关于shuffle的过程图。

一:概述shuffle
Shuffle是mapreduce的核心,链接map与reduce的中间过程。
Mapp负责过滤分发,而reduce则是归并整理,从mapp输出到reduce的输入的这个过程称为shuffle过程。
二:map端的shuffle
1.map结果的输出
map的处理结果首先存放在一个环形的缓冲区。
这个缓冲区的内存是100M,是map存放结果的地方。如果数据量较大,超过了一定的量(默认80M),将会发生溢写过程。
在mapred-site.xml中设置内存的大小
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
在mapred-site.xml中设置内存溢写的阈值
<property>
<name>mapreduce.task.io.sort.spill.percent</name>
<value>0.8</value>
</property>

2.溢写过程(这个过程是一个阶段,不是一个简单的写的过程)
溢写是系统在后台单独开一个线程去操办。
溢写过程包括:分区partitioner,排序sort,溢写spill to disk,合并merge。
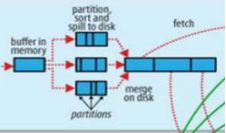
3.分区
分区分的是80%的内存。
因为reduce可能有不同的任务,所以会对80M的内存进行分区,将map的输出结果放入的对应的reduce分区中。
4.排序
默认是按照key排序。
当分区完成之后,对每一个分区的数据进行排序。
排序发生在数据到达80M的时候。(2017.12.24,刚刚想了一下,应该是这个时候)
5.溢写
排序之后,将内存的数据写入硬盘。留出内存方便map的新的输出结果。
6.合并
如果是第一次写入硬盘则不需要考虑合并问题,但是在大数据的情况下,前面已经存在大量的spill文件的时候,这时候需要将它们进行合并。
将各个分区合并之后,对每一个分区的数据再进行一次排序。(2017.12.24,这个比较重要,注意点是各个分区合并)
使用归并的方式进行合并,归并算法。
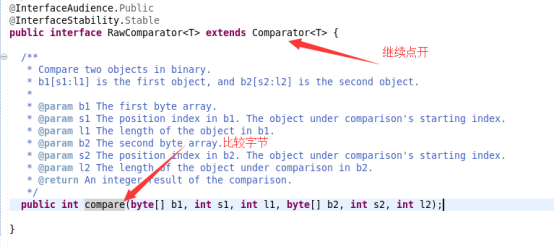
实现comparator比较器,进行比较。
形成一个文件。
三:reduce端的shuffle
1.步骤
对于reduce端的shuffle,和map端的shuffle步骤相同。但是有一个特别的步骤,分组。
2.复制
当reduce开启任务后,不断的在各个节点复制需要的数据。
3.合并(内含排序)
复制数据的时候,把可以存放进内存的就把数据存放在内存中,当达到一定的时候,启动merge,将数据写进硬盘。
如果map数据大于内存需要存放的限制,直接写入硬盘,当达到一定的数量后将其合并为一个文件。
这时候,reduce开启任务需要的数据在内存中和在硬盘中,最终形成一个全局文件。
4.分组
《hadoop,1》
《hadoop,1》
《yarn,1》
《hadoop,1》
《hdfs,1》
《yarn,1》
将相同的key放在一起,使用comparable完成比较。
结果为:
《hadoop,list(1,1,1)》
《yarn,list(1,1)》
《hdfs,list(1)》
四:关于Comparator的理解
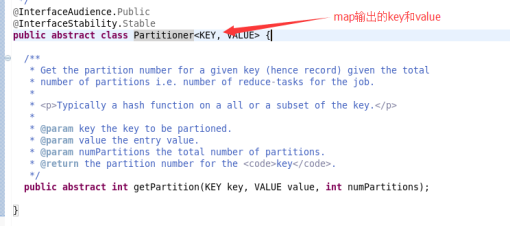
不管是排序还是分组,都需要自定义排序器comparable
Comparator类继承WritableComparator

而WritableComparator完成接口RawComparator
在RawComparator中:

