ID3算法步骤
输入:训练数据集D,特征集A,阈值e
输出:决策树T
(1) 若D中所有实例属于同一类Ck,则T为单结点树,并将类Ck作为该结点的类标记,返回T;
(2) 若A=空,则T为单结点树,将D中实例数最多的类Ck作为结点类标记,返回T;
(3) 否则,计算A中各特征对D的信息增益,选择信息增益值最大的特征Ag;
(4) 如果Ag的信息增益小于阈值e,则T为单结点树,将D中最多的类Ck作为结点类标记,返回T;
(5) 否则,对Ag的每一可能值ai,依Ag=ai将D分割为若干子集Di,将Di中实例数最大多的类作为类标记,构建子结点,由结点及其子结点构成树T,返回T;
(6) 对于第i个子结点,以Di为训练集,以A-Ag为特征集,递归调用步骤(1)~(5),得到子树Ti,返回Ti。
从描述上感觉决策树的生成还是挺简单明了的,但是具体的实现上树的生成是最最难的,要注意的细节很多,花了俩个晚上才搞好的,遇到了好多坑
代码块1:信息增益类
package org.juefan.decisiontree;
import java.util.ArrayList; import java.util.HashMap; import java.util.Map; import org.juefan.basic.FileIO; import org.juefan.bayes.Data; public class InfoGain { //数据实例存储类 class Data { public ArrayList<Object> x; public Object y; /**读取一行数据转化为标准格式*/ public Data(String content){ String[] strings = content.split(" | |:"); ArrayList<Object> xList = new ArrayList<Object>(); for(int i = 1; i < strings.length; i++){ xList.add(strings[i]); } this.x = new ArrayList<>(); this.x = xList; this.y = strings[0]; } public Data(){ x = new ArrayList<>(); y = 0; } public String toString(){ StringBuilder builder = new StringBuilder(); builder.append("[ "); for(int i = 0; i < x.size() - 1; i++) builder.append(x.get(i).toString()).append(","); builder.append(x.get(x.size() - 1).toString()); builder.append(" ]"); return builder.toString(); } } //返回底数为2的对数值 public static double log2(double d){ return Math.log(d)/Math.log(2); } /** * 计算经验熵 * @param datas 当前数据集,可以为训练数据集中的子集 * @return 返回当前数据集的经验熵 */ public double getEntropy(ArrayList<Data> datas){ int counts = datas.size(); double entropy = 0; Map<Object, Double> map = new HashMap<Object, Double>(); for(Data data: datas){ if(map.containsKey(data.y)){ map.put(data.y, map.get(data.y) + 1); }else { map.put(data.y, 1D); } } for(double v: map.values()) entropy -= (v/counts * log2(v/counts)); return entropy; } /** * 计算条件熵 * @param datas 当前数据集,可以为训练数据集中的子集 * @param feature 待计算的特征位置 * @return 第feature个特征的条件熵 */ public double getCondiEntropy(ArrayList<Data> datas, int feature){ int counts = datas.size(); double condiEntropy = 0; Map<Object, ArrayList<Data>> tmMap = new HashMap<>(); for(Data data: datas){ if(tmMap.containsKey(data.x.get(feature))){ tmMap.get(data.x.get(feature)).add(data); }else { ArrayList<Data> tmDatas = new ArrayList<>(); tmDatas.add(data); tmMap.put(data.x.get(feature), tmDatas); } } for(ArrayList<Data> datas2: tmMap.values()){ condiEntropy += (double)datas2.size()/counts * getEntropy(datas2); } return condiEntropy; } /** * 计算信息增益(ID3算法) * @param datas 当前数据集,可以为训练数据集中的子集 * @param feature 待计算的特征位置 * @return 第feature个特征的信息增益 */ public double getInfoGain(ArrayList<Data> datas, int feature){ return getEntropy(datas) - getCondiEntropy(datas, feature); } /** * 计算信息增益率(C4.5算法) * @param datas 当前数据集,可以为训练数据集中的子集 * @param feature 待计算的特征位置 * @return 第feature个特征的信息增益率 */ public double getInfoGainRatio(ArrayList<Data> datas, int feature){ return getInfoGain(datas, feature)/getEntropy(datas); } }
代码块2:决策树类
package org.juefan.decisiontree;
import java.util.ArrayList; import java.util.List; public class TreeNode { private String feature; //候选特征 private List<TreeNode> childTreeNode; private String targetFunValue; //特征对应的值 private String nodeName; //分类的类别 public TreeNode(String nodeName){ this.nodeName = nodeName; this.childTreeNode = new ArrayList<TreeNode>(); } public TreeNode(){ this.childTreeNode = new ArrayList<TreeNode>(); } public void printTree(){ if(targetFunValue != null) System.out.print("特征值: " + targetFunValue + " "); if(nodeName != null) System.out.print("类型: " + nodeName + " "); System.out.println(); for(TreeNode treeNode: childTreeNode){ System.out.println("当前特征为:" + feature); treeNode.printTree(); } }
public String getAttributeValue() { return feature; } public void setAttributeValue(String attributeValue) { this.feature = attributeValue; } public List<TreeNode> getChildTreeNode() { return childTreeNode; } public void setChildTreeNode(List<TreeNode> childTreeNode) { this.childTreeNode = childTreeNode; } public String getTargetFunValue() { return targetFunValue; } public void setTargetFunValue(String targetFunValue) { this.targetFunValue = targetFunValue; } public String getNodeName() { return nodeName; } public void setNodeName(String nodeName) { this.nodeName = nodeName; } }
