一:介绍
1.介绍standalone
Standalone模式是Spark自身管理资源的一个模式,类似Yarn
Yarn的结构:
ResourceManager: 负责集群资源的管理
NodeManager:负责当前机器的资源管理
CPU&内存
Spark的Standalone的结构:
Master: 负责集群资源管理
Worker: 负责当前机器的资源管理
CPU&内存
二:搭建
1.在local得基础上搭建standalone
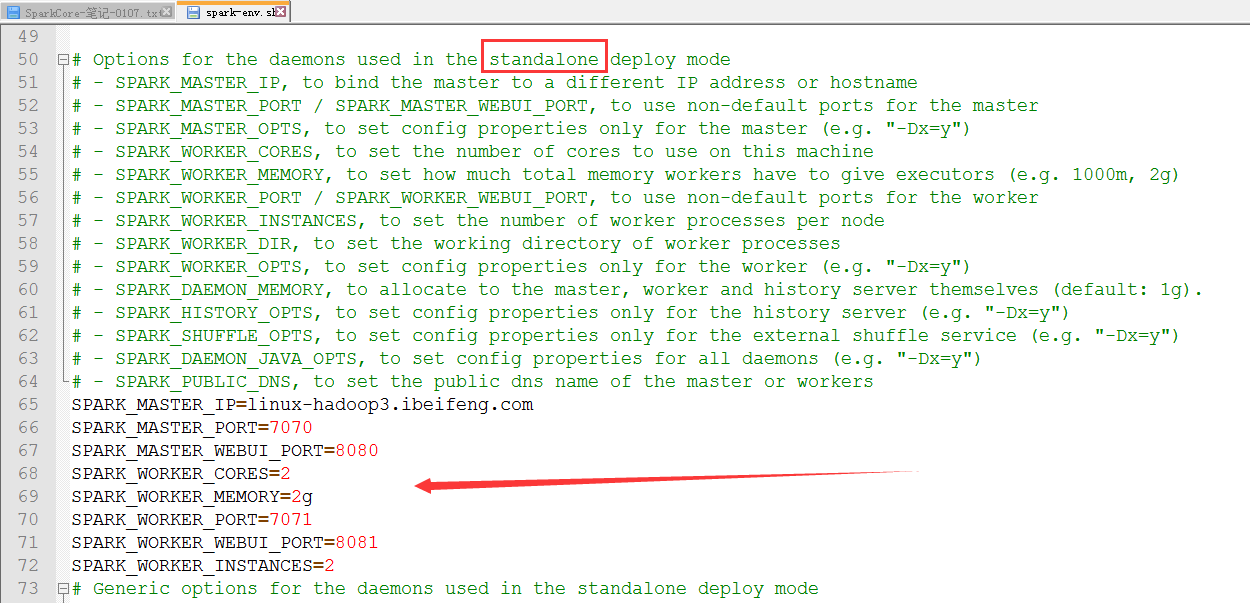
2.修改env.sh