五:shuffle处的优化
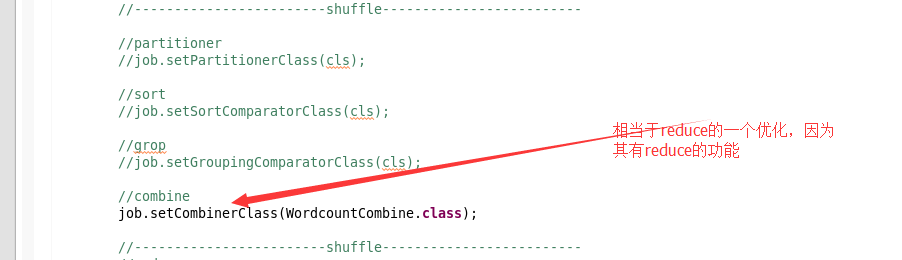
1.combine的优化
这是map段的reduce。
好处就是提前进行一次reduce,注意点是每个map进行一次reduce之后,数据量合并变小。
问题:是否还需要reduce?
回答:这个是map段的reduce,正真的reduce是许多map的一个汇总,所以是需要的。(2017.12.24,想法不知道对不对,希望以后进行仔细研究)
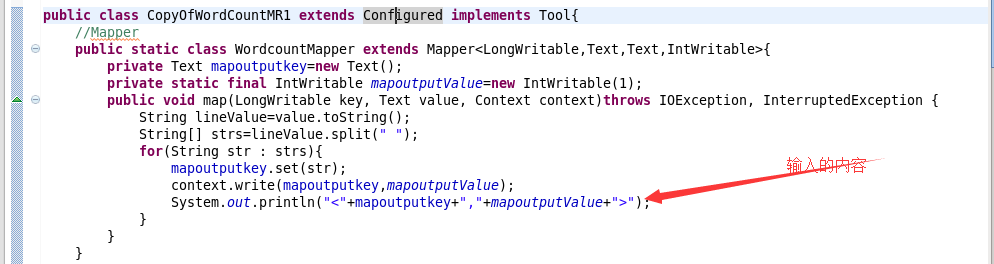
2.下面列举需要修改的程序

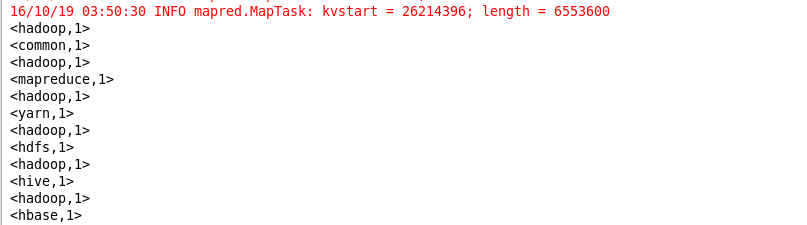
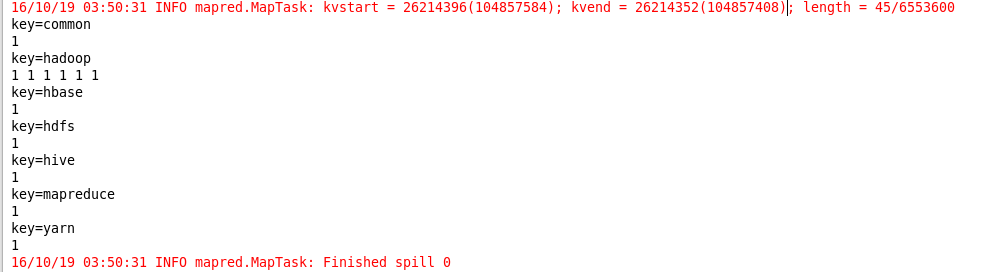
3.输出结果
4.关于压缩方面的优化
这个优化也属于map段的一个优化部分。
但是优化的方式是修改配置项。
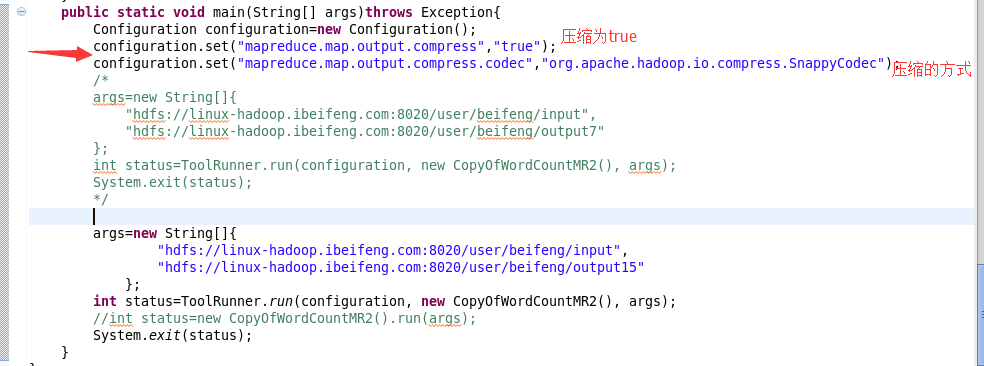
注意点:
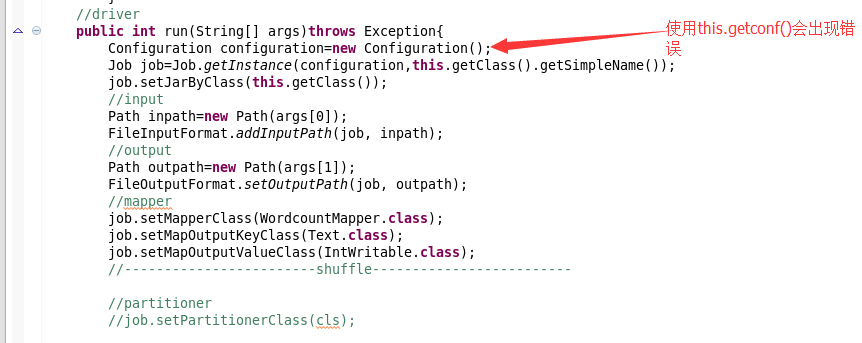
会出现的问题:

