1.说明
Elasticsearch 是分布式的,但是对于我们开发者来说并未过多的参与其中,我们只需启动对应数量的节点,并给它们分配相同的 cluster.name 让它们归属于同⼀个集群,创建索引的 时候只需指定索引主分⽚数和 副分⽚数 即可,其他的都交给了 ES 内部⾃⼰去实现。
这和数据库的分布式和 同源的 solr 实现分布式都是有区别的,数据库要做集群分布式,⽐如 分库分表需要我们指定路由规则和数据同步策略等,包括读写分离,主从同步等,solr的分布 式也需依赖 zookeeper,但是 Elasticsearch 完全屏蔽了这些。
虽然Elasticsearch 天⽣就是分布式的,并且在设计时屏蔽了分布式的复杂性,但是我们还得知道它内部的原理。
2.写入文档
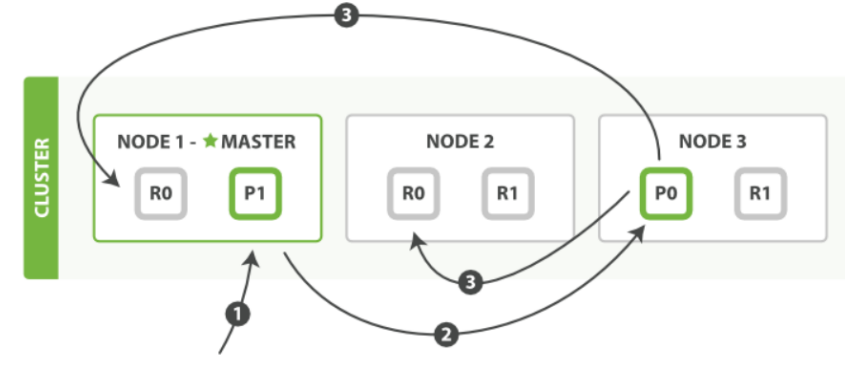
1、客户端向node-1发送新增⽂档请求。
2、节点通过⽂档的路由算法确定该⽂档属于主分⽚-P0。因为主分⽚-P0在node-3,所以请求会转 发到node-3。
3、⽂档在node-3的主分⽚-P0上新增,新增成功后,将请求转发到node-1和node-2对应的副分 ⽚-R0上。⼀旦所有的副分⽚都报告成功,node-3向node-1报告成功,node-1向客户端报告成 功。
3.读文档
1.客户端向node-1发送读取⽂档请求。
2.在处理读取请求时,node-1在每次请求的时候都会通过轮询所有的副本分⽚来达到负载均 衡。