推荐网址:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
1.简介
python开发的一个快速,高层次的屏幕抓去和web抓取框架,用于抓取web站点并从网页中提取结构化的数据。
是一个框架,可以根据需要进行修改。
提供了多种类型爬虫的基类,如BaseSpider,sitemap爬虫等。
2.框架

3.Scrapy的运行流程
引擎从调度器中取出一个链接用于接下来的抓取
引擎把url封装成一个请求传给下载器
下载器把资源下载下来,并封装成应答包
爬虫解析response
解析出实体Item,则交给实体管道进行进一步的处理
解析出的是链接,则把url交给调度器等待抓取。
二:安装
1.第一步安装lxml
lxml是一个非常有用的python库,可以灵活高校的解析xml,与bs,requests相结合,是编写爬虫的标准姿势。
2.第二步安装zope.interface
python支持多继承,但是不支持接口,zope.interface是其三方的接口实现库,在twisted中有大量的使用
3.第三步安装twisted
twisted是python实现的基于事件驱动的网络引擎框架。
支持很多框架,包括UDP,TCP,TLS和其他应用层协议(http,smtp,nntm,irc,xmpp等)
4.第四步安装pyOpenSSL
生成网络安全需要的CA和证书
5.第五步pywin32
pywin32是一个python库,为python访问windows API的扩展,提供了齐全的windows常量,接口,线程以及com机制等
下载地址:
https://sourceforge.net/projects/pywin32/files/pywin32/

双击安装

6.安装Scrapy
scrapy不同简单的单线爬虫,采用scrapy框架写python会生成许多的文件,这一件类似java里的web框架,许多工作可以通过配置文件来生成。
pip install scrapy
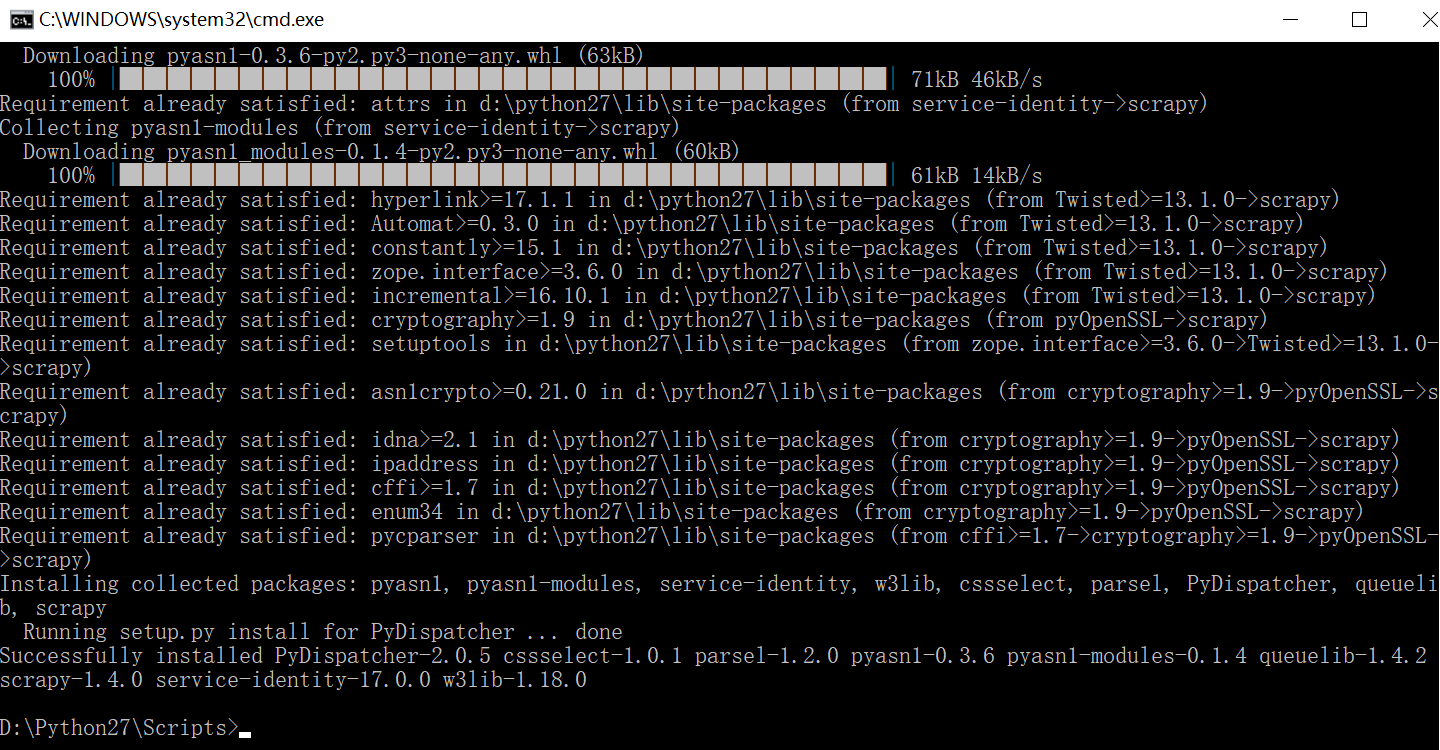
三:生成项目
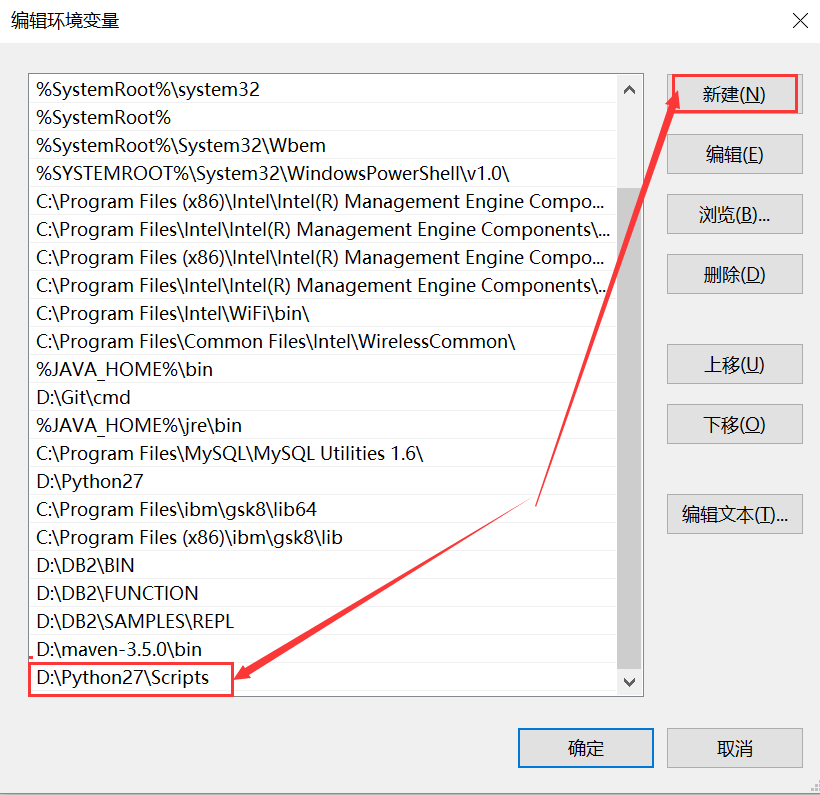
1.添加系统变量
使得scrapy.exe可以被访问到。
2.找到要生成项目的目录
3.从cmd中进入这个目录
4.在这里执行语句
scrapy startproject test2
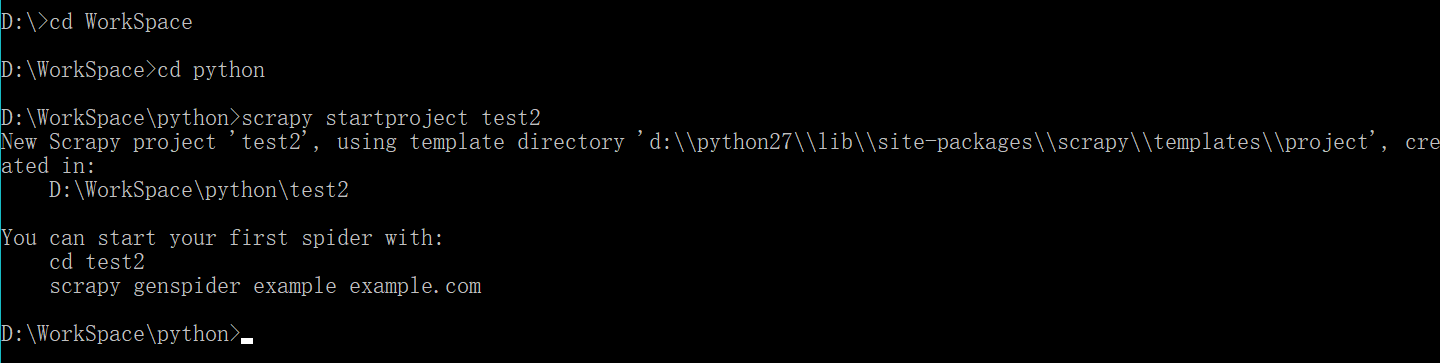
5.如图

四:制作爬虫
1.完成爬虫的流程
新建项目
明确目标
制作爬虫
存储内容
2.新建项目的目录结构
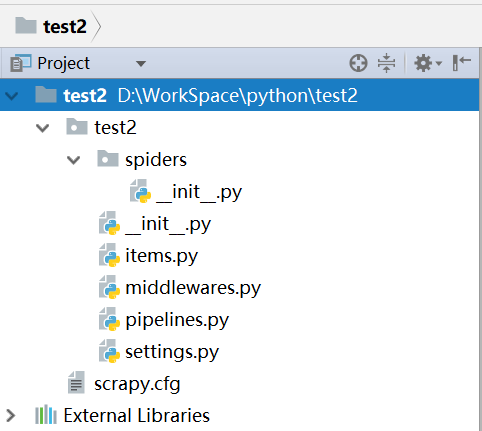
3.解释文件的作用