SPARK_WORKER_CORES=3 一个executor分配的cpu数量
SPARK_WORKER_INSTANCES=2 一个work节点允许同时存在的executor的数量
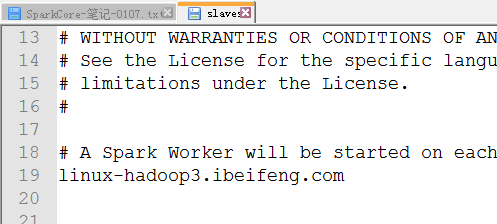
3.修改slave
4.启动
先启动HDFS
在在spark根目录下,sbin/start-all.sh
注意点:
可以单独启动master与slaves。
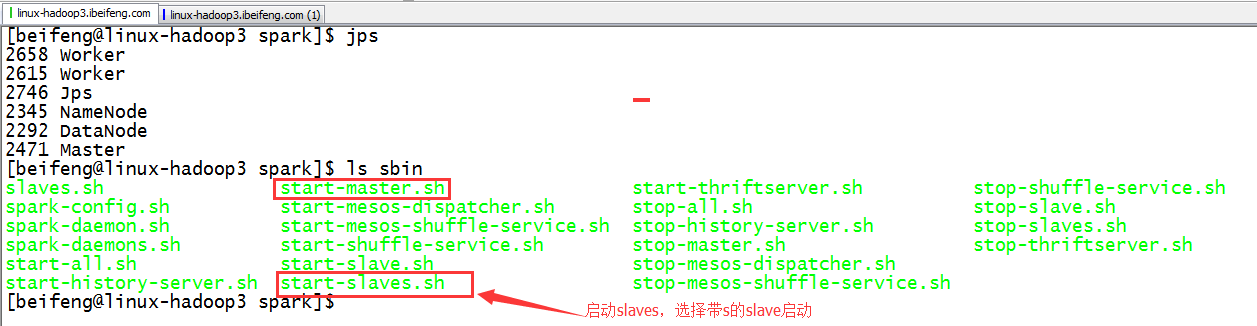
如下(补充):
