一:概述
1.UDF
用户自定义函数,用java实现自定义的需求
User Defined Function-----UDF。
2.UDF的类型
udf:一进一出
udaf:多进一出
udtf:一进多出
3.udf的实现步骤
继承UDF类
实现evaluate的方法
所有的方法都必须有返回值
推荐使用Text,LongWritable等类型
二:配置准备
1.导入新的包括hive的jar包
需要新的本地repository库。
然后在eclipse中选择更新。
在windows下新建maven工程。
2.修改pom.xml中的依赖,
主要是增加hive的依赖,当然hadoop依赖必须有。
1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 2 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 3 <modelVersion>4.0.0</modelVersion> 4 5 <groupId>com.cj.it</groupId> 6 <artifactId>hiveUdf</artifactId> 7 <version>0.0.1-SNAPSHOT</version> 8 <packaging>jar</packaging> 9 10 <name>hiveUdf</name> 11 <url>http://maven.apache.org</url> 12 13 <properties> 14 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 15 </properties> 16 17 <dependencies> 18 <dependency> 19 <groupId>org.apache.hadoop</groupId> 20 <artifactId>hadoop-client</artifactId> 21 <version>2.5.0</version> 22 </dependency> 23 <dependency> 24 <groupId>org.apache.hive</groupId> 25 <artifactId>hive-exec</artifactId> 26 <version>0.13.1</version> 27 </dependency> 28 <dependency> 29 <groupId>org.apache.hive</groupId> 30 <artifactId>hive-jdbc</artifactId> 31 <version>0.13.1</version> 32 </dependency> 33 <dependency> 34 <groupId>junit</groupId> 35 <artifactId>junit</artifactId> 36 <version>4.10</version> 37 <scope>test</scope> 38 </dependency> 39 </dependencies> 40 </project>