scrapy.cfg:项目的配置文件
test2/:项目中的python模块,将会从这里引用代码
items.py:项目中items文件用来存放抓取内容容器的文件
pipelines.py:负责处理爬虫从网页中抽取的实体,持久化实体,验证实体的有效性,清除不需要的信息
settings.py:项目的设置文件
spiders:爬虫的目录
4.定义Item
是用来保存爬取到的数据的容器,
创建一个scrapy.Item类,并定义类型为scrapy.Field类属性来定义一个Item。
将爬取的内容与Field()定义的属性对应。
程序:
1 # -*- coding: utf-8 -*- 2 from scrapy import Item,Field 3 4 class Test2Item(Item): 5 #电影名 6 title=Field() 7 #评分 8 start=Field() 9 #评分人数 10 critical=Field() 11 #短评 12 quote=Field()
5.编写Spiders
创建继承了scrapy.Spider的子类,并定义以下三个属性:
name:用于区别spider
start_urls:包含了spider在启动时进行爬取的url列表
parse():是spider的一个方法,每个初始url完成下载后生成的response对象将会作为唯一的参数传递给该函数,该方法负责解析返回的数据,提取数据以及需要进一步处理的url的request对象。
程序:
1 # -*- coding: utf-8 -*- 2 #下面三行解决的是编码问题。python3不会出现 3 import sys 4 reload(sys) 5 sys.setdefaultencoding('utf-8') 6 7 from scrapy.spiders import CrawlSpider 8 from scrapy.http import Request 9 from scrapy.selector import Selector 10 from test2.items import Test2Item 11 import re 12 13 #继承scrapy.spiders 14 class Doban(CrawlSpider): 15 name = "douban" 16 start_urls=['http://movie.douban.com/top250'] 17 url='http://movie.douban.com/top250' 18 def parse(self, response): 19 item=Test2Item() 20 selector=Selector(response) 21 