六:属于分区的一个思路
shuffle中程序:

说明:
这个根据reduce实际需求决定。
根据测试决定合理的reduce数目。
七:shuffle最终总结、
包括优化部分,可以将shuffle分为五个部分。
map端:分区
排序
合并combine
压缩
reduce端:分组
八:完整的程序
1 package com.senior.bigdata; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.conf.Configured; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.Mapper; 13 import org.apache.hadoop.mapreduce.Mapper.Context; 14 import org.apache.hadoop.mapreduce.Reducer; 15 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 import org.apache.hadoop.util.Tool; 18 import org.apache.hadoop.util.ToolRunner; 19 20 public class OptimizeOfWordCountMR extends Configured implements Tool{ 21 //Mapper 22 public static class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ 23 private Text mapoutputkey=new Text(); 24 private static final IntWritable mapoutputvalue=new IntWritable(1); 25 @Override 26 protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException { 27 String lineValue=value.toString(); 28 String[] strs=lineValue.split(" "); 29 for(String str:strs){ 30 mapoutputkey.set(str); 31 context.write(mapoutputkey, mapoutputvalue); 32 // System.out.println(mapoutputkey+"<---->"+mapoutputvalue); 33 } 34 } 35 36 } 37 38 //combiner 39 public static class WordCountCombiner extends Reducer<Text,IntWritable,Text,IntWritable>{ 40 private IntWritable outputvalue=new IntWritable(); 41 @Override 42 protected void reduce(Text text, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException { 43 int sum=0; 44 // System.out.println("key="+text); 45 for(IntWritable value:values){ 46 sum+=value.get(); 47 // System.out.print(value.get()); 48 } 49 // System.out.println(); 50 outputvalue.set(sum); 51 context.write(text, outputvalue); 52 } 53 54 } 55 56 //Reducer 57 public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ 58 private IntWritable outputvalue=new IntWritable(); 59 @Override 60 protected void reduce(Text text, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException { 61 int sum=0; 62 // System.out.println("key==="+text); 63 for(IntWritable value:values){ 64 // System.out.print(value.get()); 65 sum+=value.get(); 66 } 67 // System.out.println(); 68 outputvalue.set(sum); 69 context.write(text, outputvalue); 70 } 71 72 } 73 74 //Driver 75 public int run(String[] args)throws Exception{ 76 Configuration conf=this.getConf(); 77 Job job=Job.getInstance(conf,this.getClass().getSimpleName()); 78 job.setJarByClass(OptimizeOfWordCountMR.class); 79 //input 80 Path inpath=new Path(args[0]); 81 FileInputFormat.addInputPath(job, inpath); 82 83 //output 84 Path outpath=new Path(args[1]); 85 FileOutputFormat.setOutputPath(job, outpath); 86 87 //map 88 job.setMapperClass(WordCountMapper.class); 89 job.setMapOutputKeyClass(Text.class); 90 job.setMapOutputValueClass(IntWritable.class); 91 92 //shuffle 93 job.setCombinerClass(WordCountCombiner.class); //combiner 94 95 //reduce 96 job.setReducerClass(WordCountReducer.class); 97 job.setOutputKeyClass(Text.class); 98 job.setOutputValueClass(IntWritable.class); 99 100 //submit 101 boolean isSucess=job.waitForCompletion(true); 102 return isSucess?0:1; 103 } 104 105 //main 106 public static void main(String[] args)throws Exception{ 107 Configuration conf=new Configuration(); 108 //compress 109 conf.set("mapreduce.map.output.compress", "true"); 110 conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec"); 111 args=new String[]{ 112 "hdfs://linux-hadoop01.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/input", 113 "hdfs://linux-hadoop01.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/output5" 114 }; 115 int status=ToolRunner.run(new OptimizeOfWordCountMR(), args); 116 System.exit(status); 117 } 118 119 }