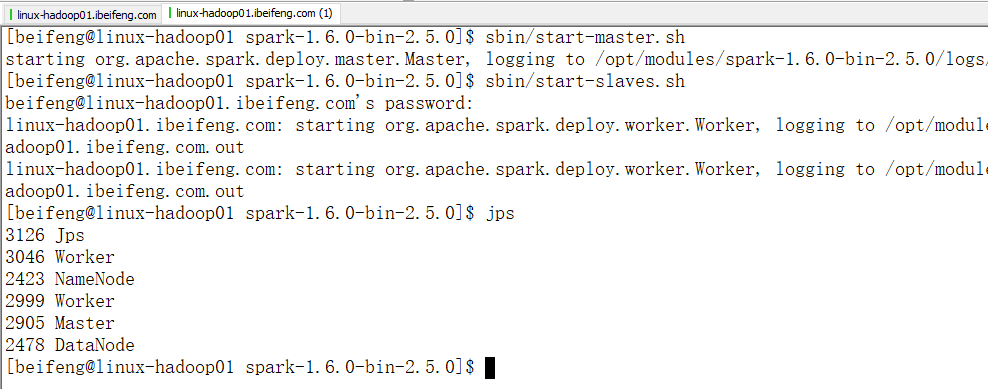
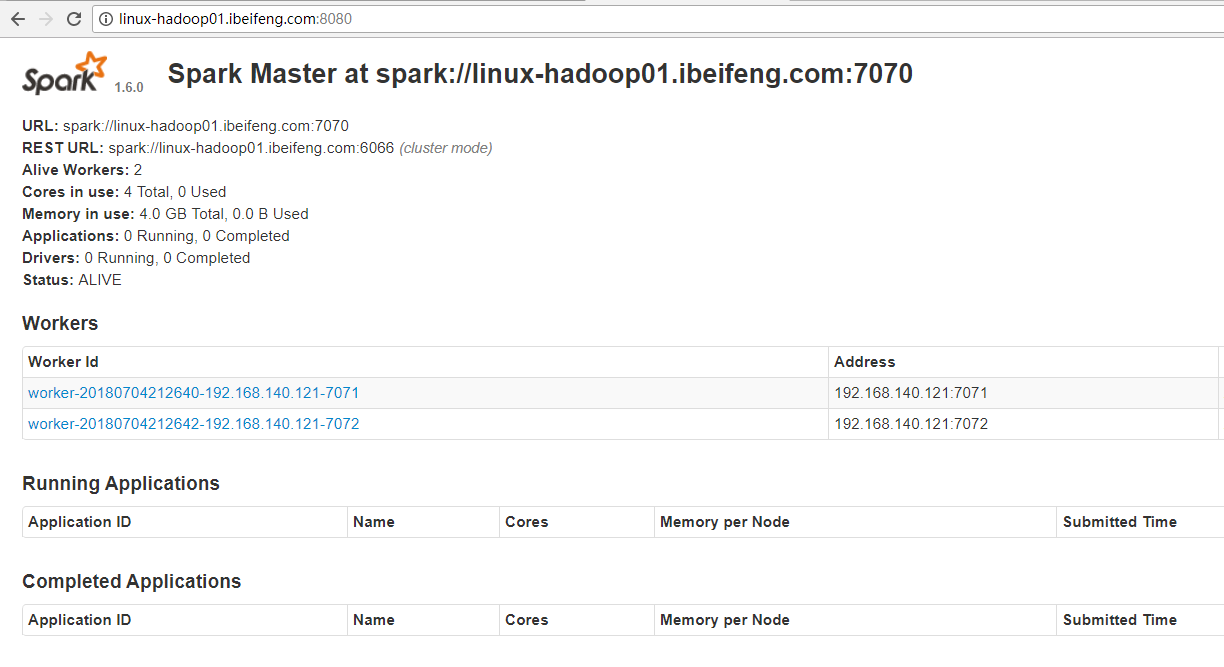
5.网页效果(standalone的master的UI网页:8080)
只要启动standalone模式,这个界面就是有效的。
在applications的运行或者完成处没有任务,所以没有什么程序。
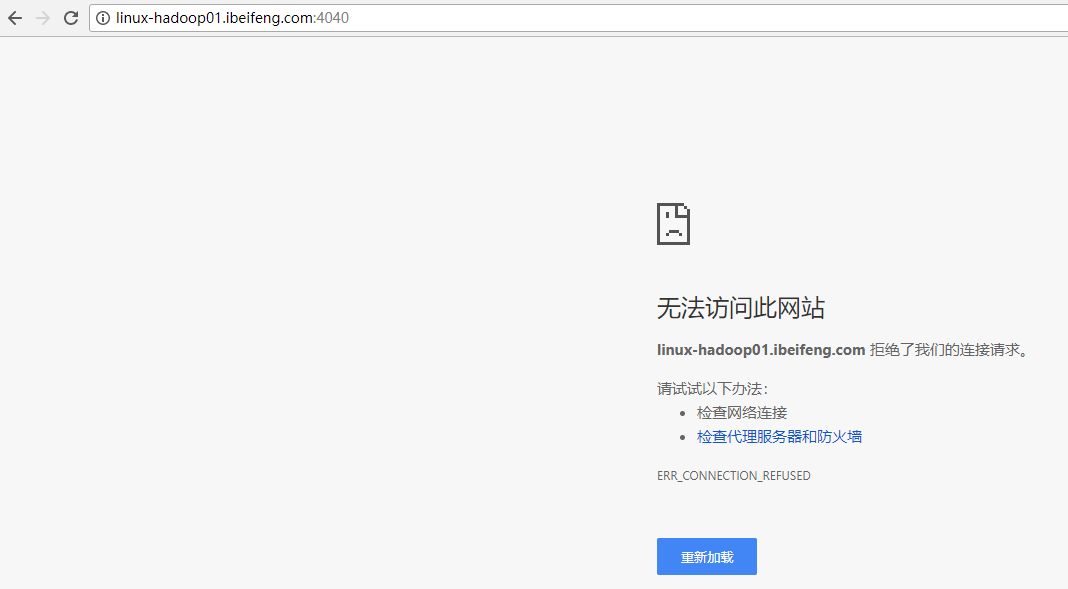
但是SparkUI 4040界面是进不去的,这个4040在shell的时候才能打开。
三:测试
