文件读取流程:构造文件名队列--->读取与解码--->批处理
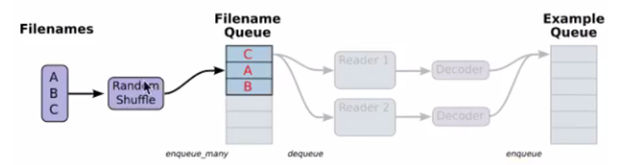
构造文件名队列:
需要读取文件的文件名放入文件名队列: tf.train.string_input_producer(string_tensor,shuffle=True) string_tensor:含有文件名+路径的一阶张量 num_epochs:过几篇数据,默认无限过数据 return 文件队列
读取与解码:
从队列中读取内容,并进行解码操作,阅读器默认每次只读取一个样本
读取文件内容:文本文件默认一次读取一行,图片一张,二进制一次指定字节数
tf.TextLinerReader:读取文本文件逗号分隔值(csv格式),默认按行读取,返回阅读器实例
tf.WholeFileReader:用于读取图片文件,返回阅读器实例
tf.FixedLengthRecordReader(record_bytes):二进制文件
tf.TFRecordReader:读取TFRecords文件
它们共同读取方法:reader.read(file_queue),并且都会返回一个Tensors元组(key,value);key文件名字,value一个样本
默认只会读取一个样本,tf.train.batch或tf.tain.shuffle_batch进行批处理操作。
内容解码:
tf.decode_csv:解码文本文件内容
tf.image.decode_jpeg(contents):将jpeg编码的图像解码为unint8,形状[h,w,channels]
tf.image.decode_png(contenst):将png编码的图像解码为unint8,形状[h,w,channels]
tf.decode_raw():解码二进制文件内容与tf.FixedLengthRecordReader搭配使用,读取unit8类型
如果之后需要转换指定类型则可以使用tf.cast()进行相应转换
批处理:
解码后,可以直接获取默认一个样本内容,要获得多个样本,需要加如到新的队列进行批处理 tf.train.batch(tensor,batch_size,num_threads=1,capacity=32,name=None) #tf.train.shuffle+batch tensors:可以张量的列表,批处理的内容放到列表当中 batch_size:从队列中读取的批处理大小 num_threads:进入队列的线程数 capcity:整数,队列中原属的最大数量 return:tensors
线程操作:
tf.train.QueueRunner() #创建队列队形 tf.train.start_queue_runners(sess=None,coord=None) # 启动他的运行队列操作的线程 tf.train.Coordinator() # 线程协调员,对线程进行管理和协调 request_stop():请求停止 should_stop():询问是否结束 join(threads=None,stop_grace_period_secs=120):回收线程
读取数据准备:
单个图片:[h,w,channel] 多个图片:[batch,h,w,channel] 图片的大小需要一致:tf.image.resize_images(images,size) #[batch,h,w,c],new_h,new_w 构造文件名队列---读取二进制数据闭关进行解码---处理图片形状即数据类型,批处理---开启会话线程运行 tf.transpose(depth_major,[1,2,0]).eval() # [c,h,w] 转换 [h,w,c]
从队列中读取内容,并进行解码操作,阅读器默认每次只读取一个样本
读取文件内容:文本文件默认一次读取一行,图片一张,二进制一次指定字节数
tf.TextLinerReader:读取文本文件逗号分隔值(csv格式),默认按行读取,返回阅读器实例
tf.WholeFileReader:用于读取图片文件,返回阅读器实例
tf.FixedLengthRecordReader(record_bytes):二进制文件
tf.TFRecordReader:读取TFRecords文件
它们共同读取方法:reader.read(file_queue),并且都会返回一个Tensors元组(key,value);key文件名字,value一个样本
默认只会读取一个样本,tf.train.batch或tf.tain.shuffle_batch进行批处理操作。
内容解码:
tf.decode_csv:解码文本文件内容
tf.image.decode_jpeg(contents):将jpeg编码的图像解码为unint8,形状[h,w,channels]
tf.image.decode_png(contenst):将png编码的图像解码为unint8,形状[h,w,channels]
tf.decode_raw():解码二进制文件内容与tf.FixedLengthRecordReader搭配使用,读取unit8类型
如果之后需要转换指定类型则可以使用tf.cast()进行相应转换