Movies=selector.xpath('//div[@class="info"]') 22 for eachMovie in Movies: 23 #获取各个字段 24 fullTitle=eachMovie.xpath('div[@class="hd"]/a/span[@class="title"][1]/text()').extract() 25 26 start=eachMovie.xpath('div[@class="bd"]/div/span[@class="rating_num"]/text()').extract() 27 28 criticalStr=eachMovie.xpath('div[@class="bd"]/div/span[4]/text()').extract()[0] 29 critical= filter(str.isdigit,str(criticalStr)) 30 31 quote=eachMovie.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract() 32 33 if quote: 34 quote=quote[0] 35 else: 36 quote='' 37 38 #赋值 39 item['title']=fullTitle 40 item['start']=start 41 item['critical']=critical 42 item['quote']=quote 43 44 #提交 45 yield item 46 nextLink=selector.xpath('//span[@class="next"]/link/@href').extract() 47 if nextLink: 48 nextLink=nextLink[0] 49 print nextLink 50 yield Request(self.url+nextLink,callback=self.parse) 51 return
6.修改settings.py
1 USER_AGENT ='Mozilla/5.0 (Macintosh:Intel Mac OS X 10_8_3)' 2 'AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5' 3 4 FEED_URI=u'file:///D:/WorkSpace/python/test2/doban.csv' 5 FEED_FORMAT='CSV'
7.添加主函数运行
1 # -*- coding: utf-8 -*- 2 from scrapy import cmdline 3 cmdline.execute("scrapy crawl douban".split())
8.运行结果
