一:介绍
1.在spark编译时支持hive

2.默认的db
当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库。

二:具体集成
1.将hive的配合文件hive-site.xml添加到spark应用的classpath中(相当于拷贝)
将hive-site.xml拷贝到${SPARK_HOME}/conf下。
下面使用软连接:

2.第二步集成
根据hive的配置参数hive.metastore.uris的情况,采用不同的集成方式
分别:
1. hive.metastore.uris没有给定配置值,为空(默认情况)
SparkSQL通过hive配置的javax.jdo.option.XXX相关配置值直接连接metastore数据库直接获取hive表元数据
但是,需要将连接数据库的驱动添加到Spark应用的classpath中
2. hive.metastore.uris给定了具体的参数值
SparkSQL通过连接hive提供的metastore服务来获取hive表的元数据
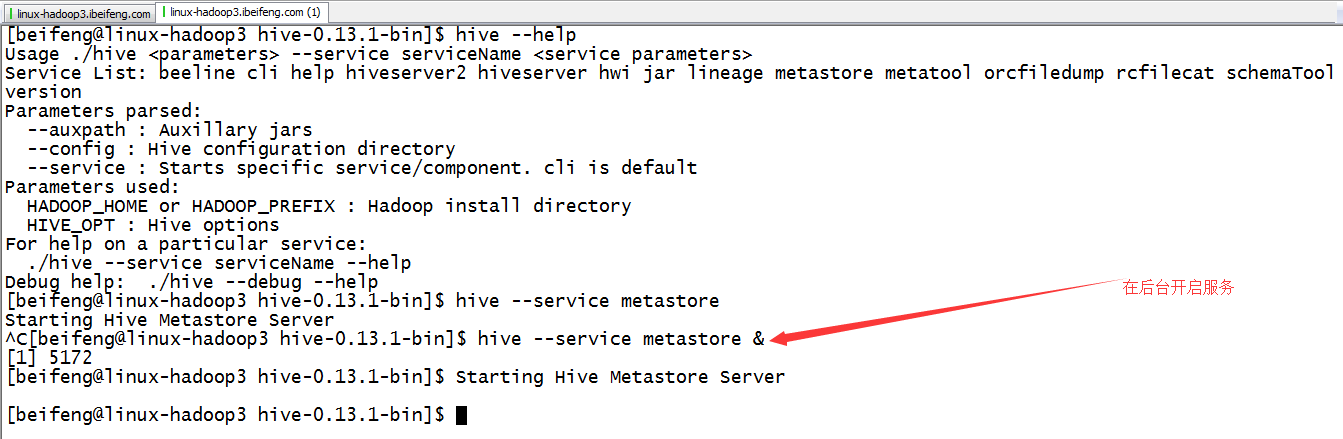
直接启动hive的metastore服务即可完成SparkSQL和Hive的集成
$ hive --service metastore &
3.使用hive-site.xml配置的方式
配置hive.metastore.uris的方式。

4.启动hive service metastore服务
如果没有配置全局hive,就使用bin/hive --service metastore &
三:测试
1.spark-sql
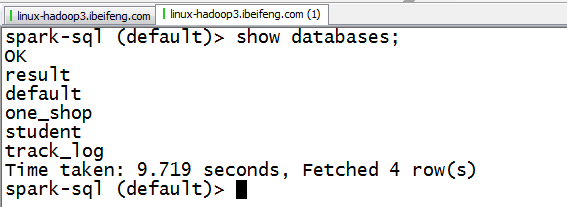
2.使用
四:特殊点(其他在hive中可以使用的sql,在spark-sql中都可以使用)
1.cache
cache是立即执行的,然后使用下面的可以懒加载。
uncache是立即执行的。

五:使用spark-shell
1.启动
2.使用
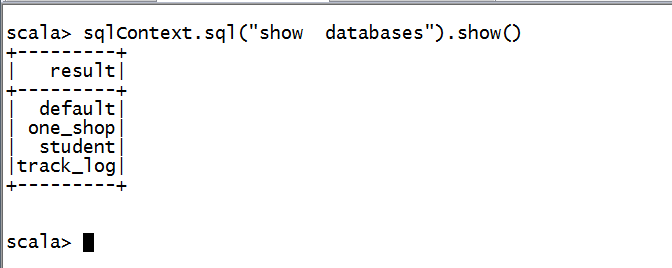
可以使用sqlContext . ,然后使用Tab进行补全。
show默认显示20行。
六:补充说明:Spark应用程序第三方jar文件依赖解决方案
1. 将第三方jar文件打包到最终形成的spark应用程序jar文件中
这种使用的场景是,第三方的jar包不是很大的情况。
2. 使用spark-submit提交命令的参数: --jars
这个使用的场景:使用spark-submit命令的机器上存在对应的jar文件,而且jar包不是太多
至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
方式:
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar:这样就不再需要配置hive.metastore.uris参数配置。
使用“,”分隔多个jar。
3. 使用spark-submit提交命令的参数: --packages
这个场景是:如果找不到jar会自动下载,也可以自己设定源。
作用:
--packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories.
The format for the coordinates should be groupId:artifactId:version. 这一个说明是spark-submit后的package参数的说明。
方式:
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
下载路径:
# 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中,即是home/beifeng/.ivy/jars
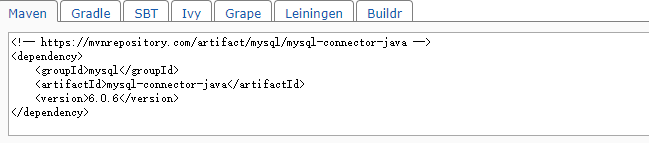
根据上面的maven来写格式。
4.更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
使用场景:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
做法:
-4.1 创建一个保存第三方jar文件的文件夹:
$ mkdir external_jars
-4.2 修改Spark配置信息
$ vim conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
-4.3 将依赖的jar文件copy到新建的文件夹中
$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
-4.4 测试
$ bin/spark-shell
scala> sqlContext.sql("select * from common.emp").show
备注:
如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)