三:程序完成
1.需求
大小写的转换
0:表示转换为小写
1:表示转换为大写
默认是转换为小写
2.程序讲解
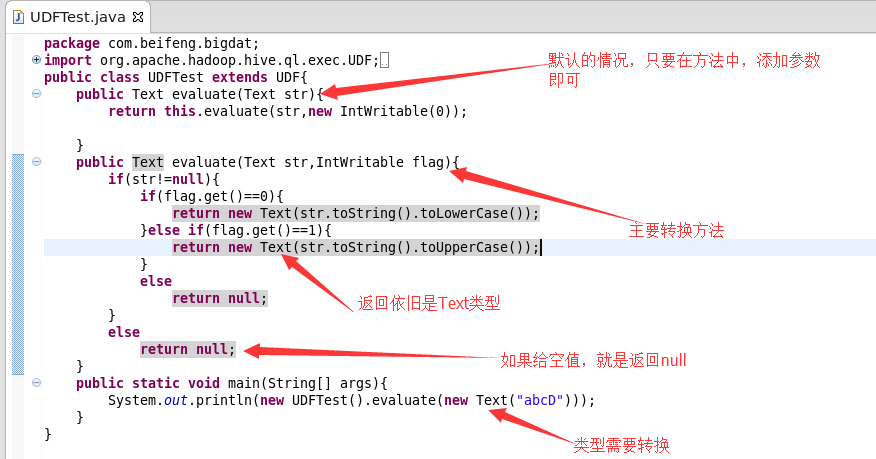
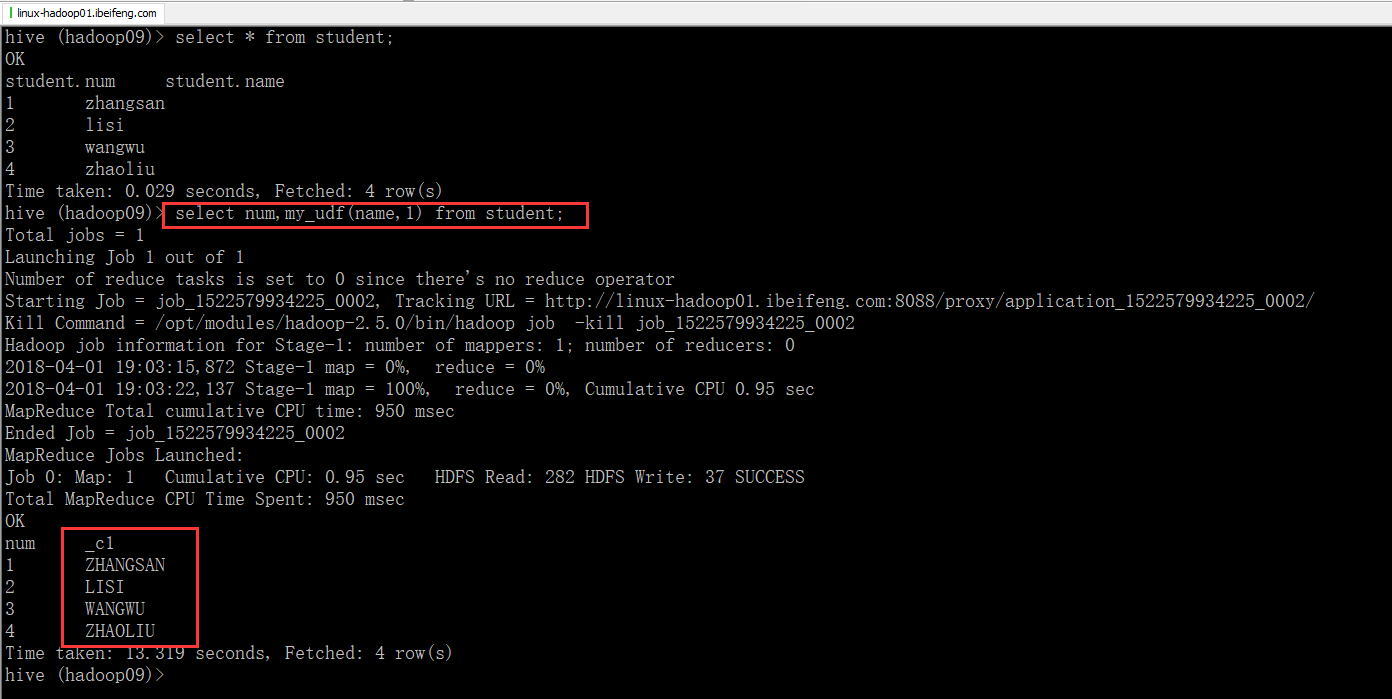
3.源代码
1 package com.cj.it.hiveUdf; 2 3 import org.apache.hadoop.hive.ql.exec.UDF; 4 import org.apache.hadoop.io.IntWritable; 5 import org.apache.hadoop.io.Text; 6 7 public class UdfTest extends UDF { 8 public Text evaluate(Text str) { 9 return evaluate(str, new IntWritable(0)); 10 } 11 12 public Text evaluate(Text str, IntWritable flag) { 13 if (str != null) { 14 if (flag.get() == 0) { 15 return new Text(str.toString().toLowerCase()); 16 } 17 if (flag.get() == 1) { 18 return new Text(str.toString().toUpperCase()); 19 } 20 return null; 21 } 22 return null; 23 } 24 25 public static void main(String[] args) { 26 System.out.println(new UdfTest().evaluate(new Text("asssf"), new IntWritable(1))); 27 } 28 }
4.运行效果

四:导出
1.Export
2.jar
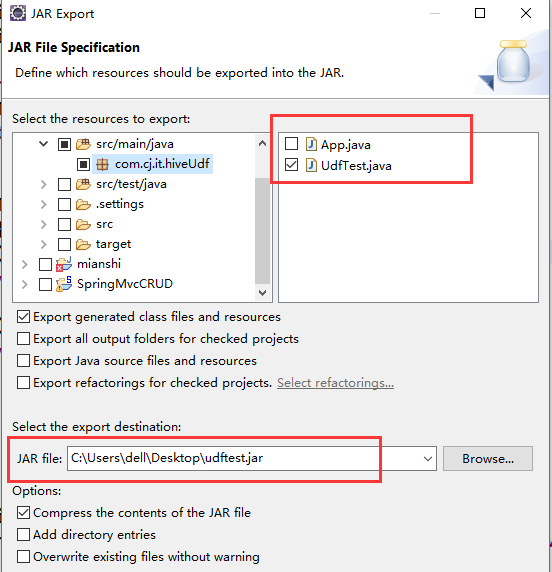
五:上传到hive
1.先上传到datas目录下
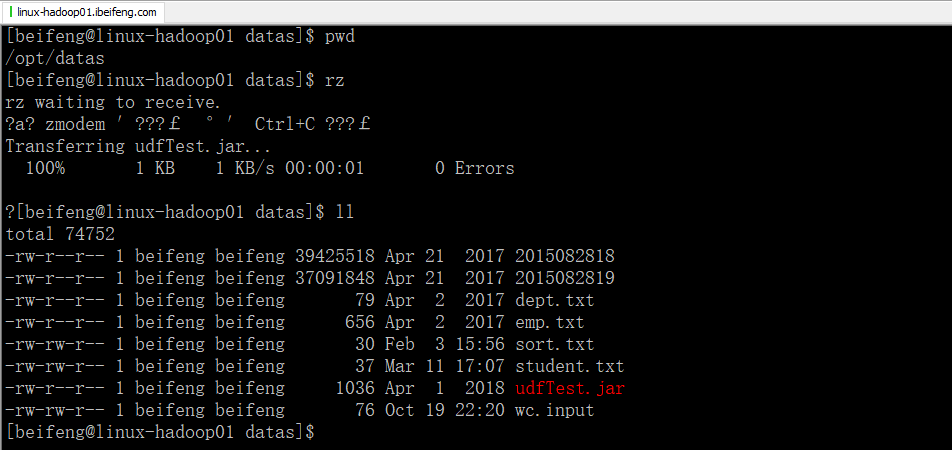
2.启动hadoop
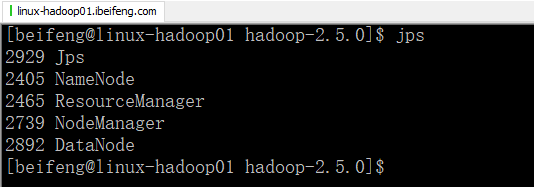
3.启动hive
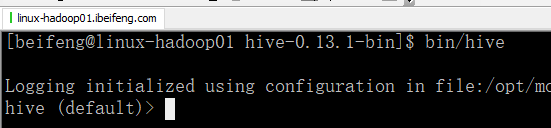
4.关联jarbao
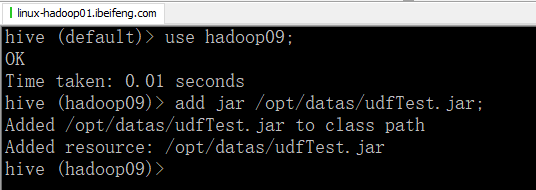
5.创建方法

6.使用