一:由HDFS将数据直接导入到HBase中
1.生成TSV文件
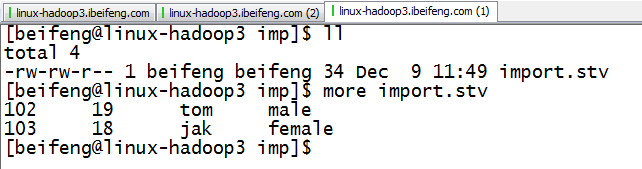
2.内容

3.上传到HDFS

4.运行
export HBASE_HOME=/etc/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`
export HADOOP_HOME=/etc/opt/modules/hadoop-2.5.0
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb1 /imp/import.tsv
重要的是:
)HBASE_ROW_KEY
)info:name,等都要和import.tsv相对应
)目录是HDFS的目录
)表名是将要书写进去的表名
5.结果

二:将数据转换为HFile
1.将数据转为HFile
hbase-0.98.6-hadoop2]$ $HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.bulk.output=/impout -Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
其中:nstest1:tb2的作用是按照这个表的格式进行转换HFile
/impout 是HFile的路径。

2.将HFile保存进HBase
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar completebulkload /impout nstest1:tb2
3.结果
HDFS中的HFile数据不再存在

HBase的结果

三:自定义分隔符
1.新定义文件

2.删除以前的文件,再重新上传文件
3.运行
$HADOOP_HOME/bin/yarn jar lib/hbase-server-0.98.6-hadoop2.jar importtsv -Dimporttsv.separator=,
-Dimporttsv.columns=HBASE_ROW_KEY,info:age,info:name,info:sex nstest1:tb2 /imp/import.tsv
3.结果