1.测试
启动spark-shell,并配置master地址。
bin/spark-shell --master spark://linux-hadoop3.ibeifeng.com:7070
2.网页效果
多出一个运行的applications。

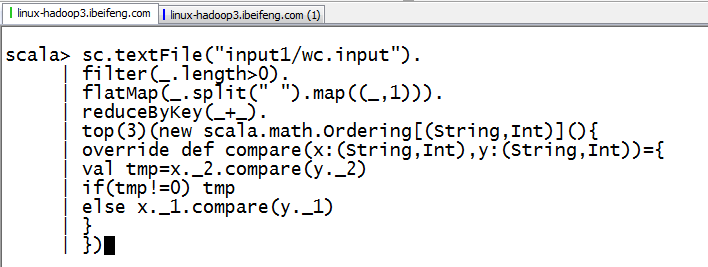
3.使用程序检测
然后输入wordcount的程序
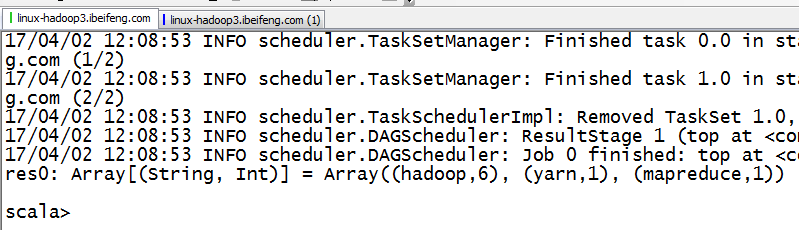
4.shell中的结果
5.网页效果
8080端口:
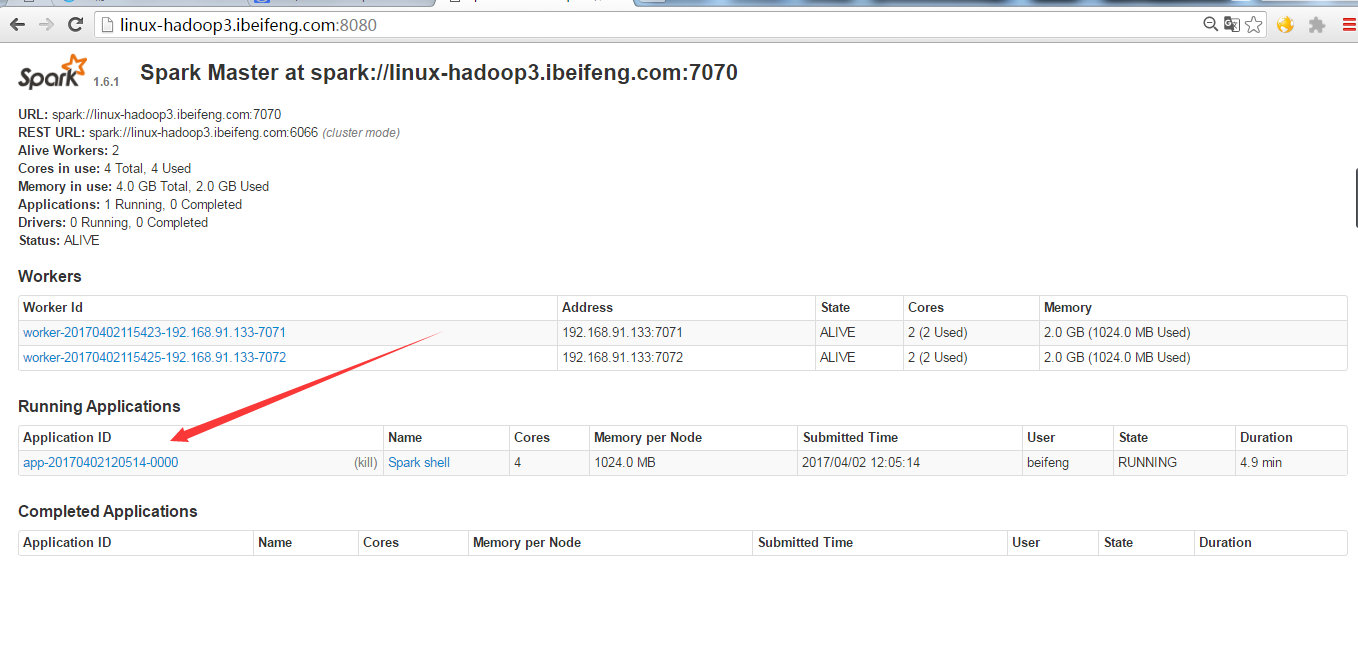
单击8080端口中的这个application ID。
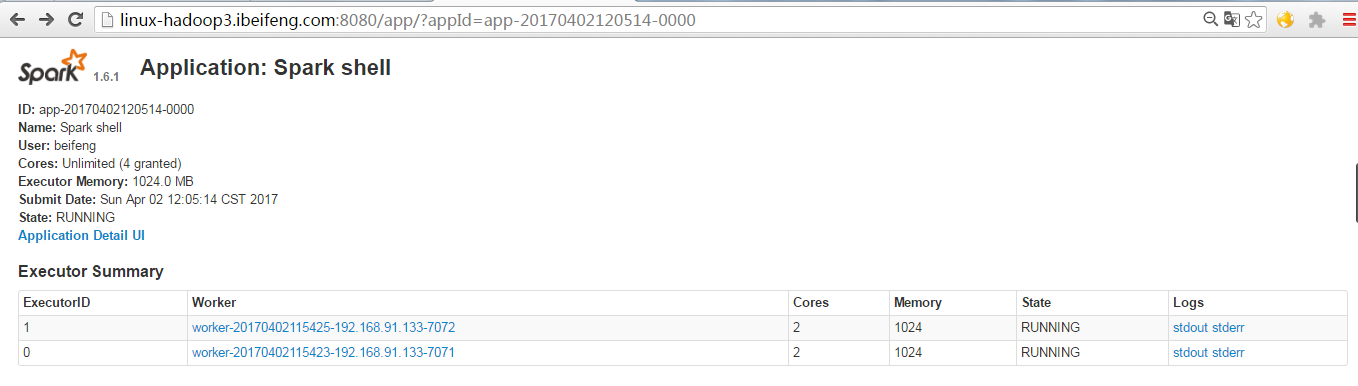
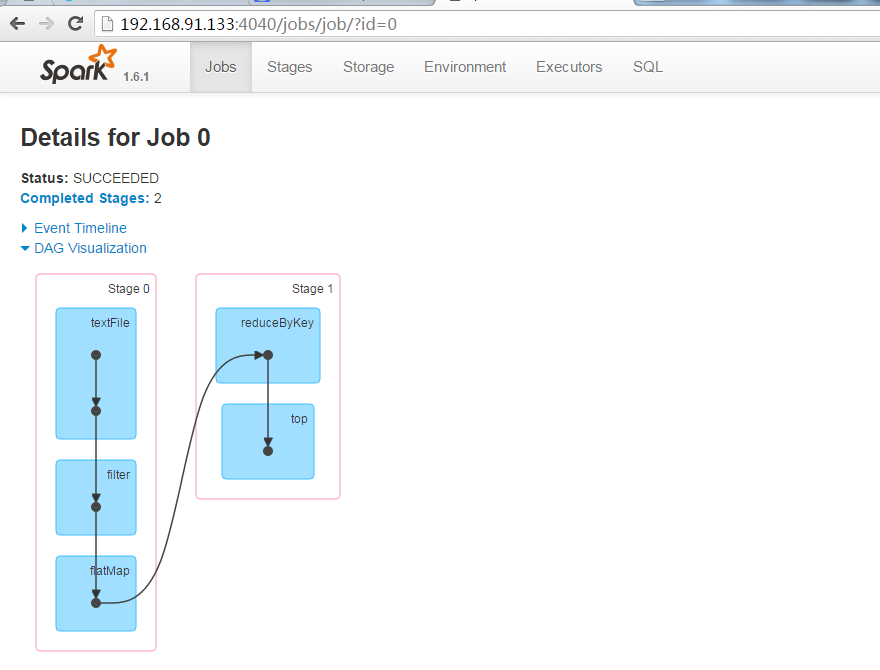
单击8080端口中的spark shell后,将会进入4040端口,进入sparkUI界面。
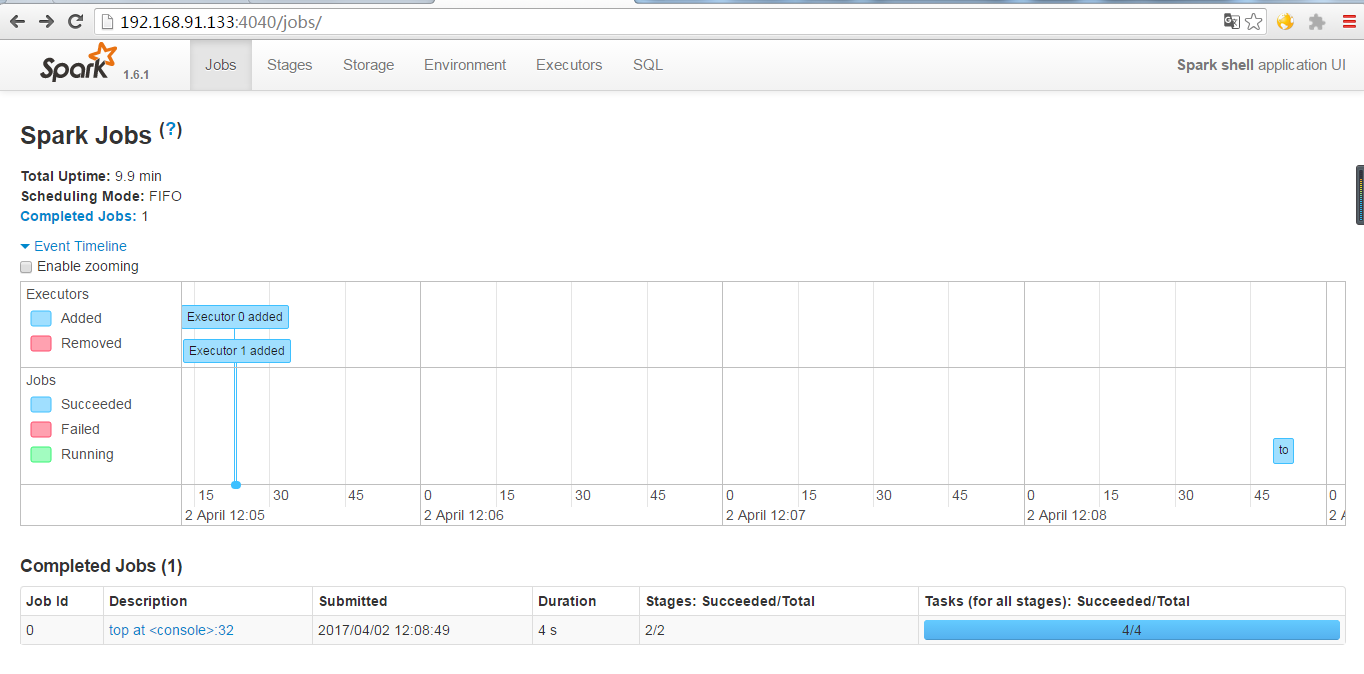
这时候可以继续单击Completed Jobs,可以看到job的DAG图。