代码块3:决策树的生成
package org.juefan.decisiontree; import java.util.ArrayList; import java.util.HashMap; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Set; import org.juefan.basic.FileIO; import org.juefan.bayes.Data; public class DecisionTree { public static final double e = 0.1; public InfoGain infoGain = new InfoGain(); public TreeNode buildTree(ArrayList<Data> datas, ArrayList<String> featureName){ TreeNode treeNode = new TreeNode(); ArrayList<String> feaName = new ArrayList<>(); feaName = featureName; if(isSingle(datas) || getMaxInfoGain(datas) < e){ treeNode.setNodeName(getLabel(datas).toString()); return treeNode; }else { int feature = getMaxInfoGainFeature(datas); treeNode.setAttributeValue(feaName.get(feature + 1)); ArrayList<String> tList = new ArrayList<>(); tList = feaName; Map<Object, ArrayList<Data>> tMap = new HashMap<>(); for(Data data: datas){ if(tMap.containsKey(data.x.get(feature))){ Data tData = new Data(); for(int i = 0; i < data.x.size(); i++) if(i != feature) tData.x.add(data.x.get(i)); tData.y = data.y; tMap.get(data.x.get(feature)).add(tData); }else { Data tData = new Data(); for(int i = 0; i < data.x.size(); i++) if(i != feature) tData.x.add(data.x.get(i)); tData.y = data.y; ArrayList<Data> tDatas = new ArrayList<>(); tDatas.add(tData); tMap.put(data.x.get(feature),tDatas); } } List<TreeNode> treeNodes = new ArrayList<>(); int child = 0; for(Object key: tMap.keySet()){ //这一步太坑爹了,java的拷背坑真多啊,害我浪费了半天的时间 ArrayList<String> tList2 = new ArrayList<>(tList); tList2.remove(feature + 1); treeNodes.add(buildTree(tMap.get(key), tList2)); treeNodes.get(child ++).setTargetFunValue(key.toString()); } treeNode.setChildTreeNode(treeNodes); feaName.remove(feature + 1); } return treeNode; } /** * 获取实例中的最大类 * @param datas 实例集 * @return 出现次数最多的类 */ public Object getLabel(ArrayList<Data> datas){ Map<Object, Integer> map = new HashMap<Object, Integer>(); Object label = null; int max = 0; for(Data data: datas){ if(map.containsKey(data.y)){ map.put(data.y, map.get(data.y) + 1); if(map.get(data.y) > max){ max = map.get(data.y); label = data.y; } }else { map.put(data.y, 1); } } return label; } /** * 计算信息增益(率)的最大值 * @param datas * @return 最大的信息增益值 */ public double getMaxInfoGain(ArrayList<Data> datas){ double max = 0; for(int i = 0; i < datas.get(0).x.size(); i++){ double temp = infoGain.getInfoGain(datas, i); if(temp > max) max = temp; } return max; } /**信息增益最大的特征*/ public int getMaxInfoGainFeature(ArrayList<Data> datas){ double max = 0; int feature = 0; for(int i = 0; i < datas.get(0).x.size(); i++){ double temp = infoGain.getInfoGain(datas, i); if(temp > max){ max = temp; feature = i; } } return feature; } /**判断是否只有一类*/ public boolean isSingle(ArrayList<Data> datas){ Set<Object> set = new HashSet<>(); for(Data data: datas) set.add(data.y); return set.size() == 1? true:false; } public static void main(String[] args) { ArrayList<Data> datas = new ArrayList<>(); FileIO fileIO = new FileIO(); DecisionTree decisionTree = new DecisionTree(); fileIO.setFileName(".//file//decision.tree.txt"); fileIO.FileRead("utf-8"); ArrayList<String> featureName = new ArrayList<>(); //获取文件的标头 for(String string: fileIO.fileList.get(0).split(" ")) featureName.add(string); for(int i = 1; i < fileIO.fileList.size(); i++){ datas.add(new Data(fileIO.fileList.get(i))); } TreeNode treeNode = new TreeNode(); treeNode = decisionTree.buildTree(datas, featureName); treeNode.printTree(); } }
运行情况:
输入文件 ".//file//decision.tree.txt" 内容为:
类型 年龄 有工作 有自己的房子 信贷情况
否 青年 否 否 一般
否 青年 否 否 好
是 青年 是 否 好
是 青年 是 是 一般
否 青年 否 否 一般
否 中年 否 否 一般
否 中年 否 否 好
是 中年 是 是 好
是 中年 否 是 非常好
是 中年 否 是 非常好
是 老年 否 是 非常好
是 老年 否 是 好
是 老年 是 否 好
是 老年 是 否 非常好
否 老年 否 否 一般
运行结果为:
当前特征为:有自己的房子
特征值: 是 类型: 是
当前特征为:有自己的房子
特征值: 否
当前特征为:有工作
特征值: 是 类型: 是
当前特征为:有工作
特征值: 否 类型: 否
对代码有兴趣的可以上本人的GitHub查看:https://github.com/JueFan/StatisticsLearningMethod/
里面也有具体的实例数据